פירסון או ספירמן: באיזה מתאם להשתמש

המנחה שלחה לך הערה: "באיזה מתאם השתמשת, פירסון או ספירמן?" שתי המילים האלה. בלי הסבר. את פותחת את הניתוח שלך, רואה את המספר, ולא בטוחה לאיזו עמודה היא מתכוונת. שתיהן מודדות מתאם. שתיהן ערך בין -1 ל-1. מה ההבדל, ולפי מה בוחרים?
זאת שאלה שכמעט כל סטודנטית למחקר חינוכי נתקלת בה, והבחירה ביניהן יכולה לשנות את התוצאה לחלוטין. בואי נראה איך, בעזרת דוגמה אחת מההתחלה ועד הסוף.
על מה כל אחת מסתכלת
שתיהן עונות על שאלה דומה: עד כמה שני משתנים נעים יחד. אבל הן בודקות את זה אחרת.
פירסון מודד עד כמה הקשר ליניארי, על בסיס הערכים עצמם. הוא מסתכל על השונות המשותפת של הערכים, מתקנן אותה, ומחזיר ערך בין -1 ל-1. ככל שהקשר הליניארי חזק יותר, פירסון מתקרב ל-1 או ל--1. הסימן אומר את הכיוון. ערכים קיצוניים יכולים להשפיע עליו מאוד, כי הם נכנסים לחישוב במלוא העוצמה שלהם.
ספירמן שואל שאלה אחרת: עד כמה הקשר מונוטוני, כלומר עולה או יורד באופן עקבי, גם אם לא בקצב קבוע. הוא לא מסתכל על הערכים אלא על הדירוג שלהם. סטודנטית במקום הראשון בנוכחות והמקום הראשון בציונים תורמת לקשר חיובי, גם אם הפער בין מקום ראשון ושני בנוכחות שונה לגמרי מהפער בציונים. ערכים שווים מקבלים דירוג ממוצע, מה שמאפשר לחשב ספירמן גם כשיש הרבה ציונים זהים, כמו בסולמות ליקרט.
ההבדל הזה, בין הסתכלות על ערכים להסתכלות על דירוגים, הוא מה שגורם לשתי השיטות להגיב אחרת לערכים חריגים ולסולמות סדורים. ננסה לראות את זה.
הדוגמה
נניח שאת חוקרת את הקשר בין מספר השעות שסטודנטית משקיעה בעבודת התזה בשבוע, לבין רמת החרדה שהיא מדווחת עליה. דגמת 30 סטודנטיות. כל אחת דיווחה כמה שעות היא עבדה השבוע, וענתה על שאלה אחת בסולם 1 עד 5: "כמה את חרדה לגבי התזה כרגע?"
השערת המחקר שלך: יותר עבודה, פחות חרדה. הסטודנטיות שמשקיעות יותר מרגישות יותר בשליטה. את מריצה ניתוח. הנתונים נראים כך:
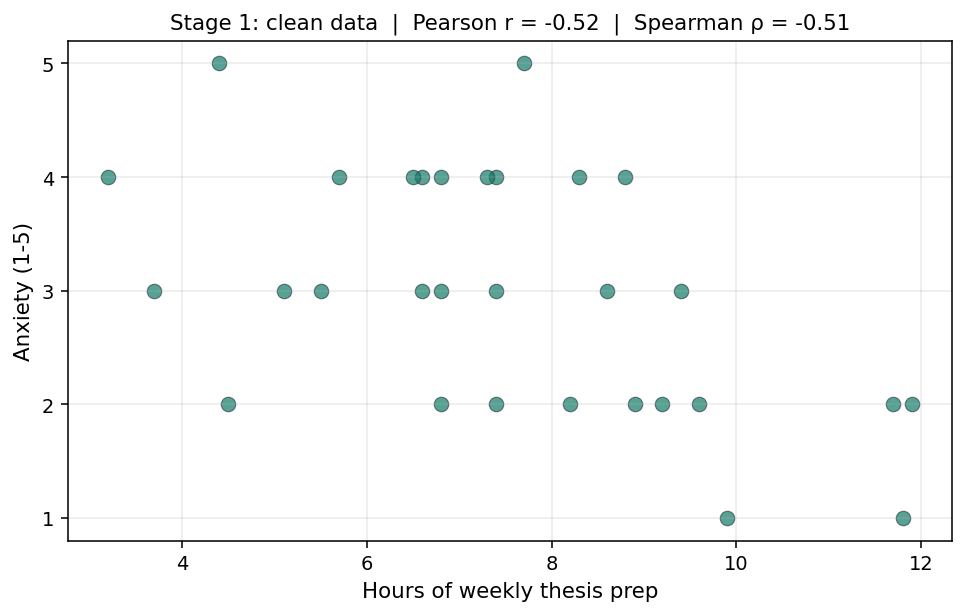
פירסון: r = -0.52, p = .003.
