הממוצע יצא 10.5 והחציון 8: לקרוא נכון את טבלת הסטטיסטיקה התיאורית

המנחה אמר "תארי קודם את המדגם", או ביקש "טבלת סטטיסטיקה תיאורית" לפני שהוא בכלל מוכן להסתכל על מבחן. רצת ל-SPSS, ביקשת Descriptives, וקיבלת עמודה של מספרים: Mean, Median, Std. Deviation, Minimum, Maximum. ועכשיו את יושבת מולם בלי לדעת מה מתוכם הולך לפרק התוצאות, ולמה ממוצע הוותק יצא 10.5 שנים אבל החציון יצא 8, ואת בטוחה שעשית טעות איפשהו.
לא עשית טעות. הפער הזה בין הממוצע לחציון הוא מידע, לא באג. הוא מספר לך משהו על צורת הנתונים שלך. נלך דרך זה לאט.
לסטטיסטיקה תיאורית יש שתי עבודות
כל תיאור של משתנה כמותי עונה על שתי שאלות. ראשית, איפה המרכז: סביב איזה ערך הנתונים מתרכזים. שנית, כמה הם מפוזרים: עד כמה רחוקות הנקודות מהמרכז. מספר אחד בלי השני הוא חצי תמונה. ממוצע בלי פיזור לא אומר לך אם כל המורות דומות זו לזו או שונות מאוד.
למשתנה קטגוריאלי (כמו סולם ליקרט או שיוך לקבוצה) העבודה קצת אחרת, ושם נכנסת שכיחות. נגיע לזה בסוף. נתחיל מהמרכז, כי שם נמצא הפער שהפחיד אותך.
הערה אחת לפני הדוגמה: הנתונים פה נוצרו במחשב והם נקיים בכוונה, כדי שהמהלך יהיה ברור. נתונים אמיתיים תמיד מבולגנים קצת יותר.
המרכז: ממוצע, חציון, ושכיח
נניח שדגמת 50 מורות ושאלת כל אחת כמה שנות ותק יש לה בהוראה. רוב המורות חדשות יחסית, אי שם בין שנתיים ל-13 שנים. אבל יש קומץ ותיקות, חמש מורות עם 25 שנות ותק ומעלה, אחת מהן עם 34. הנה שלוש דרכים לתאר את ה"מורה הטיפוסית", וכל אחת עונה על שאלה קצת אחרת.
הממוצע הוא הסכום של כל הוותקים חלקי 50. אצלנו M = 10.5 שנים. זה מרכז הכובד: אם היית שמה את כל הנתונים על קורה ומחפשת את נקודת האיזון, היא שם.
החציון הוא הערך האמצעי. סדרי את כל 50 הוותקים מהקטן לגדול, והחציון יושב בלב השורה. כשמספר המורות זוגי, כמו כאן, לוקחים את הממוצע של שני הערכים האמצעיים, ושניהם יוצאים 8. אצלנו Mdn = 8 שנים.
השכיח הוא הערך שחוזר הכי הרבה פעמים. אצלנו 8 מורות בדיוק עם 6 שנות ותק, יותר מכל ערך אחר. השכיח הוא 6.
שלושה מספרים שונים לאותו משתנה: 10.5, 8, 6. זה לא בלגן. זה בדיוק מה שקורה כשההתפלגות לא סימטרית.
למה הממוצע והחציון לא מסכימים
תסתכלי על איך הנתונים יושבים.
