כולם אומרים "בהנחת נורמליות": מה זאת עקומת הפעמון, ולמה כל מבחן חוזר אליה

בכל פרק שיטה שקראת, בכל פגישה עם המנחה, בכל ספר לימוד, חוזרת אותה שורה: "בהנחת נורמליות", "בהנחה שההתפלגות נורמלית". את מהנהנת. את כותבת את זה גם בעבודה שלך. ואז, מתישהו, המנחה מבקש להריץ מבחן Shapiro-Wilk כדי לבדוק את ההנחה הזאת, ואת מריצה אותו, ומקבלת מספר, ועדיין אף אחד לא עצר רגע להגיד לך מה זאת בעצם ההתפלגות הזאת. איך היא נראית. ולמה למבחן סטטיסטי בכלל אכפת מהצורה של הנתונים שלך.
זאת השאלה שמתחת לכל השאלות. בואי נלך דרכה לאט.
מה זאת בכלל "התפלגות נורמלית"
קחי משתנה אחד. נניח ציון של מבחן מוכנות לקריאה בכיתה א'. אם תציירי כמה תלמידים קיבלו כל ציון, ותקבלי צורה מסוימת, חוזרת ומוכרת, קוראים לה ההתפלגות הנורמלית. בעברית גם "עקומת הפעמון", כי זה מה שהיא נראית: פעמון.
שלושה דברים מאפיינים אותה. היא סימטרית, כלומר הצד הימני הוא בבואה של הצד השמאלי. יש לה שיא אחד במרכז, ולא שני גבשושיות. והערכים מתקבצים סביב המרכז ונעשים נדירים יותר ויותר ככל שמתרחקים ממנו לשני הכיוונים. רוב התלמידים סביב הממוצע, מעטים מאוד בקצוות. אלה הסימנים שמזהים פעמון בעין, לא הגדרה מתמטית מלאה, אבל בשביל האינטואיציה הם בדיוק מה שצריך.
בהתפלגות נורמלית מושלמת, שלושת מדדי המרכז, הממוצע, החציון, והשכיח, יושבים כולם באותה נקודה: בדיוק בשיא הפעמון. זה לא קורה במקרה. זה נובע מהסימטריה ומצורת הפעמון בעלת השיא היחיד.
שני מספרים, וזהו
הדבר היפה, וגם השימושי, בהתפלגות הנורמלית, הוא שכדי לתאר אותה במלואה צריך בדיוק שני מספרים.
הראשון הוא הממוצע (μ). הוא קובע איפה יושב השיא של הפעמון על ציר המספרים. השני הוא סטיית התקן (σ). היא קובעת כמה רחב הפעמון. סטיית תקן קטנה נותנת פעמון צר וגבוה, כל התלמידים קרובים לממוצע. סטיית תקן גדולה נותנת פעמון רחב ושטוח, התלמידים מפוזרים הרבה יותר.
אותו ממוצע בדיוק, עם סטיית תקן גדולה יותר, ייתן עקומה רחבה ונמוכה יותר. זה כל ההבדל. שני מספרים מגדירים את כל הצורה. וזאת בדיוק הסיבה שהמסר החוזר בבלוג הזה, שמספר אחד אף פעם לא מספיק, חי כאן בצורה הכי נקייה: מרכז בלי פיזור לא אומר לך כמעט כלום על איך הנתונים שלך באמת מתפזרים.
הכלל של 68-95-99.7
מכיוון ששני מספרים מגדירים את הכל, אפשר לדעת מראש איזה חלק מההתפלגות נופל בכל מרחק מהממוצע. זה הכלל שכדאי לזכור, והוא נכון לכל התפלגות נורמלית, לא משנה הממוצע או סטיית התקן.
