רגרסיה מרובה: מה משתנה כשמוסיפים מנבא

יום אחרי הרגרסיה הלינארית. הראית למנחה את התוצאה: β = -1.19, R² = 0.63. הוא הינהן. אחר כך אמר: "טוב. עכשיו תוסיפי גם את עומס העבודה הסובייקטיבי, נראה מה קורה."
ועצרת. כי המודל שלמדת קודם היה משוואה אחת עם משתנה מסביר אחד. עכשיו צריך להוסיף עוד אחד, ולא ברור מה זה אומר.
אותו מדגם, משתנה נוסף
אותן 40 מורות מהמאמר הקודם. אותו ציון שחיקה (0 עד 100), אותו ותק בהוראה (1 עד 30 שנים). עכשיו את מצרפת משתנה שלישי: ציון עומס סובייקטיבי בסולם 1 עד 7, ממוצע של פריטים בשאלון שמילאו.
שתי שאלות:
- האם עומס קשור לשחיקה בנפרד מהוותק?
- כשמחזיקים את הוותק קבוע, מה הקשר של עומס עם שחיקה?
על זה בדיוק רגרסיה מרובה עונה.
המשוואה החדשה
burnout = a + β₁ · years + β₂ · workload
שני β-ים במקום אחד. כל אחד מהם הוא הקשר החלקי בין המשתנה הזה ל-Y, כשמחזיקים את האחר קבוע. כאן שווה להתעכב רגע.
ברגרסיה הפשוטה שראינו קודם, β(years) = -1.19 פירושו "כל הפרש של שנה בוותק קשור לירידה ממוצעת של 1.19 נקודות בציון השחיקה הצפוי". נקודה.
ברגרסיה מרובה, אותו β(years) פירושו "כל שנה נוספת של ותק קשורה לירידה של X נקודות בציון השחיקה, אצל מורות עם רמת עומס זהה". משווים תפוחים לתפוחים. מורה עם ותק 10 ועומס 5, לעומת מורה עם ותק 11 ועומס 5.
הסייג הקטן הזה, "כשמחזיקים את האחר קבוע", משנה את כל הפרשנות. רגרסיה פשוטה מתארת את הקשר הדו-משתני בכלל המדגם. רגרסיה מרובה מתארת את הקשר החלקי, אחרי שניטרלת מבחינה לינארית את השפעת המשתנה האחר.
הפלט
הרצת. קיבלת:
| מקדם | ערך | SE | t(37) | p | 95% CI |
|---|---|---|---|---|---|
| חיתוך (a) | 40.18 | 2.71 | 14.82 | < .001 | [34.69, 45.68] |
| שיפוע β(שנים) | -1.32 | 0.07 | -20.04 | < .001 | [-1.46, -1.19] |
| שיפוע β(עומס) | 6.95 | 0.55 | 12.75 | < .001 | [5.84, 8.05] |
R² = 0.931, R²_adj = 0.927, F(2, 37) = 249.03, p < .001.
איך לקרוא כל β
β(years) = -1.32. "כל שנה נוספת של ותק קשורה לירידה של 1.32 נקודות בציון השחיקה, כשמחזיקים את העומס הסובייקטיבי קבוע."
שני דברים בולטים. הראשון: הערך השתנה. ברגרסיה הפשוטה קיבלת -1.19, ברגרסיה המרובה -1.32. זו לא טעות. שתי הרגרסיות מודדות דברים שונים: הפשוטה מתארת את הקשר הכולל של ותק עם שחיקה, המרובה מתארת את הקשר החלקי בלבד, אחרי התאמה לעומס. כששני המשתנים המסבירים מתואמים זה בזה (אפילו במידה מועטה, כאן r = 0.15), ה-β של אחד משתנה כשמוסיפים את השני. זה לא באג, זה בדיוק מה שהשליטה הסטטיסטית עושה.
