ANOVA: כשיש לך שלוש קבוצות, ושני מבחני t לא יספיקו

יש לך שלוש קבוצות. מורות מיסודי, מורות מחט"ב, מורות מתיכון. שלוש קבוצות ושאלה אחת: האם תחושת המסוגלות העצמית של המורה משתנה לפי שכבת הגיל שבה היא מלמדת.
פתחת SPSS. חיפשת t-test, כי זה מה שאת מכירה. ואז ראית שיש שני שדות בלבד לרשום בהם קבוצות, ולך יש שלוש. רגע, אז מה עכשיו? להריץ שלושה מבחני t? יסודי מול חט"ב, יסודי מול תיכון, חט"ב מול תיכון?
אפשר. אבל יש שם בעיה.
הבעיה עם שלושה מבחני t
כל מבחן סטטיסטי שאת מריצה ב-α = 0.05 כרוך ב-5% סיכוי לטעות מסוג ראשון, כלומר לומר "יש הבדל" כשבמציאות אין. אם תריצי מבחן אחד, את חיה עם 5%. אם תריצי שלושה מבחנים נפרדים על אותם נתונים, הסיכוי שלפחות אחד מהם יוביל לטעות גדל. הוא לא נשאר 5%.
החישוב, בקירוב: הסיכוי שאף אחד מהמבחנים לא יטעה הוא 0.95 × 0.95 × 0.95 = 0.857. ואז הסיכוי שלפחות אחד כן יטעה הוא 1 − 0.857 = 0.143. כ-14%, כשחשבת שאת עובדת עם 5%.
זה קירוב, כי המבחנים האלה לא בלתי-תלויים, הם משתמשים באותם נתונים. המספר המדויק תלוי בקורלציה ביניהם, אבל הכיוון ברור: יותר מבחנים, יותר סיכון.
זה הרבה מעבר ל-5%, פי שלוש מהסף המוסכם בתחום. הוועדה תזהה את זה, והניתוח יחזור אליך לתיקון. המנחה כנראה כבר אמר לך לעשות ANOVA במקום.
מה ANOVA בעצם עושה
אותו רעיון של מבחן t, רק שמתאים למספר קבוצות במקביל. הרעיון המרכזי זהה: השוואה בין סיגנל לרעש. ההבדל בניסוח שלהם.
במבחן t את משווה ממוצע אחד לממוצע אחר, ומחלקת בשגיאת התקן של ההפרש. ב-ANOVA את לא מסתכלת על הפרשים בין זוגות, אלא שואלת שאלה אחרת לגמרי:
כמה גדולה השונות בין ממוצעי הקבוצות, יחסית לשונות בתוך כל קבוצה?
אם הקבוצות באמת שונות זו מזו, ממוצעיהן יהיו רחוקים זה מזה. אם בתוך כל קבוצה האנשים די דומים, הפיזור הפנימי יהיה קטן. במקרה כזה השונות בין הקבוצות תהיה גדולה ביחס לשונות בתוכן. זה סיגנל חזק.
אם הקבוצות לא באמת שונות, ממוצעיהן יהיו קרובים מאוד זה לזה. הפיזור הפנימי בתוך כל קבוצה יהיה דומה לפיזור בין הממוצעים. אין שום סיגנל. הכל רעש.