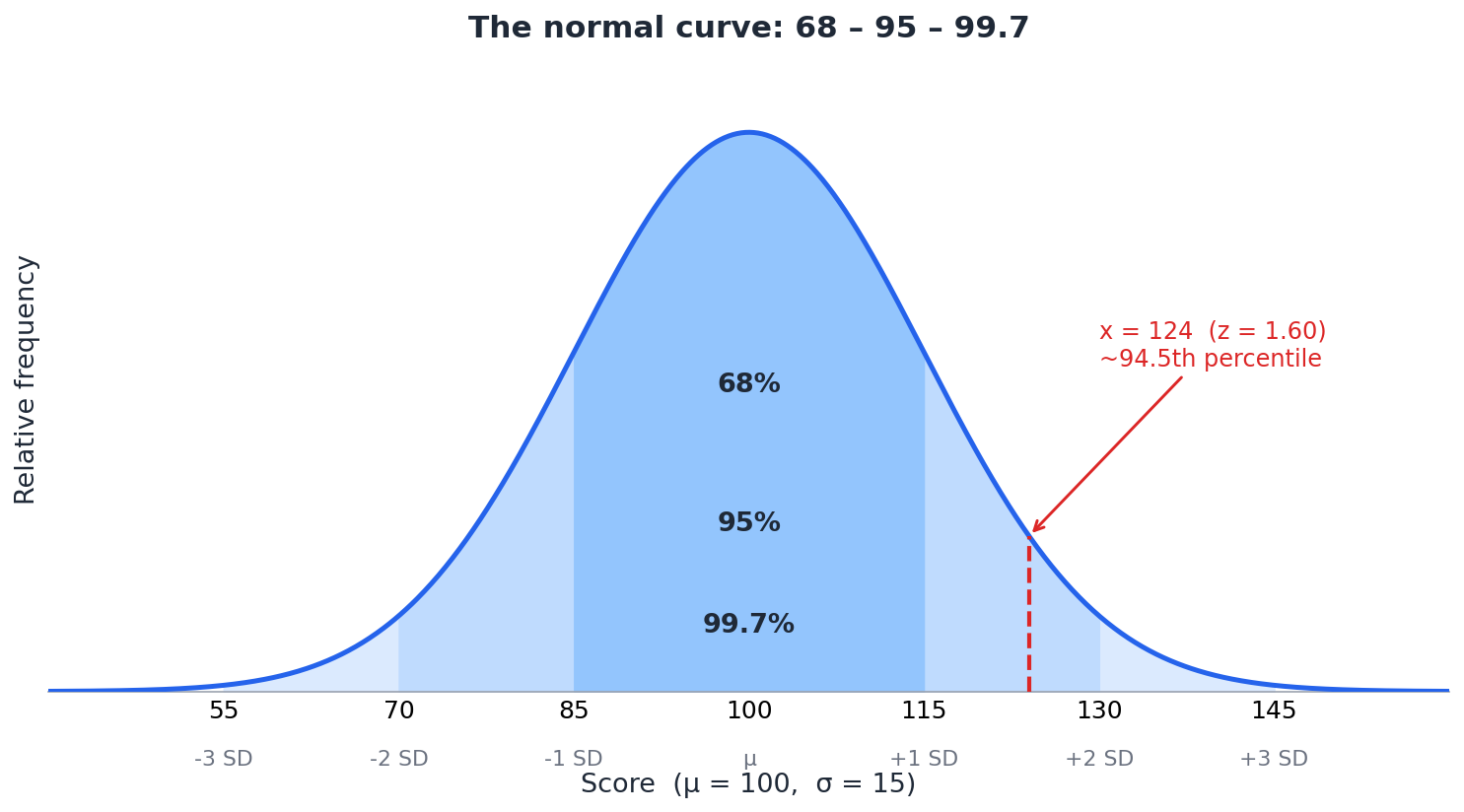
בתוך סטיית תקן אחת מהממוצע, לכל כיוון, נופלים בערך 68% מהערכים. בדיוק יותר, 0.6827. בתוך שתי סטיות תקן, בערך 95% (0.9545). בתוך שלוש, בערך 99.7% (0.9973), כמעט הכל.
