מבחן Shapiro-Wilk יצא מובהק: ועכשיו?

המנחה אמר לך, לפני שהוא בכלל הסכים להסתכל על מבחן ה-t-מזווג, לבדוק נורמליות. רצת ל-SPSS, ביקשת Shapiro-Wilk על ההפרשים (כי במבחן t-מזווג הנחת הנורמליות נוגעת להפרשים pre − post, לא לכל אחת משתי המדידות בנפרד), וקיבלת p = .049. ה-p-value קצת מתחת ל-.05. עברת את הסף. נורמליות נדחית. ועכשיו את עומדת מול השאלה הלא נעימה: זה אומר שאסור לי להריץ t-test?
התשובה הקצרה היא לא בהכרח. ה-Shapiro-Wilk הוא מצביע, לא פסק דין, ויש להבדל הזה בין השניים השלכות מעשיות גדולות על איך את כותבת את פרק התוצאות.
מה Shapiro-Wilk באמת בודק
השערת האפס של Shapiro-Wilk היא שהנתונים שלך נדגמו מהתפלגות נורמלית. ה-p-value הוא הסיכוי לקבל סטייה מנורמליות לפחות חזקה כמו זאת שנצפתה בנתונים, אם באמת הם נורמליים באוכלוסייה.
אם p < .05, את דוחה את ההשערה שההתפלגות נורמלית. אבל "דוחה" לא אומר "סוטה הרבה". בנתונים אמיתיים, במיוחד כשהמדד שלך הוא סולם בדיד וסגור (כמו ציון 0 עד 54 בסולם Maslach), נורמליות היא ממילא רק קירוב עבודה. השאלה האמיתית אינה "האם הנתונים נורמליים בדיוק", אלא "האם הקירוב טוב מספיק עבור ההסקה שאני רוצה לעשות". ה-p-value של Shapiro-Wilk לבד אינו עונה על זה. צורת ההתפלגות עצמה, גודל המדגם, וקיומם של חריגים, חשובים לפחות באותה מידה.
הדוגמה
נניח שאת חוקרת התערבות חדשה לצמצום שחיקה אצל מורות. דגמת 25 מורות, מדדת את ציון השחיקה שלהן בסולם Maslach לפני סדנה בת שישה שבועות, ושוב אחרי. אותן מורות, פעמיים. תכנון מזווג קלאסי.
הממוצעים: לפני M = 36.68, SD = 7.30, אחרי M = 30.16, SD = 9.31. ההפרשים האישיים (pre − post): M = 6.52, SD = 5.55, median = 5.00. עשרה מתוך 25 ההפרשים בטווח 2-7, חלקם קטנים יותר, וחמישה מהם בקצה הימני בין 13 ל-17. שתי מורות יצאו עם הפרש שלילי קל. ההפרשים האלה הם הנתונים שעליהם ה-t-מזווג עובד.
הרצת Shapiro-Wilk על 25 ההפרשים. התוצאה:
W = 0.92, p = .049
נורמליות נדחית. בקושי, אבל נדחית. עכשיו, לפני שאת בוחרת מבחן אחר, תסתכלי על ההתפלגות עצמה.
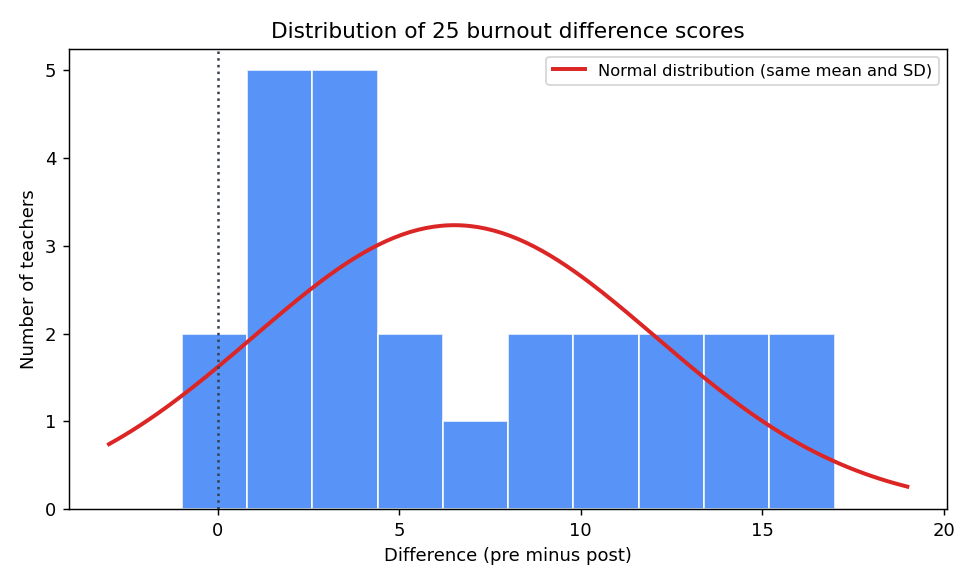
ההתפלגות לא נורמלית בצורה מובהקת, אבל גם לא קטסטרופלית. יש לה הטיה ימינה (skewness = 0.43), מתונה. רוב המורות התרכזו סביב שיפור קטן או בינוני, וכמה מהן הראו שיפור הרבה יותר חזק שיצר זנב ימני. זה מספיק כדי שהדחייה ב-Shapiro-Wilk תהיה גבולית, ולא הרבה יותר מזה.