ספירמן: ρ = -0.51, p = .004.
שתיהן מספרות אותו סיפור. קשר שלילי, בינוני, מובהק. גם אילו דיווחת רק את אחת מהן, התמונה הייתה זהה. בנתונים יחסית נקיים וכשהקשר ליניארי בקירוב, פירסון וספירמן בדרך כלל מסכימים.
(שווה לשים לב: החרדה כאן היא בסולם ליקרט, 1-5. זה כשלעצמו נחשב לעיתים סיבה לעדיף ספירמן, נפרדת מהדיון על ערכים חריגים. נחזור לזה בסוף.)
ועכשיו, סטודנטית אחת
סטודנטית אחת ממלאת את הטופס. היא מדווחת 30 שעות עבודה השבוע, וחרדה של 5. את מוסיפה אותה לקובץ ומריצה את הניתוח שוב.
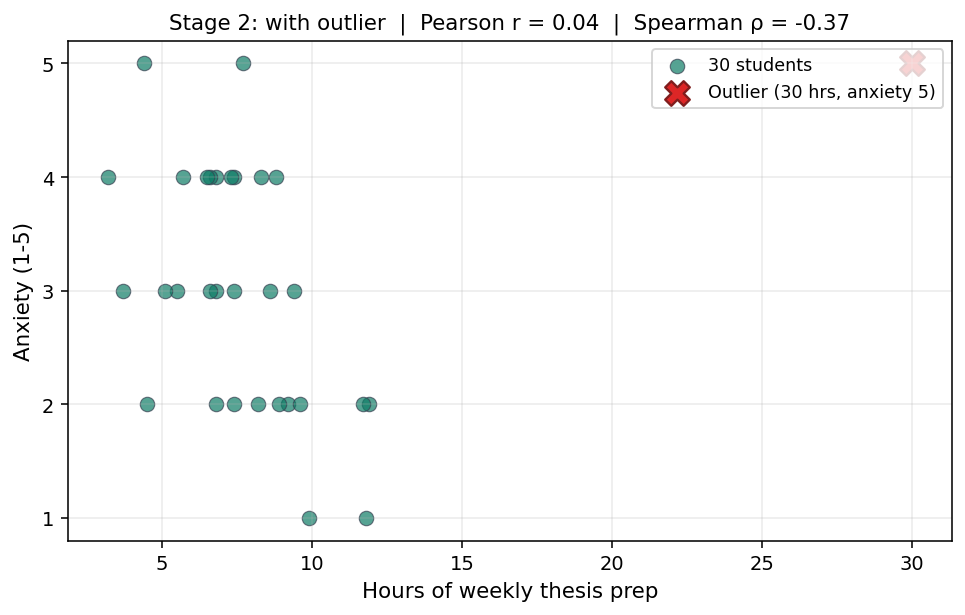
פירסון: r = 0.04, p = .82.
ספירמן: ρ = -0.37, p = .04.
