מה מבחן t בעצם עושה? המבחן שאת מריצה הכי הרבה, מבפנים

את לוחצת Compare Means > Independent-Samples T Test, SPSS מחזיר טבלה: t = 2.41, df = 38, p = 0.021. את יודעת ש-p קטן מ-0.05 זה טוב. את לא יודעת מה t. את לא יודעת למה דווקא 38. את לא יודעת איך המבחן החליט ש-2.41 זה הרבה ולא מעט. הרצת אותו עשרים פעם בלי לדעת מה הוא עושה.
אחרי פוסטים שלמים שמדברים על המספרים שהמבחן הזה מחזיר, הגיע הרגע לפתוח את הקופסה. מבחן t עושה דבר אחד פשוט, וכשרואים אותו מבפנים, כל המספרים שהוא מחזיר מסתדרים.
הדוגמה
שתי כיתות ז' מקבילות, אותה מורה. בכיתה אחת היא מלמדת הבנת הנקרא בקריאה שקטה. בכיתה השנייה, באותה תכנית, היא מלמדת בקריאה בקול ודיון משותף. בסוף השנה היא מעבירה לשתי הכיתות את אותו מבחן סטנדרטי על סולם 0 עד 100. 20 תלמידות בכל כיתה.
הממוצע בקריאה השקטה: 68.40 (SD = 9.01). הממוצע בקריאה בקול: 76.35 (SD = 11.66). הבדל של כמעט 8 נקודות לטובת הקריאה בקול. השאלה הסטטיסטית היא לא "האם הקריאה בקול עדיפה". השאלה היא: האם 8 הנקודות האלה גדולות מספיק יחסית לפיזור בתוך הכיתות כדי להיחשב לראיה רצינית?
בונים את t
זאת בדיוק השאלה ש-t עונה עליה, בשלושה צעדים.
צעד ראשון, ההבדל בין הממוצעים. זה המונה. הסיגנל. כאן הוא 7.95 נקודות.
צעד שני, להעריך את הפיזור שמצפים לו בעולם. הציונים בשתי הכיתות התפזרו סביב הממוצע שלהן. כדי לקבל הערכה אחת של הפיזור (sd), משלבים את שתי סטיות התקן לסטיית תקן מאוחדת:
s_p = √(((n₁ − 1)·s₁² + (n₂ − 1)·s₂²) / (n₁ + n₂ − 2)) = 10.42
במילים, זאת סטיית התקן המשותפת אם נניח שהציונים גם בקריאה השקטה וגם בקריאה בקול מתפזרים בערך באותה מידה. אם כיתה אחת מפוזרת מאוד והשנייה מאוד מרוכזת, ההנחה הזאת לא מתקיימת ומשתמשים בגרסת Welch, שמרככת אותה.
צעד שלישי, להפוך את הפיזור הזה לשגיאת תקן של ההפרש. סטיית תקן של מדגם בודד היא לא מה שמעניין אותנו. מה שמעניין אותנו זה כמה ההפרש בין שני ממוצעים נוטה להשתנות מדגימה לדגימה. זה SE, שגיאת התקן של ההפרש:
SE = s_p · √(1/n₁ + 1/n₂) = 10.42 · √(1/20 + 1/20) = 3.29
שגיאת התקן עונה על שאלה ספציפית: אם היינו חוזרות על הניסוי הזה עם זוגות חדשים של כיתות מאותה אוכלוסייה, כמה ההפרש בין הממוצעים היה משתנה בכל פעם? סדר הגודל הזה הוא הרעש שצריך לעבור.
ועכשיו t עצמו. הסיגנל חלקי הרעש:
t = mean_diff / SE = 7.95 / 3.29 = 2.41
זהו. זה כל מבחן t. היחס בין ההבדל שמדדת לבין סדר הגודל של תנודות אקראיות בהפרש כזה. ערך 1 אומר שההפרש בערך בגודל הרעש הצפוי. ערך 2.41 אומר שההפרש גדול פי 2.41 מהרעש הצפוי. ערך 0.3 אומר שההפרש נבלע ברעש.