למה ה-t-test לא בהכרח שבור
במבחן t-מזווג, ההסקה המדויקת מניחה שההפרשים באוכלוסייה נורמליים. בפועל, מבחן t-מזווג נחשב לעמיד אמפירית לסטיות מתונות מנורמליות, כל עוד אין נקודות בודדות שמטות את הממוצע ואת טעות התקן בצורה חזקה. משפט הגבול המרכזי הוא חלק מהאינטואיציה כאן, אבל הוא לא ערובה: הוא מדבר על הממוצע, לא על הסטטיסטיקה t עם טעות תקן מוערכת, ובמדגם של 25 הוא לא בלעדי.
לכן הערכת הסיכון צריכה לבוא גם מהנתונים. אצלנו, חמשת הערכים העליונים של ההפרשים הם 17, 16, 14, 14, 13: רצף יורד, בלי נקודה בודדת שמנותקת מהשאר ומושכת לבדה את הממוצע. ההיסטוגרמה תומכת באותה תמונה (הטיה מתונה ימינה, ללא חריג חזיתי). בנתונים האלה, השיפוט הסביר הוא שהמבחן ב-t לא צפוי להיות מוטה משמעותית. זה לא נכון לכל מדגם של 25 שיוצא לו p = .049 ב-Shapiro-Wilk.
הערה אחת לרקע: כל הדיון הזה מניח ש-25 המורות הן צפיות עצמאיות. אם הן מקובצות בבתי ספר ויש מתאם בתוך הקבוצות, גם נורמליות מושלמת לא תציל אותך. דיון בנורמליות לא תופס את הבעיה הזו.
בדיקת רגישות: שני מבחנים, שתי שאלות קרובות אך לא זהות
דרך מקובלת להעריך עד כמה הסטייה מנורמליות משפיעה על ההסקה היא להריץ גם את האלטרנטיבה הלא-פרמטרית, ולראות אם המסקנה מחזיקה. זה לא "מבחן שמאמת מבחן." זאת בדיקת רגישות בין שני ניתוחים שעונים על שאלות קרובות אך לא זהות.
חשוב להבין מה כל אחד בודק. ה-t-test בוחן את ממוצע ההפרשים: האם הוא רחוק מאפס. ה-Wilcoxon signed-rank הוא חלופה מבוססת דירוגים שבוחנת תזוזה כללית של מיקום התפלגות ההפרשים סביב אפס. הוא משתמש גם בסימן וגם בגודל היחסי, ולכן הוא לא מבחן רוב פשוט. אם השאלה היא ממש "האם יותר מורות השתפרו מאשר התדרדרו", המבחן הקרוב לזה הוא מבחן הסימנים, לא Wilcoxon. הפרשנות הקלאסית של Wilcoxon כמבחן חציון מסתמכת על הנחות סימטריה של התפלגות ההפרשים, ולא תמיד שווה את ה-t.
הערה לפני המספרים: בדוגמה הזו האפקט גדול מאוד ו-23 מתוך 25 ההפרשים חיוביים. במצב כזה, כמעט כל מבחן סביר יחזיר תוצאה מובהקת. ההסכמה בין שני המבחנים תהיה כמעט מובטחת, ולא תוכל להציג מקרה שבו התוצאות שלהם סותרות. לכן הדוגמה הזו היא מקרה נוח, לא מקרה מאתגר. הלקח שהיא מלמדת הוא איך לדווח כשהכל מתיישב, לא איך להכריע במחלוקת.
מבחן t-מזווג:
t(24) = 5.88, p < .001, 95% CI [4.23, 8.81], Cohen's d_z = 1.18 (על גודל אפקט, ועל רווח סמך בנפרד.)
Wilcoxon signed-rank:
W = 6.00, p < .001, median diff = 5
(מדד גודל אפקט נפוץ הוא r ≈ |z|/√n. כאן הוא יוצא בערך 0.84, אבל זהו קירוב תלוי-מוסכמה ש-SciPy לא מחזיר ישירות; דיווחו אותו רק אם המנחה מבקש, ובאותה תוכנה שבה ביצעתם את ה-Wilcoxon. הסטטיסטיקה W = 6.00 שמודפסת ב-SciPy היא סכום הדירוגים הנמוך מבין שני הסימנים, ולא מספרת לבדה את כיוון השינוי. הכיוון נקרא מההפרשים עצמם: ממוצע 6.52 וחציון 5 חיוביים, כלומר שחיקה ירדה אחרי הסדנה.)