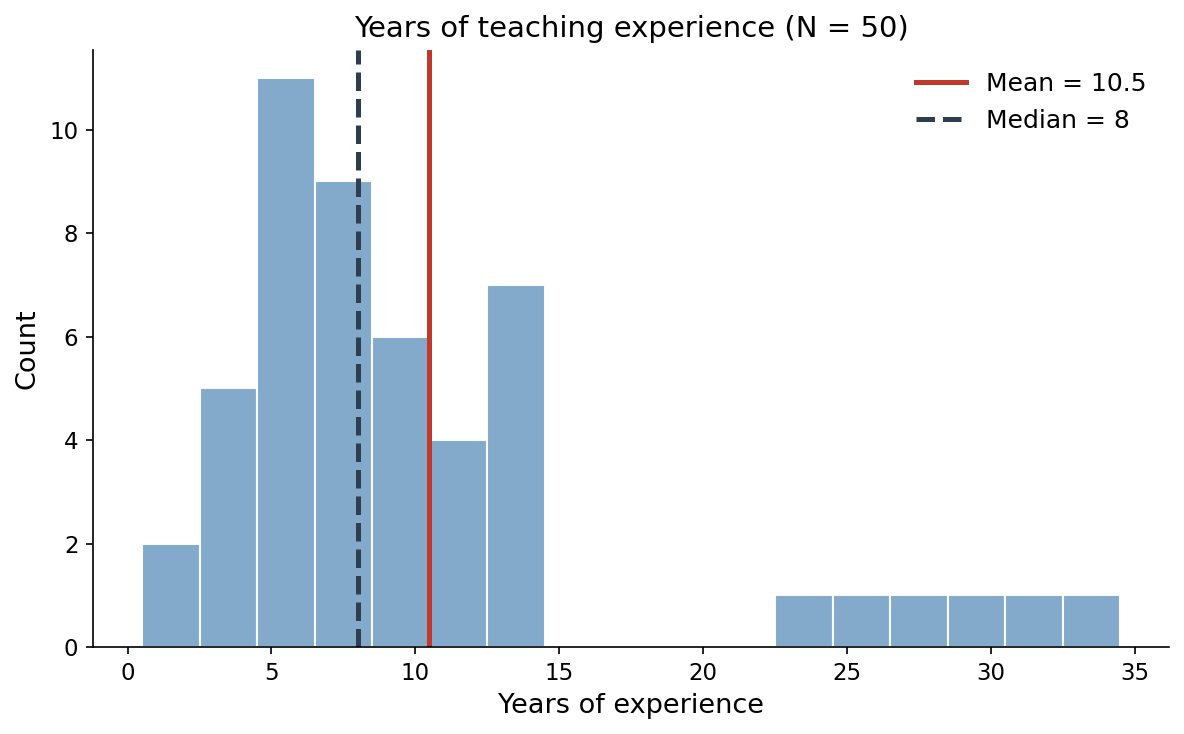
רוב המורות מצטופפות בצד שמאל, סביב 6 עד 8 שנים. 27 מתוך 50 הן בעלות ותק של 8 שנים או פחות. ואז יש זנב ארוך ודק מימין: חמש הוותיקות. ההתפלגות הזו נקראת מוטה ימינה.
הזנב הימני הזה מושך את הממוצע כלפי מעלה. הממוצע מרגיש כל מספר במדגם, אז מורה אחת עם 34 שנים מזיזה אותו יותר ממורה עם 6. החציון, לעומת זאת, סופר ראשים ולא שנים. לא משנה לו אם הוותיקה ביותר עברה 34 שנים או 134, היא עדיין רק עוד ראש אחד מעל האמצע. לכן הוא נשאר יציב על 8.
הפער כאן הוא 2.5 שנים, והכיוון שלו אומר משהו: כשהממוצע גבוה מהחציון, יש כנראה זנב ימני שמושך כלפי מעלה. בנתונים מוטים, החציון הוא לרוב התיאור הכן יותר של "המורה הטיפוסית", כי הוא לא נגרר אחרי קומץ הקצוות. אם תדווחי רק את הממוצע 10.5, מישהו עלול לדמיין סגל מנוסה בהרבה ממה שבאמת יש לך.
איזה משניהם לדווח תלוי בצורת ההתפלגות, וזה מתחבר ישירות לשאלה אם המשתנה מתפלג נורמלית או מוטה. למשתנה סימטרי בקירוב, הממוצע והחציון קרובים זה לזה, והממוצע נוח וסטנדרטי. למשתנה מוטה בבירור, כמו ותק או הכנסה, החציון לרוב מתאר את הטיפוסי טוב יותר.
הפיזור: טווח, שונות, וסטיית תקן
עכשיו לעבודה השנייה. מרכז לבד לא מספיק, כי שתי קבוצות יכולות לשבת על אותו מרכז ולהיראות שונה לגמרי.
הנה שתי כיתות, בכל אחת 10 תלמידות, ולשתיהן בדיוק אותו ממוצע מבחן M = 69.
| קבוצה | ממוצע | סטיית תקן | הציון הנמוך | הציון הגבוה |
|---|---|---|---|---|
| כיתה א' | 69 | 3.5 | 64 | 74 |
| כיתה ב' | 69 | 16.3 | 44 | 98 |
אותו מרכז, שתי מציאויות. בכיתה א' כולן צמודות סביב 69. בכיתה ב' יש מי שקיבלה 44 ומי שקיבלה 98, באותו ממוצע בדיוק. אם תדווחי רק את הממוצע, אי אפשר להבחין בין שתי הכיתות. זאת הסיבה שמרכז לבד הוא חצי סיפור.