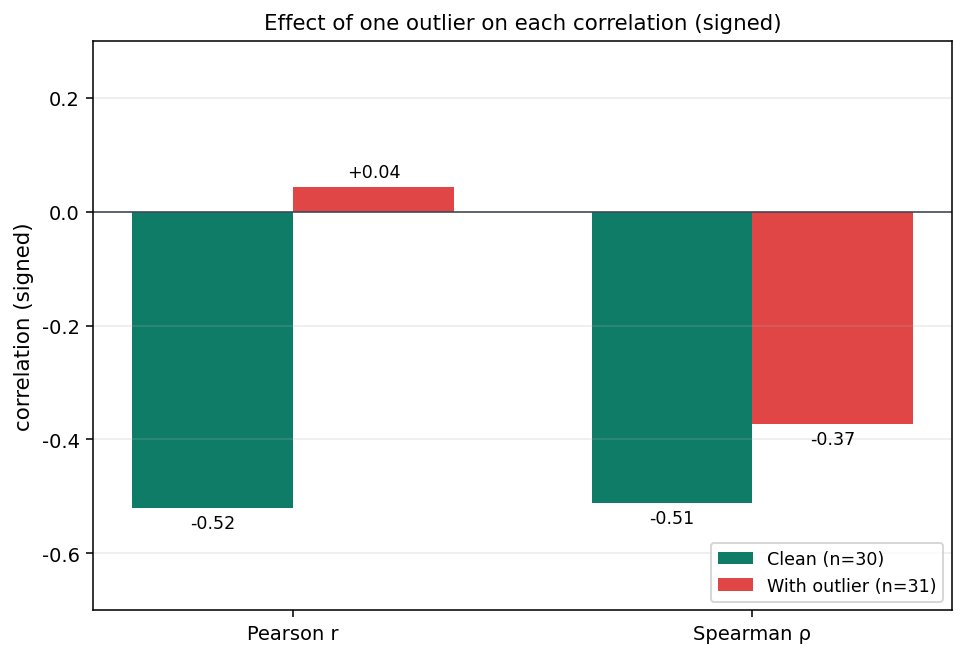
נקודה אחת. פירסון כמעט מתאפס, ואפילו הופך לסימן חיובי קטן. הקשר הליניארי שראית קודם נעלם. אם תדווחי את פירסון, תכתבי שאין עדות לקשר ליניארי ברור בין שעות עבודה לחרדה. ספירמן נחלש, מ--0.51 ל--0.37, אבל נשאר שלילי ומובהק (p = .04). הסיפור עדיין שם, גם אם החליש: יותר עבודה, פחות חרדה.
רגע לפני שמסיקים מסקנות
לפני שאת בכלל מחליפה לספירמן, צריך לעצור: 30 שעות עבודה בשבוע על תזה, האם זה מספר אפשרי? אולי הסטודנטית הקלידה 30 במקום 3. אולי השאלה לא הייתה ברורה והיא ענתה על משהו אחר. אם זאת טעות, הצעד הראשון הוא לבדוק את המקור, לא להחליף שיטה. החלפת שיטה נכונה רק כשהנקודה אמיתית והשאלה היא איך לתאר את הנתונים בצורה הוגנת.
נניח שבדקת והנקודה אמיתית. סטודנטית שעובדת באמת 30 שעות בשבוע, וגם מאוד חרדה. עכשיו, איזו שיטה לבחור?
למה הן הגיבו אחרת
פירסון משתמש בערכים עצמם, כך שערך קיצוני נכנס לחישוב במלוא העוצמה שלו. הסטודנטית שמדווחת 30 שעות וחרדה 5 רחוקה מאוד מכל הסטודנטיות האחרות בציר השעות, וזה מה שנקרא leverage גבוה. בנוסף, היא נמצאת בכיוון שמנוגד למגמה השלילית הכללית, ולכן ההשפעה שלה על תוצאת המתאם היא דרמטית. נקודה כזאת היא גם influential, לא רק קיצונית.
