גודל אפקט ל-ANOVA: למה η² לבד לא מספיק

אתמול הכנסת לפרק הממצאים את ה-ANOVA ואת ה-post-hoc. שלוש קבוצות, F יצא 12.87, וה-Tukey הראה שיסודי שונה גם מחט"ב וגם מתיכון, וחט"ב-תיכון לא חצה את הסף. הכנסת גם η² = 0.63, כי הפוסט על גודל אפקט אמר שצריך לדווח על אחד.
המנחה ענה שני דברים. ש-η² מנפח במדגמים קטנים, ולתת ω² במקום. ושאת צריכה Cohen's d לזוגות שיצאו מובהקים, לא רק לכלל.
שתי שאלות שונות. נתחיל מהראשונה.
למה η² מנפח
η² הוא יחס פשוט. כמה מסכום הריבועים הכולל קשור להבדל בין הקבוצות. בנתונים שלך:
η² = SS_between / SS_total = 6.04 / 9.56 = 0.6318
במדגם הזה, 63% מהפיזור הכולל בציונים מיוחס להבדל בין שלבי הגיל. נשמע ברור. הבעיה היא שהמשפט הזה מתאר את המדגם. את לא רוצה להגיד משהו על שמונה-עשרה המורות הספציפיות שדגמת. את רוצה להגיד משהו על אוכלוסיית המורות בישראל.
וכאן η² מועד. הוא לוקח את כל השונות שהוא רואה בין הממוצעים הקבוצתיים, ומיחס את כולה לקבוצה. הוא לא יודע שחלק מהשונות הזאת היא רעש דגימה, שונות שהייתה צצה אפילו אם כל המורות באוכלוסייה היו זהות. בכל פעם שדוגמים שש מורות מקבוצה, הממוצע שלהן יוצא מעט אחר. אם הקבוצות באוכלוסייה היו זהות לחלוטין, η² במדגם שלך עדיין היה גדול מאפס, רק בגלל הגרלת הדגימה.
במדגמים גדולים זה כמעט לא משנה. במדגמים קטנים, כמו אצלך, זה משנה.
ω² מחסר את הרעש
ω² (omega squared) מוגדר בדיוק כדי לתקן את הניפוח הזה. הוא לוקח את אותו SS_between, אבל מחסר ממנו אומדן של הרעש שאת מצפה לראות גם כשההבדל האמיתי באוכלוסייה הוא אפס. הנוסחה:
ω² = (SS_between − df_between × MS_within) / (SS_total + MS_within)
למה הביטוי df_between × MS_within. תחת ההנחה ש"אין הבדל בין הקבוצות באוכלוסייה", התוחלת של MS_between שווה לשונות הפנימית, ו-MS_within הוא האומדן הסטנדרטי של אותה שונות. לכן התוחלת של SS_between, רק מרעש דגימה ולא מאפקט אמיתי, היא בקירוב df_between × MS_within. ω² מחסר אותה ומקבל אומדן נקי יותר.
בנתונים שלך:
ω² = (6.04 − 2 × 0.235) / (9.56 + 0.235) = 5.57 / 9.79 = 0.5687
ההפרש: η² − ω² = 0.6318 − 0.5687 = 0.0631. η² ניפח את האפקט בכ-11% בנתונים האלה. במדגמים קטנים η² נוטה לתת ערך גדול מ-ω², אבל גודל הפער תלוי גם במבנה הספציפי של הנתונים ולא רק ב-N.