שני המבחנים מצביעים על ירידה ברורה בשחיקה אחרי הסדנה. ההסכמה כאן אינה הוכחה כללית שמבחן t עמיד בכל מקרה של אי-נורמליות. גודל אפקט גדול בעיקר מקל על שני המבחנים להסכים, ולא הופך אף אחד מהם ליותר תקף תחת הפרת הנחות. מה שהדוגמה כן מראה הוא איך לתעד את הסטייה מנורמליות, לבחור מבחן ראשי, ולהוסיף בדיקת רגישות באופן שמאפשר לוועדה לראות שהבדיקה נעשתה.
איך לדווח את זה בעבודה
הבחירה במבחן ראשי היא בחירה מתודולוגית. היא צריכה לנבוע משאלת המחקר, לא מתוצאת Shapiro-Wilk. אם הפרמטר המעניין הוא ממוצע השינוי באוכלוסייה, t-מזווג היא ברירת מחדל סבירה כשההפרשים אינם חריגים במיוחד; אחרת אפשר לשקול שיטה רובסטית או רסמפלינג שעדיין מכוונים לממוצע. אם מעניין אותך מיקום מרכזי של ההפרשים בלי רגישות חזקה לקיצוניים, Wilcoxon מתאים. אם את ממש רוצה לדבר על "אחוז המורות שהשתפרו", זאת שאלה לדיווח תיאורי או למבחן הסימנים.
במקרה שהשאלה היא ממוצע, ובדיקת הרגישות הראתה הסכמה, הניסוח האחראי בעבודה הוא משהו כזה:
"מבחן Shapiro-Wilk הצביע על סטייה גבולית מנורמליות בהתפלגות ההפרשים(W = 0.92, p = .049). בהתחשב בעמידותו של מבחן t לסטיות מתונות, המבחן הראשי בוצע ב-t-מזווג, ובמקביל בוצע מבחן Wilcoxon signed-rank כבדיקת רגישות. מבחן ה-t הראה ירידה מובהקת בשחיקה לאחר ההתערבות,t(24) = 5.88, p < .001, 95% CI [4.23, 8.81], ובדיקת הרגישות באמצעות Wilcoxon אישרה את אותו כיוון(W = 6.00, p < .001; median diff = 5, pre − post)."
הניסוח הזה לא מתחבא מאחורי בחירה. הוא מציין את האזהרה (Shapiro-Wilk גבולי), מסביר את הבחירה במבחן הראשי, ומציג את ה-Wilcoxon כמה שהוא: בדיקת חוסן, לא חוות דעת שנייה.
מתי באמת לעבור למבחן לא-פרמטרי
לפני שמחליפים את המבחן הראשי, כדאי לחזור לשאלת המחקר ולנתונים עצמם. שלוש סיטואציות מצדיקות מעבר:
שאלת המחקר עוסקת במגמה הכללית, לא בממוצע. אם השאלה שלך היא "האם ההפרשים נוטים בצורה עקבית לכיוון אחד", בלי שהממוצע יהיה הפרמטר המעניין, מבחן מבוסס דירוגים יותר נאמן לשאלה. הבחירה הזאת לא תלויה בנורמליות, היא נובעת מהשאלה.
חריגים שמושכים את הממוצע מהמרכז. אם בנתונים שלך יש מספר ערכים קיצוניים מאוד, כך שהממוצע כבר לא משקף "את המורה הטיפוסית", המבחן הלא-פרמטרי, שעובד על דירוגים, פחות רגיש לחריגים.
אי-הסכמה ברורה בין שני המבחנים. אם ה-t-test יצא מובהק וה-Wilcoxon לא, או להפך, זה לא אומר אוטומטית מי מהם צודק. זה אות לעצור: לבדוק חריגים, לבדוק את צורת ההתפלגות, ולחזור לשאלה אם אכן הממוצע הוא הפרמטר שמעניין אותך. הבדיקה הכפולה לא נועדה לבחור בדיעבד את המבחן שנותן p נוח יותר. אם יש אי-הסכמה אמיתית, חוזרים לפרמטר שמעניין אתכם, להנחות, ולמבנה הנתונים, ולעיתים מדווחים את שני הניתוחים במקום לבחור אחד לפי התוצאה.
מה לקחת מפה
Shapiro-Wilk מובהק הוא נקודת התחלה של חקירה, לא סופה. הוא אומר לך "תסתכלי שוב". מה לעשות אחר כך תלוי בשאלת המחקר, בגודל הסטייה, בקיומם של חריגים, ובאמת השוואה בין מבחן פרמטרי ולא-פרמטרי כבדיקת רגישות.
בדוגמה הזו ההסכמה בין שני המבחנים הייתה ברורה. זה לא מוכיח כלום באופן כללי, אבל זה מה שצריך לדווח כשזה אכן קורה: שלא נמצאה רגישות לבחירת המבחן. הוועדה לא רק שלא תיבהל, היא תראה שאת יודעת מה את עושה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.