השני: האפקט קצת חזק יותר במודל המרובה, לא חלש יותר. נראה מנוגד לאינטואיציה ("חשבתי שלהוסיף משתנים מחליש מקדמים?"). זה לא תמיד נכון. כיוון שעומס מתואם חיובית עם ותק וגם חיובית עם שחיקה, השמטה שלו מהמודל הפשוט הסתירה חלק מהקשר השלילי של ותק עם שחיקה. כשמוסיפים אותו מפורשות, ה-β של ותק נחשף במלואו. תופעה זו של מנבא מושמט שמטשטש מקדם של מנבא אחר נקראת לעתים suppression.
β(workload) = 6.95. "כל עלייה של נקודה בסולם העומס קשורה לעלייה של 6.95 נקודות בציון השחיקה, כשמחזיקים את הוותק קבוע." מעבר מ-3 ל-5 בסולם העומס (שתי נקודות) צפוי להוסיף בערך 14 נקודות לציון השחיקה. הבדל מעשי משמעותי, לא רעש סטטיסטי.
על החיתוך: a = 40.18 הוא הציון הצפוי כש-years = 0 וגם workload = 0. שני הערכים האלה מחוץ לטווח הנתונים (ותק 0 וגם עומס 0 שאינו בסולם 1-7). כמו ברגרסיה הפשוטה, החיתוך נחוץ לחישוב אבל לא מפרשים אותו מהותית.
R² קפץ מ-0.63 ל-0.93
המודל הקודם לכד 62.7% מהשונות בציוני השחיקה. המודל החדש לוכד 93.1%. תוספת של 30.4 נקודות אחוז.
(הערה חשובה: 30 נקודות אחוז זו קפיצה גדולה במיוחד, תוצאה של דוגמה שתוכננה להראות את המכניקה בבהירות. במחקרים אמיתיים בחינוך, הוספת מנבא טוב לרוב מוסיפה איפשהו בין 0.05 ל-0.15 ל-R². אם בעבודה שלך תקבלי תוספת כזאת, זה לא סימן שהמודל "חלש", אלא הסדר הרגיל.)
אבל לפני שמתלהבים, יש שתי בדיקות.
ראשונה: R² מתוקנן (adjusted R²). R² גולמי תמיד עולה כשמוסיפים משתנה, גם אם המשתנה רעש לבן. R²_adj מקזז את ההטיה לפי מספר המשתנים. אצלך, R²_adj עלה מ-0.617 ל-0.927. כלומר גם אחרי קנס על הוספת המנבא, ההתאמה במדגם השתפרה משמעותית.
שנייה: מבחן F-change. ההפרש ב-R² מתורגם לסטטיסטיקת F עם דרגות חופש מתאימות. ΔR² = 0.304, F-change(1, 37) = 162.45, p < .001. השיפור מובהק.
הערה מתמטית חשובה: כשמוסיפים מנבא יחיד, מבחן F-change שקול בדיוק למבחן t של אותו מנבא במודל המרובה. כאן, 12.7457² ≈ 162.45. שני המספרים אומרים אותו דבר. הערך הייחודי של F-change מופיע כשמכניסים בלוק של כמה מנבאים יחד, אז המבחן בודק את התרומה המשותפת שלהם בבת אחת. בדיווח של רגרסיה מרובה רגילה, מספיק לדווח את ה-t של כל מנבא בנפרד.
מקדמים מתוקננים: השוואה בין סקאלות
יש בעיה אחת בהשוואה ישירה בין β(years) = -1.32 ל-β(workload) = 6.95. הם בסקאלות שונות. ותק נמדד בשנים, עומס בנקודות סולם 1-7. אי אפשר להגיד "6.95 גדול מ-1.32 ולכן עומס חשוב יותר", כי שנה ונקודת סולם הן לא יחידות שוות.
הפתרון: מקדמים מתוקננים (standardized β). מסנדרטים את כל המשתנים ל-z-scores (ממוצע 0, ס"ת 1) ומריצים מחדש. אצלך:
β_std(years) = -0.88
β_std(workload) = +0.56
עכשיו אפשר להשוות. שניהם בסקאלה של סטיות תקן: "שינוי של ס"ת אחת ב-X קשור לשינוי של β_std סטיות תקן ב-Y, כשמחזיקים את שאר המנבאים קבועים". במונחים האלה, הוותק עדיין הקשר הגדול יותר, אבל העומס לא רחוק.