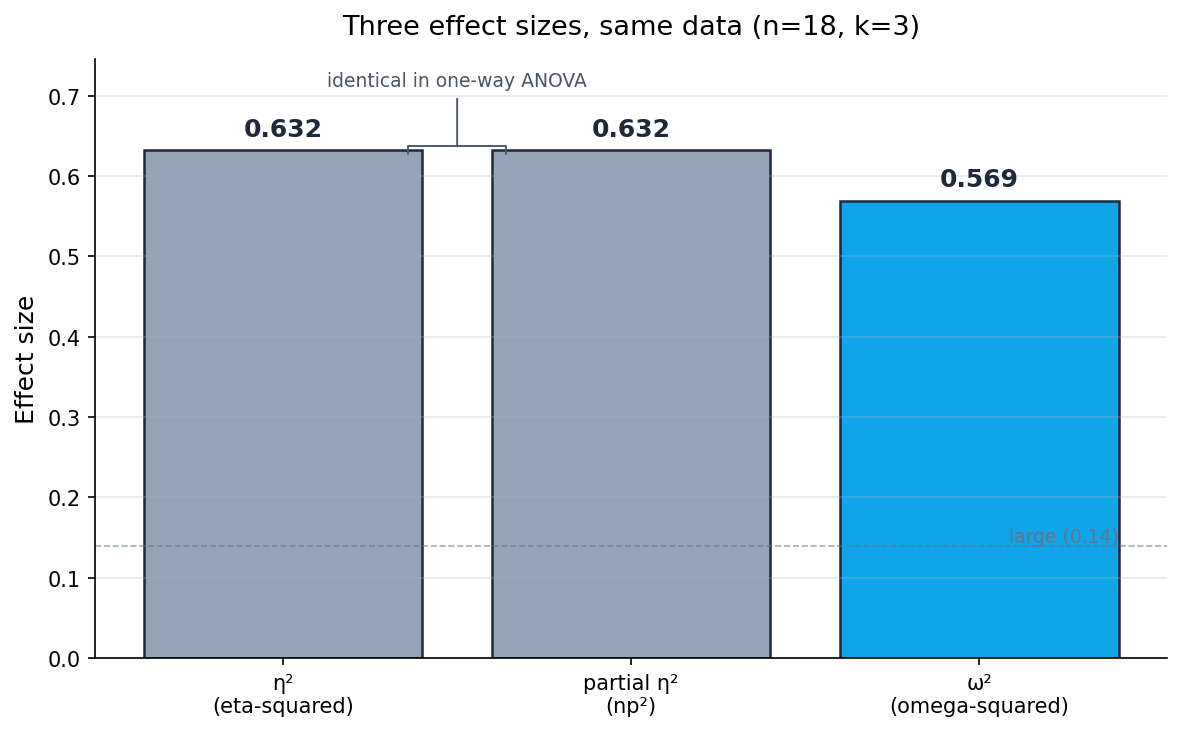
שני המספרים עדיין מתחת לאותה תווית, "אפקט גדול" לפי המוסכמה הנפוצה (גדול = 0.14 ומעלה, אבל זאת מוסכמה גסה, לא חוק). הסיווג לא משתנה כאן. מה שכן משתנה הוא ההטיה: ω² מוטה כלפי מעלה פחות מ-η² כשמשווים על פני הרבה דגימות חוזרות. במדגם בודד אי אפשר לומר ש-0.57 קרוב יותר לערך באוכלוסייה מ-0.63. אפשר רק לומר ש-ω² פחות נוטה לנפח. במחקרים שבהם η² יושב על הגבול בין קטגוריות, התיקון יכול לשנות את הסיווג. אצלך זה לא קורה, אבל הוא מקטין את הסיכון שאת מדווחת על אומדן מנופח.
על partial η², בקצרה
במחקרים שמשתמשים בתוכנה כמו SPSS את תראי שם partial η², או בכתיבה η²p. במערך כמו שלך, ANOVA חד-כיוונית בין-נבדקית, partial η² שווה ל-η² בדיוק. אותו מספר.
הם מקבלים ערכים שונים במערכים שיש בהם רכיבי שונות נוספים, כמו ANOVA דו-כיווני (יותר מגורם אחד), מדידות חוזרות (אותם נבדקים נמדדים יותר מפעם אחת), או ANCOVA (כשמכניסים משתנה הסבר רציף). שם partial η² מחושב כ-SS_effect / (SS_effect + SS_error) עבור האפקט הספציפי, וסכום כל ה-partial η²ים של אפקטים שונים לא חייב להגיע ל-1. אצלך זה לא קורה, ואצל מנחים שמשתמשים ב-SPSS המספר שיודפס יהיה אותו 0.6318.
השאלה השנייה: Cohen's d לזוגות
η² ו-ω² מדברים על האפקט הכולל בין שלוש הקבוצות. הם לא אומרים לך כמה גדול ההבדל בין יסודי לתיכון בנפרד, או בין יסודי לחט"ב. לזה צריך גודל אפקט אחר, ברמת הזוג: Cohen's d.