המספרים שלך
נניח שדגמת שש מורות מכל שלב גיל, וקיבלת ציוני מסוגלות עצמית בסולם 1-10:
| יסודי | חט"ב | תיכון |
|---|---|---|
| 7.2 | 6.0 | 5.8 |
| 8.1 | 7.2 | 6.5 |
| 7.5 | 6.5 | 6.0 |
| 8.4 | 7.3 | 6.8 |
| 7.6 | 7.0 | 7.0 |
| 8.0 | 7.4 | 6.3 |
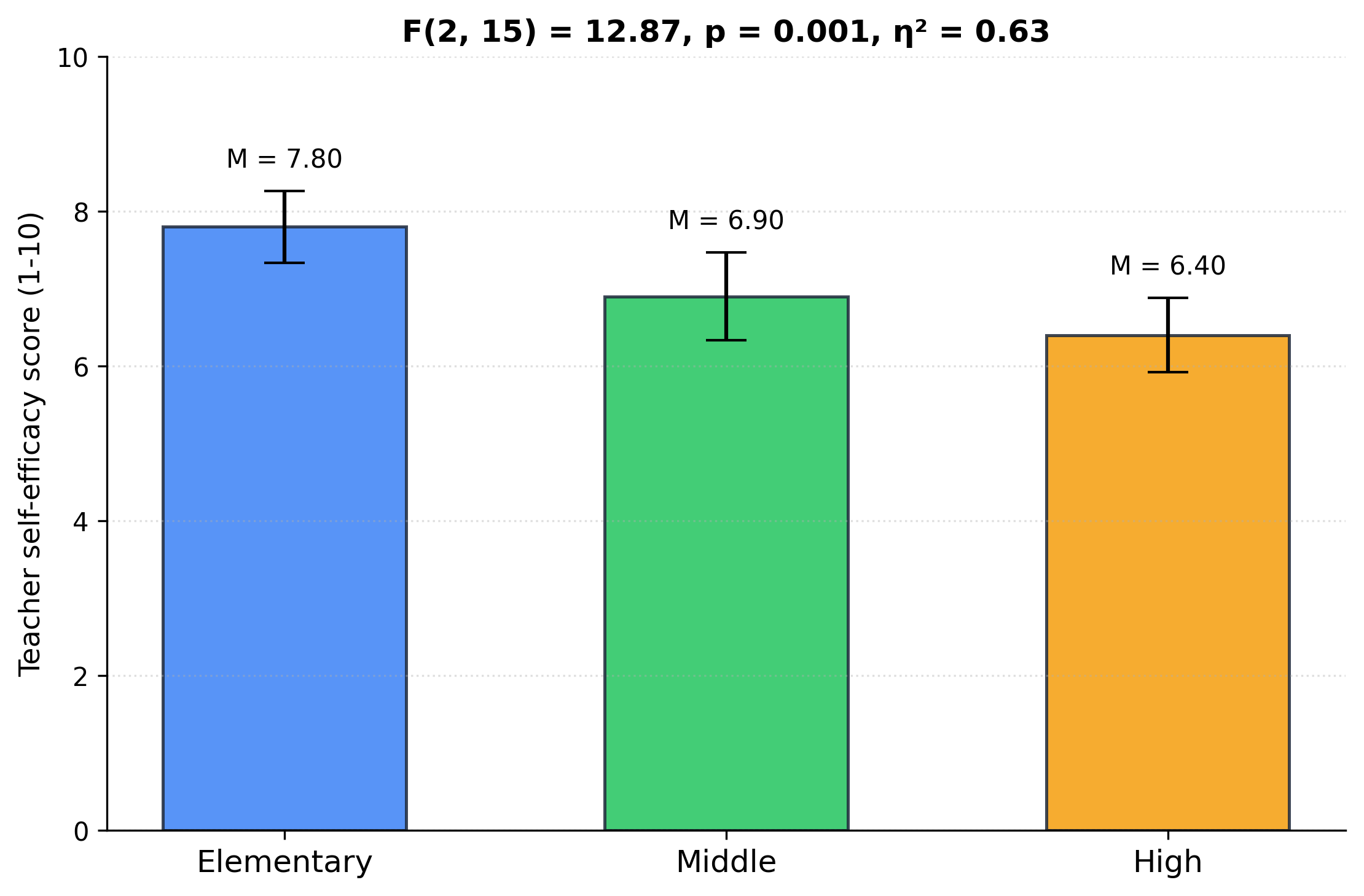
| M = 7.80 | M = 6.90 | M = 6.40 |
נראה שיש מגמה. הממוצע יורד ככל שעולים בשלבי הגיל. אבל הפיזור בתוך כל קבוצה לא קטן. ביסודי יש גם 7.2 וגם 8.4. בתיכון יש מורה אחת עם 7.0, שיותר גבוה ממורה אחת מיסודי. אז השאלה היא: האם המגמה הזאת רק רושם או שהיא מבוססת.
הממוצע הכללי של כל 18 הציונים יוצא 7.03. זו נקודת הייחוס שלנו.
בונים את F
שני מספרים. אחד למעלה ואחד למטה.