סייג: "גדול יותר" במונחים מתוקננים לא בהכרח "חשוב יותר". מהימנות המדידה, מולטיקולינאריות והקשר התיאורטי של השאלה משפיעים גם הם על מה שנחשב משמעותי. סטנדרטיזציה מאפשרת השוואה מתמטית, לא הכרעה תיאורטית.
(הערת SPSS: בפלט הרגרסיה, "Unstandardized Coefficients > B" זה ה-β הרגיל, "Standardized Coefficients > Beta" זה ה-β המתוקנן. השם המבלבל מתועד בכל ספר. שתי העמודות זו לצד זו.)
איך נראה "אחרי שניטרלנו את ותק"
יש כלי גרפי שעוזר להמחיש את הרעיון של "הקשר של עומס בנפרד מוותק". ה-added-variable plot.
הרעיון: לפני שמסתכלים על עומס מול שחיקה ישירות, מוציאים מכל אחד מהם את החלק שוותק מסביר. עושים שתי רגרסיות עזר. אחת מנבאת את burnout מ-years, השנייה מנבאת את workload מ-years. השארים של כל אחת הם החלק שלא נחזה על ידי הוותק. מציירים את שני סטי השארים זה מול זה, ומקבלים את הקשר החלקי של עומס עם שחיקה אחרי התאמה לינארית לוותק.
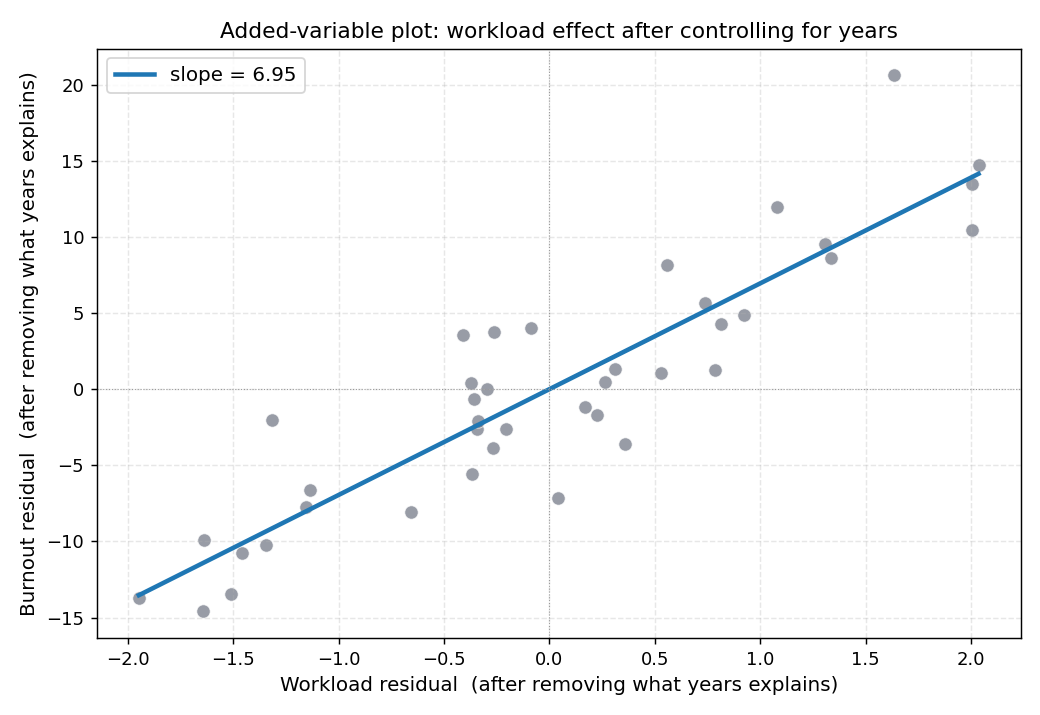
השיפוע של הקו בגרף שווה בדיוק ל-β(workload) = 6.95 במודל המרובה. זה לא צירוף מקרים. זאת הגדרה גרפית של מה ש-β במודל מרובה מודד.