שלושה מדדים מתארים את הפיזור הזה, מהגס למעודן:
הטווח הוא פשוט הערך הגבוה פחות הנמוך. בנתוני הוותק שלנו, 34 פחות 2, כלומר 32. קל לחשב, אבל הוא נשען רק על שתי הנקודות הקיצוניות, אז ערך חריג בודד מנפח אותו.
השונות לוקחת את המרחק של כל נקודה מהממוצע, מעלה כל מרחק בריבוע (כדי שמרחקים שליליים לא יבטלו חיוביים), וממצעת אותם (במדגם מחלקים ב-n פחות 1, וזו השונות ש-SPSS מדווח). בנתוני הוותק היא יוצאת 59. הבעיה שהיא נמדדת ב"שנים בריבוע", יחידה שאי אפשר לדמיין.
סטיית התקן פותרת את זה: היא השורש של השונות, אז היא חוזרת ליחידות המקוריות. בנתוני הוותק SD = 7.7 שנים. בעברית פשוטה, זה המרחק הטיפוסי של מורה מהממוצע. בערך כך רחוקה מורה אופיינית מ-10.5, בכיוון זה או אחר. כיתה א' למעלה עם SD = 3.5 הומוגנית, כיתה ב' עם SD = 16.3 מפוזרת. אותו מספר ראשון, סיפור שני אחר לגמרי.
שכיחות: כשהמשתנה קטגוריאלי
לא לכל משתנה הממוצע הוא התיאור הטבעי. שאלת שביעות רצון בסולם ליקרט מ-1 עד 5 היא קודם כל דירוג, לא כמות, ולכן המדד הטבעי הוא שכיחות: כמה מורות בחרו בכל רמה, ואיזה אחוז מהמדגם זה. (איזה תיאור מתאים למשתנה תלוי בסולם המדידה שלו, ועל זה יש מאמר נפרד.)
| רמת שביעות רצון | שכיחות | אחוז |
|---|---|---|
1 (כלל לא) | 3 | 6% |
2 | 5 | 10% |
3 | 7 | 14% |
4 | 22 | 44% |
5 (במידה רבה מאוד) | 13 | 26% |
הטבלה הזו אומרת מיד מה שממוצע היה מטשטש: הרמה השכיחה ביותר היא 4, ו-70% מהמורות בחרו 4 או 5. זה תיאור כן יותר של משתנה דירוגי מאשר ממוצע של 3.74, שמתייחס למרחק בין 1 ל-2 כאילו הוא זהה למרחק בין 4 ל-5, וזה לא בהכרח נכון בסולם דירוג.
מה בעצם הולך לפרק התוצאות
הכלל המעשי פשוט יותר ממה שנדמה. לכל משתנה כמותי, דווחי מרכז ומדד פיזור יחד, אף פעם לא מרכז לבד. למשתנה סימטרי בקירוב, ממוצע וסטיית תקן הם הברירה הסטנדרטית. למשתנה מוטה בבירור, החציון עם טווח או טווח בין-רבעוני מתאר את המדגם בכנות רבה יותר. אפשר גם להציג את שניהם ולתת לקורא את התמונה המלאה.
כך נראה משפט תיאור אחראי למשתנה הוותק שלנו, מוטה כפי שהוא:
"המדגם כלל50מורות. ותק ההוראה התפלג בהטיה ימינה, ולכן מתואר גם בממוצע וגם בחציון:M = 10.5, SD = 7.7, Mdn = 8, range = 2-34."
שימי לב שהמשפט הזה אף פעם לא נותן מספר מרכז בלי פיזור לידו. זה לא קישוט. זה ההבדל בין "המורות בעלות ותק של בערך 10 שנים" לבין "רובן חדשות יחסית, עם קומץ ותיקות שמושך את הממוצע מעלה". התיאור השני הוא מה שבאמת יש לך.
הסטטיסטיקה התיאורית היא לא שלב הטכני שעוברים לפני הניתוח האמיתי. היא הניתוח הראשון. היא מה שמספר לך, ולוועדה, מי באמת נמצא במדגם הזה לפני שמישהו בודק השערה אחת.