למעלה: שונות בין הקבוצות (MSbetween). כמה רחוק כל ממוצע קבוצתי מהממוצע הכללי, משוקלל לפי גודל הקבוצה.
יסודי: 6 × (7.80 − 7.03)² = 3.56
חט"ב: 6 × (6.90 − 7.03)² = 0.10
תיכון: 6 × (6.40 − 7.03)² = 2.38
סכום: SS_between = 6.04
כדי לקבל ממוצע (mean square), מחלקים בדרגות חופש. כאן יש 3 קבוצות, אז df_between = 3 − 1 = 2.
MS_between = 6.04 / 2 = 3.02
למטה: שונות בתוך הקבוצות (MSwithin). כמה רחוק הציון של כל מורה מהממוצע של הקבוצה שלה.
יסודי: Σ(x − 7.80)² = 0.98
חט"ב: Σ(x − 6.90)² = 1.48
תיכון: Σ(x − 6.40)² = 1.06
סכום: SS_within = 3.52
דרגות החופש: df_within = N − k = 18 − 3 = 15.
MS_within = 3.52 / 15 = 0.235
ועכשיו ה-F:
F = MS_between / MS_within = 3.02 / 0.235 = 12.87
השונות בין הקבוצות גדולה פי 12.87 מהשונות הממוצעת בתוך הקבוצות. זה הרבה.
מה F = 12.87 אומר
בדיוק את אותה שאלה שמבחן t עונה עליה, רק בסולם אחר. אם נניח שאין שום הבדל אמיתי בין שלוש הקבוצות, מה ההסתברות שניקלע ל-F כל-כך גדול? התשובה מגיעה מהתפלגות F עם דרגות חופש (2, 15).
p = 0.0006
במילים: אם הקבוצות באמת היו זהות באוכלוסייה, סיכוי של כ-0.06% שניקלע ל-F בגודל הזה או גדול יותר. שש מאיות האחוז. זו ראיה חזקה נגד "אין שום הבדל".
גודל האפקט: η² = SS_between / SS_total = 6.04 / 9.56 = 0.63. במדגם שלנו, 63% מסכום הריבועים הכולל הוא שונות בין הקבוצות. במילים אחרות, רוב הפיזור בציונים נקשר לשלב הגיל. זה אפקט גדול. (η² נוטה להעריך את האפקט באוכלוסייה כלפי מעלה. בפועל הוא קצת קטן יותר. עדיין גדול.)
הקטע שאת חייבת לדעת
ANOVA אמרה לך: "יש ראיות סטטיסטיות שלפחות שתיים מהקבוצות שונות זו מזו." היא לא אמרה לך אילו שתיים. היא לא ציינה אם יסודי שונה מחט"ב, אם יסודי שונה מתיכון, או אם חט"ב שונה מתיכון. רק שלפחות אחד מהפערים האלה לא רעש.
זה כל מה שהיא יכולה. היא לוקחת תמונה כללית של "האם משהו כאן זז", ועונה כן או לא. כדי להבין היכן נמצאים ההבדלים, צריך מבחן נוסף, אחרי ה-ANOVA, שנקרא מבחן post-hoc.
מבחני post-hoc כוללים בתוכם תיקון לבעיית המבחנים המרובים. לכן הם תקפים אחרי ANOVA, בעוד ששלושה מבחני t גולמיים על אותם נתונים לא היו תקפים.
הפוסט הזה לא ממצה את הסיפור. נגיע אליו בקרוב, כי זה החלק שאת תצטרכי כדי לכתוב את פרק הממצאים.
בקיצור
שלוש קבוצות או יותר. אל תריצי שלושה מבחני t גולמיים, זה מעלה את הסיכון לטעות מ-5% לכ-14%. הריצי ANOVA, היא בודקת בבת אחת אם השונות בין הממוצעים גדולה מהשונות בתוך הקבוצות.
מה שאת רואה בפלט: F(df_between, df_within) = ..., p-value, ולפעמים η². ה-F הוא היחס בין השונויות. ה-p אומר כמה נדיר היחס הזה תחת ההנחה שאין הבדל. ה-η² אומר כמה גדול האפקט.
אם ה-F יצא מובהק, את יודעת שמשהו זז. עכשיו צריך לראות בדיוק איפה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.