מתי המשתנים מתואמים מדי זה בזה
סייג קצר. ככל שהמשתנים המסבירים מתואמים יותר זה בזה, ככה ה-β-ים שלהם הופכים פחות יציבים. במקרה הקיצוני, אם X₁ ו-X₂ מתואמים לחלוטין, אין דרך להפריד את הקשרים שלהם בכלל. השאלה "מה הקשר של עומס עם שחיקה כשמחזיקים את ותק קבוע" מאבדת משמעות אם עומס וותק זזים יחד כל הזמן.
הבדיקה הסטנדרטית: VIF (Variance Inflation Factor) לכל משתנה מסביר. כלל אצבע נפוץ: VIF < 5 בסדר, VIF > 10 בעייתי.
אצלך: VIF(years) = 1.02, VIF(workload) = 1.02. כמעט אחד, מה שאומר שהמשתנים כמעט לא מתואמים זה בזה. בלי בעיית מולטיקולינאריות. בדאטה הזה, ה"שליטה הסטטיסטית" של אחד על השני קוסמטית כמעט, וזה גם מסביר למה ה-β של ותק זז רק במעט בין הרגרסיה הפשוטה למרובה. כשהמתאם בין המנבאים גבוה יותר, ה-β-ים מושפעים יותר מהוספה או הסרה של כל אחד מהם, וגם VIF גדל.
איך לכתוב בפרק הממצאים
נערכה רגרסיה מרובה לחיזוי ציון השחיקה משני משתנים מסבירים: שנות ותק בהוראה ועומס עבודה סובייקטיבי (N = 40). המודל הכולל נמצא מובהק,
F(2, 37) = 249.03, p < .001, והסביר 93.1% מהשונות בציוני השחיקה (R² = .93, R²_adj = .93). שני המשתנים תרמו תרומה ייחודית מובהקת: שנות ותק (β = -1.32, SE = 0.07, t(37) = -20.04, p < .001, β_std = -.88) ועומס עבודה (β = 6.95, SE = 0.55, t(37) = 12.75, p < .001, β_std = .56). ערכי VIF היו נמוכים (≤ 1.03), ללא חשד למולטיקולינאריות.
שלושה משפטים. הצהרת המודל הכולל, פירוט שני המקדמים, בדיקת מולטיקולינאריות. אם המנחה שלך מבקש גם בדיקות של נורמליות שארים והומוסקדסטיות (וצריך), הוסיפי משפט שמתאר את הבדיקות שעשית בפועל ואת התוצאה, לא משפט גנרי שהן "נבדקו ונמצאו תקינות".
בקיצור
רגרסיה מרובה לוקחת את אותה לוגיקה של רגרסיה פשוטה (קו ישר, OLS, R²) ומרחיבה אותה ליותר ממשתנה מסביר אחד. כל β הופך לקשר החלקי בין המשתנה הזה ל-Y, כשמחזיקים את האחרים קבועים, וזה משנה את הפרשנות מיסודה.
כשמוסיפים משתנה למודל, מסתכלים שה-R²_adj עלה ושה-t של המנבא החדש מובהק. מוודאים שאין מולטיקולינאריות חמורה דרך VIF. וכל זה תקף רק אם הנחות הרגרסיה הבסיסיות עדיין סבירות, בדיוק כמו ברגרסיה הפשוטה.
השלב הבא, שעוד לא שאלת אבל המנחה ישאל: האם הקשר של עומס עם שחיקה תלוי בוותק? יכול להיות שעבור מורה צעירה עומס גבוה קשור לשחיקה הרבה, ואצל מורה ותיקה היא כבר למדה להתמודד והקשר חלש יותר. זאת שאלה של אינטראקציה בין משתנים, והיא בפוסט נפרד.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.