שלושת הכפתורים שמזיזים את t
אם זה היחס בין סיגנל לרעש, יש בדיוק שלושה דברים שיכולים לשנות את t. אפשר לראות אותם בנפרד:
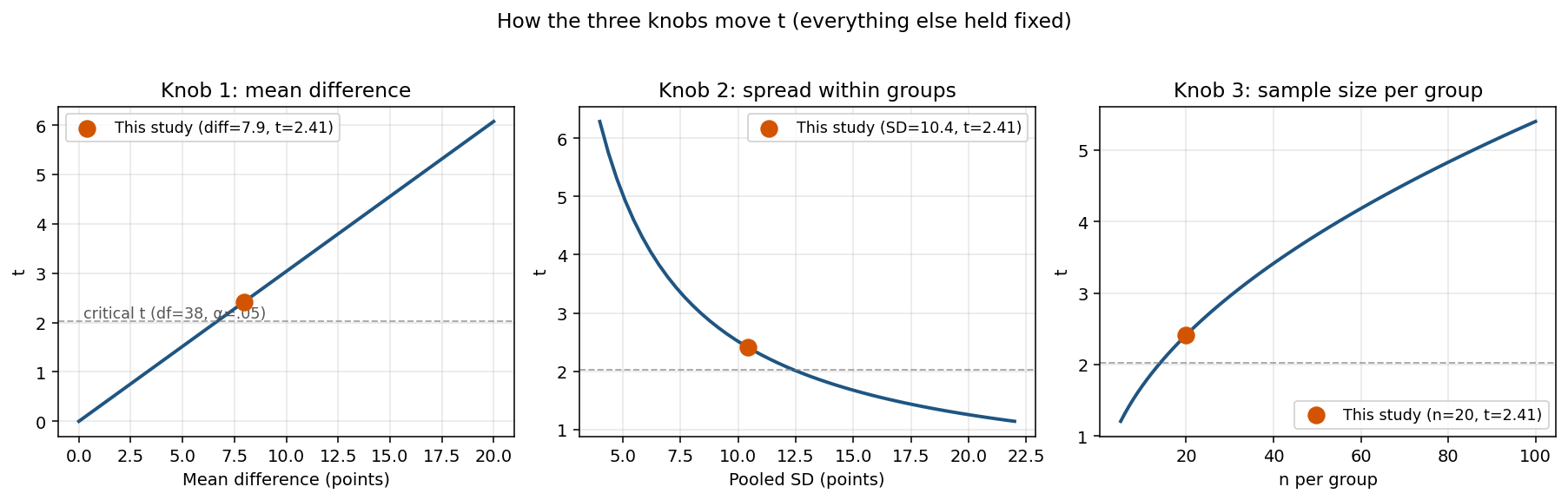
כפתור ראשון, ההבדל בין הממוצעים. ההפרש כפול, t כפול. הקריאה בקול עוזרת ב-8 נקודות, t יוצא 2.41. אם ההבדל היה כפול, t היה יוצא 4.82.
כפתור שני, הפיזור בתוך הקבוצות. הפיזור הוא הרעש שמסתיר את הסיגנל. אם הפיזור גדול, t קטן. במחקר שלנו, אילו סטיית התקן המאוחדת הייתה 5 במקום 10.42, אותו הבדל של 8 נקודות היה מניב t שמתקרב ל-5. ההבדל לא השתנה. רק הרעש סביבו הצטמצם, וכעת קל יותר לראות את הסיגנל.
כפתור שלישי, גודל המדגם. זאת הסיבה ש-N משנה. מדגם גדול לא עושה את ההבדל עצמו גדול יותר. הוא מצמצם את שגיאת התקן: SE תלוי ב-√(1/n₁ + 1/n₂). עם 20 בכל כיתה, SE יוצא 3.29. עם 50 בכל כיתה ואותם ממוצעים וסטיות תקן בקירוב, SE יורד לסביבות 2.08, ואותו הבדל של 8 נקודות מניב t קרוב ל-3.8. שוב, ההבדל לא השתנה. הוודאות בו השתנתה.
זאת הסיבה שתוצאות לא מובהקות נולדות לעיתים מהשתנות יוצאת דופן בתוך הכיתות, ולא רק מהיעדר אפקט. ועל הקשר ההפוך, איך לקרוא תוצאה לא מובהקת בלי להפוך אותה ל"אין הבדל", יש מאמר נפרד.
למה df = 38
אחרי שיש t, צריך לדעת מה לעשות איתו. t = 2.41 זה הרבה? זה תלוי בעוד מקור אחד של אי-ודאות שעוד לא דיברנו עליו: שני הממוצעים וסטיות התקן שלהם הם הערכות מהמדגם, לא הערכים האמיתיים של האוכלוסייה. ככל שאת אומדת פחות פרמטרים, את יותר בטוחה בהערכה שלך. דרגות החופש סופרות כמה תצפיות חופשיות נשארו לך אחרי שכבר השתמשת בחלקן להעריך את הממוצעים.
במבחן t לשתי קבוצות בלתי-תלויות, השתמשת בתצפית אחת לכל קבוצה כדי להעריך את הממוצע שלה. נשארו: n₁ + n₂ − 2 = 20 + 20 − 2 = 38 דרגות חופש.
למה זה משנה: התפלגות t עם 38 דרגות חופש כבר דומה מאוד להתפלגות הנורמלית הסטנדרטית. הזנבות שלה דקים. עם מעט דרגות חופש, נניח 4 (כמו במאמר על p-value), הזנבות עבים יותר. אותו ערך t יוצא יותר "נסבל" כשיש פחות דרגות חופש, כי בעולם של מדגם קטן ערכי t קיצוניים פחות נדירים.