היתרון של Cohen's d הוא שהוא ביחידות של סטיית תקן. כשאת אומרת d = 1.5, את אומרת "ההבדל בין הקבוצות הוא 1.5 סטיות תקן", וזה מוחשי.
הנוסחה: ההפרש בין הממוצעים חלקי סטיית התקן המאוחדת של אותו זוג קבוצות.
d = (M_1 − M_2) / SD_pooled
SD_pooled = √(((n_1 − 1)·var_1 + (n_2 − 1)·var_2) / (n_1 + n_2 − 2))
נחשב את הזוג הראשון, יסודי מול תיכון, צעד-צעד. M_יסודי = 7.80, SD = 0.443, n = 6. M_תיכון = 6.40, SD = 0.460, n = 6. השונויות הן 0.196 ו-0.212. סטיית התקן המאוחדת היא √((5×0.196 + 5×0.212) / 10) = √0.204 = 0.452. וה-d הוא 1.40 / 0.452 = 3.10.
| זוג | הפרש | SD מאוחד | Cohen's d | גודל (Cohen) | מובהק (Tukey) |
|---|---|---|---|---|---|
| יסודי − תיכון | +1.40 | 0.452 | 3.10 | גדול | כן |
| יסודי − חט"ב | +0.90 | 0.496 | 1.81 | גדול | כן |
| חט"ב − תיכון | +0.50 | 0.504 | 0.99 | גדול | לא |
(המוסכמה של Cohen מסווגת d ≥ 0.8 כ"גדול". שני d-ים הראשונים גדולים בהרבה מ-0.8 אבל אין סף סטנדרטי ל"גדול מאוד".)
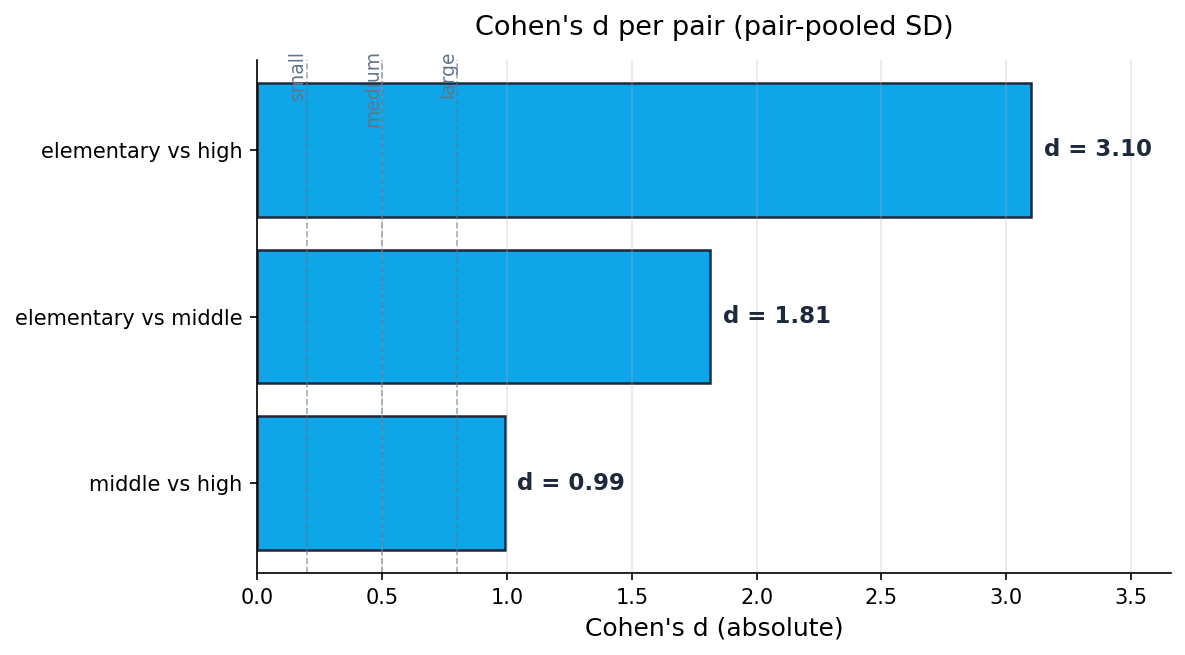
תסתכלי על השורה האחרונה. ההבדל בין חט"ב לתיכון הוא חצי נקודה. Cohen's d יוצא 0.99, גדול לפי המוסכמות של Cohen. ובכל זאת, ה-Tukey HSD אמר אתמול שהזוג הזה לא חוצה את הסף (p = .21).