ספירמן מסתכל רק על הדירוג. הסטודנטית שמדווחת 30 שעות הופכת לראשונה מבחינת שעות, אבל זה רק "מקום ראשון", לא "30 שעות". בחרדה, היא מצטרפת לקבוצה שכבר דיווחה 5, וכל הקבוצה הזו מקבלת דירוג ממוצע. ספירמן מתבסס על דירוגים, לא על מרחקים, ולכן ההשפעה של הנקודה על מתאם הדירוגים קטנה הרבה יותר מאשר על פירסון.
חשוב לציין: ספירמן לא חסין. הוא נחלש מ--0.51 ל--0.37, וערך p שלו עלה מ-0.004 ל-0.04. זה שינוי אמיתי, במיוחד במדגם קטן. הוא פשוט פחות חשוף לערכים קיצוניים מאשר פירסון.
איך לבחור
הדוגמה למעלה מראה דבר אחד מאוד ספציפי: ספירמן עמיד יותר לערכים חריגים מאשר פירסון. זה ההבדל הראשון. ההבדל השני, נפרד, הוא איך כל אחת מתמודדת עם סולמות סדורים כמו ליקרט. שם המרחקים בין הקטגוריות לא בהכרח שווים (האם המרחק בין "מסכימה" ל"מסכימה מאוד" באמת זהה למרחק בין "ניטרלית" ל"מסכימה"?), כך שגם בלי ערכים חריגים, מתאם דירוגים נחשב לעיתים לתיאור הוגן יותר. לזה לא ראינו דוגמה ייעודית במאמר הזה, אבל הכלל המעשי משלב את שני ההבדלים.
הכלל המעשי, למרבית עבודות התזה בחינוך:
- שני המשתנים רציפים, מפוזרים סביר, ללא ערכים חריגים בולטים: פירסון. הוא חזק יותר סטטיסטית כשההנחות שלו (ליניאריות, מדידה רציפה בקירוב) מתקיימות.
- פריט ליקרט בודד: ספירמן הוא בחירה זהירה ומקובלת. פריט בודד הוא טכנית סדור, לא רציף.
- מדד שמבוסס על סכום או ממוצע של כמה פריטי ליקרט: כאן הבחירה תלויה. סכום של 10 פריטים מתנהג בפועל די רציף, ופירסון מקובל. אם המדד מוטה, יש מעט פריטים, או יש ספקות, ספירמן מתאים.
- הנתונים מוטים, יש ערכים חריגים, או הקשר נראה לא ליניארי אבל מונוטוני: ספירמן.
- לא בטוחה: דווחי את שניהם, אבל בחרי את העיקרי מראש, לפי סוג הנתונים והפיזור שלהם, לא לפי איזה מהם יצא מובהק. אם הם מסכימים, הסיפור פשוט. אם הם נחלקים, זה אות לבדוק את הסולם, את הפיזור, ואת הנקודות החריגות. הפער בין השניים בעצמו מספר משהו על הנתונים.
מה לקחת מפה
אם המנחה שאלה אותך באיזה מתאם השתמשת, התשובה הנכונה תלויה בנתונים שלך. תסתכלי על הסולם של כל משתנה. תסתכלי על פיזור הנתונים. אם יש לך משתנה בסולם ליקרט בודד או נקודות חריגות, ספירמן הוא הבחירה הזהירה. אם הנתונים נקיים ורציפים, פירסון ייתן לך יותר עוצמה.
ואם את עדיין לא בטוחה, אין שום בעיה לדווח את שתיהן. במאמרים אקדמיים זה אפילו מקובל. השאלה לא "מי משתיהן הנכונה" אלא "מי מהן מתארת בצורה הוגנת את מה שיש לי בנתונים". על השאלה הזאת את עונה, לא הנוסחה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.