זאת הסיבה שגם בלי לזכור את הנוסחה, אפשר להבין למה t = 2.41 במחקר שלנו (df = 38) יוצא p = 0.021, ואותו t = 2.41 במחקר עם 3+3 משתתפות (df = 4) היה יוצא p ≈ 0.074. אותו סיגנל, אותו רעש. רק שמספר התצפיות הקובע את הוודאות בהערכת הרעש משתנה, וההתפלגות שמולה משווים את t משתנה איתה.
איפה 2.41 יושב
אחרי שיש t ויש df, השלב האחרון פשוט. בודקות איפה t יושב בהתפלגות הייחוס, מתוך עולם דמיוני שבו אין הבדל בין הקריאה השקטה לקריאה בקול.
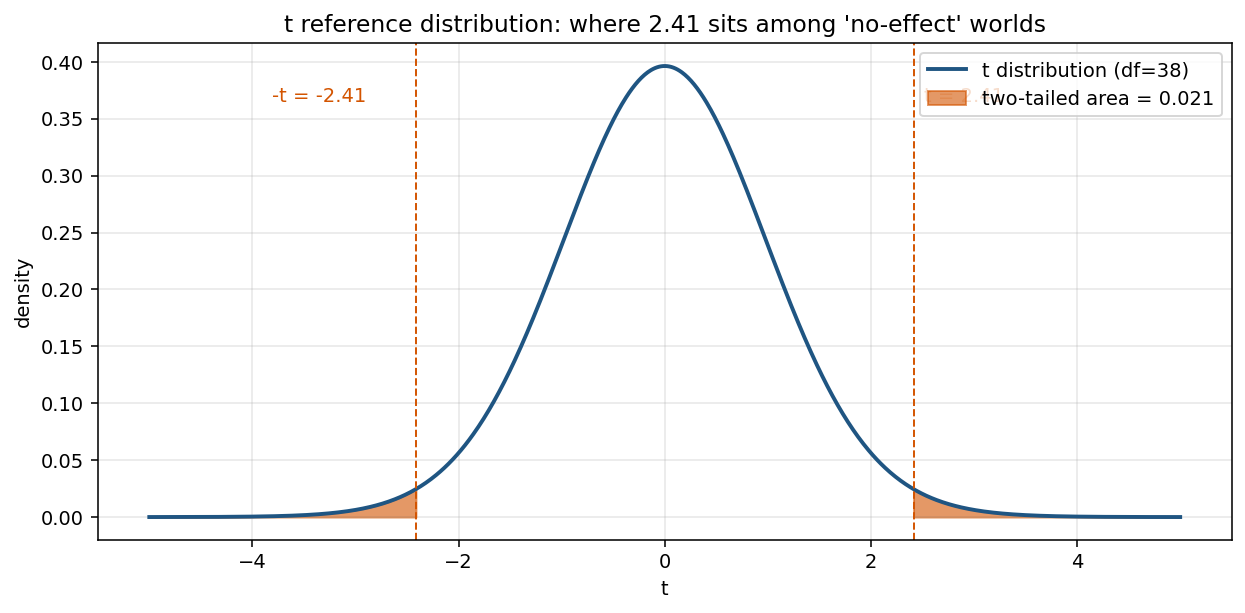
השטח האדום בשני הזנבות, מעבר ל-|t| = 2.41, הוא ה-p. כאן הוא 0.021. כלומר: בעולם שבו הקריאה השקטה והקריאה בקול זהות לחלוטין, מתוך כל הכיתות האפשריות, רק 2.1% מהדגימות היו מייצרות t רחוק מאפס כמו של המחקר הזה או רחוק יותר. זה לא הוכחה שיש הבדל באוכלוסייה. זאת ראיה שקשה לדבוק בהנחת ה"אין הבדל" מול הנתונים האלה.
שני זנבות, ולא אחד, כי השאלה דו-צדדית. לא הנחת מראש לאיזה כיוון ההבדל ייטה.
בקיצור
מבחן t עושה פעולה אחת. הוא מחלק את ההבדל שמדדת בשגיאת התקן של אותו הבדל, ומקבל מספר אחד. אם המספר גדול, ההבדל גדול ביחס לפיזור הצפוי, וקשה להסביר אותו כמקרי. אם הוא קטן, ההבדל נבלע ברעש.
שלושה גורמים מזיזים את המספר: גודל ההפרש, הפיזור בתוך הקבוצות, וגודל המדגם. דרגות החופש קובעות מול איזו התפלגות משווים את הערך, וזה משפיע על ה-p שיוצא בסוף.
זאת המכונה כולה. השאר, ניתוחים מורכבים יותר, התפלגויות אחרות, תיקונים שונים, נבנה על אותה לוגיקה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.