זה לא סתירה. זה שני דברים שונים. גודל אפקט הוא אומדן נקודתי של גודל ההבדל ביחס לרעש. p-value אומר עד כמה הנתונים אינם מתיישבים עם השערת האפס תחת המודל. הכיוון של ההבדל מגיע מהממוצעים עצמם, לא מ-p.
יש כאן גם הבדל מבני שכדאי לזכור. ה-d מחושב עם סטיית התקן של אותו זוג ספציפי, בעוד ש-Tukey משתמש בערך השונות הכולל של ה-ANOVA (MS_within) ועוד מוסיף תיקון משפחתי על שלוש ההשוואות. הוא יותר שמרני, ולכן ה-p-value שלו לא חייב להתאים ל-d של זוג בודד.
צירוף של d גדול עם p לא מובהק אומר: יש לך אומדן נקודתי גדול עם טעות דגימה גדולה, אחרי תיקון משפחתי. הוא יכול להעיד על אפקט אוכלוסייה אמיתי שלא הוערך בדיוק, והוא יכול להיות תוצאה של דגימה רועשת. במדגם של שש מול שש את לא יודעת לקבוע. ה-רווח הסמך של Tukey לזוג הזה היה [-0.23, +1.23], חוצה את האפס. מה שכן ראוי לעשות בפרק הדיון: לציין את d, לציין שהוא גדול ולא מובהק, ולא לטעון מעבר.
מה לכתוב בפרק הממצאים
שורה אחת לאפקט הכולל. שורה אחת לזוגות.
"ANOVA חד-כיוונית הראתה הבדלים מובהקים בתחושת המסוגלות העצמית בין שלבי הגיל,
F(2, 15) = 12.87, p < .001, η² = .63, ω² = .57. השוואות post-hoc של Tukey HSD הראו שיסודי (M = 7.80) גבוה משמעותית מחט"ב (M = 6.90, Cohen's d = 1.81) ומתיכון (M = 6.40, Cohen's d = 3.10). ההבדל בין חט"ב לתיכון לא היה מובהק (Cohen's d = 0.99, p = .21)."
שלושה דברים שכדאי לשים לב אליהם. אחד, דווחת גם η² וגם ω², עם ω² כאומדן המועדף וה-η² לידו לצורך נראות. שתיים, ציינת d רק לזוגות, יחד עם הממוצעים, וקוראת יכולה לראות את כיוון ההבדל מההפרש בין הממוצעים. שלוש, הזכרת d גם לזוג הלא-מובהק, כי הוא בכל זאת גדול לפי Cohen, וזה מידע שמשנה את הפרשנות בפרק הדיון.
בקיצור
η² ו-ω² עונים על אותה שאלה כללית, "כמה מהשונות הוסבר על ידי השיוך לקבוצה", רק ש-ω² מתקן את הניפוח שמובנה ב-η². בנתונים שלך זה הפרש של כ-11%, שני המספרים עדיין מסווגים כאפקט גדול, אבל ω² פחות מנפח כלפי מעלה. partial η² בנתונים האלה שווה ל-η². הוא שונה ממנו במערכים מורכבים יותר.
Cohen's d לזוגות הוא שאלה אחרת לגמרי. הוא לא מחליף את ה-p של ה-post-hoc, הוא מוסיף לו. d גדול עם p לא מובהק זה אומדן נקודתי גדול עם אי-ודאות גדולה. את מדווחת על שניהם, לא הופכת אחד לשני.
החלק הבא של הסיפור, אם יש לך מערך עם יותר מגורם אחד או מדידות חוזרות על אותם נבדקים, מתחיל לדבר על partial η² כמדד ששונה משמעותית מ-η². נגיע גם לזה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.