נחזיר את זה לציון מוכנות לקריאה, בסולם נקי בכוונה שבו μ = 100 ו-σ = 15. זה סולם "ספר לימוד", עגול ונוח. בנתונים אמיתיים המספרים לרוב לא יוצאים כל כך חלקים. אבל הוא נוח כדי לראות את המבנה.
סטיית תקן אחת מ-100 היא 15. אז:
| מרחק מהממוצע | טווח ציונים | חלק מהתלמידים |
|---|---|---|
±1 SD | 85 – 115 | ~68% |
±2 SD | 70 – 130 | ~95% |
±3 SD | 55 – 145 | ~99.7% |
כך זה נראה, עם שלוש הרצועות מקוננות זו בתוך זו:
ציון התקן: מספר אחד שאומר "כמה רחוק מהמרכז"
עכשיו נוסחה אחת, ואז נתרגם אותה לעברית. אם תלמידה קיבלה ציון מסוים, ואת רוצה לדעת כמה הוא חריג, את שואלת: כמה סטיות תקן הוא מהממוצע. זה ציון התקן, ה-z.
z = (x − μ) / σ
בעברית: לוקחים את הציון, מחסירים את הממוצע, ומחלקים בסטיית התקן. נניח שתלמידה קיבלה 124. אז z = (124 − 100) / 15 = 1.60. הציון שלה נמצא 1.6 סטיות תקן מעל הממוצע.
אבל z לבדו עוד לא אומר לך הרבה. ערך של 1.60 הוא מספר מופשט. הכוח האמיתי מגיע כשמתרגמים אותו לאחוזון, כלומר לשטח מתחת לעקומה משמאל לציון הזה. השטח הזה הוא בדיוק החלק מההתפלגות שמתחת לציון שלה. את המספר הזה לא מחשבים מנוסחת ה-z עצמה, אלא קוראים מטבלת ההתפלגות הנורמלית התקנית או מהתוכנה. עבור z = 1.60, השטח יוצא 0.9452.
וזה כבר משפט שאפשר לכתוב בעבודה, או לומר להורה: לפי המודל הנורמלי, התלמידה הזאת קיבלה ציון גבוה מ-94.5% מההתפלגות. היא באחוזון ה-94.5 בערך, מעוגל כמעט ל-95. ציון התקן הפך מספר בודד וחסר הקשר לאמירה על מיקום יחסי. כשרוצים להסביר מיקום, כדאי להצמיד ל-z את האחוזון: ה-z מספר כמה סטיות תקן, והאחוזון הופך אותו לאמירה על איפה התלמידה עומדת ביחס לשאר.
למה ההסקה הסטטיסטית כל הזמן חוזרת לפה
אז למה כל מבחן שני מזכיר נורמליות. כי הרבה מהכלים שאת משתמשת בהם נשענים, בצורה כזו או אחרת, על קירוב לנורמליות. לפעמים זאת הנחה על המשתנה עצמו, לפעמים על השאריות של מודל רגרסיה, ולפעמים, וזה החלק העמוק, על התפלגות הממוצע עצמו על פני דגימות חוזרות.
הנקודה האחרונה היא הסיבה שבגללה מבחן שמבוסס על ממוצע יכול להתנהג יפה גם כשהנתונים הגולמיים קצת לא נורמליים. יש רעיון בסטטיסטיקה, משפט הגבול המרכזי, שאומר שממוצעים של דגימות נוטים להתקרב לצורה נורמלית גם כשהמשתנה המקורי לא ממש כזה. זאת אינטואיציה חשובה, אבל לא ערובה. היא תלויה בגודל המדגם ובמידת הסטייה, והיא מדברת על הממוצע, לא על כל סטטיסטיקה שתחשבי.
וכאן צריך להיות זהירה. אף משתנה אמיתי הוא לא נורמלי בדיוק. הצורה תלויה גם בסולם המדידה של המשתנה: ציון מבחן הוא בדיד וחסום, גיל הוא חיובי בלבד, סולם דירוג נעצר ב-1 וב-5. השאלה המעשית כמעט אף פעם אינה "האם הנתונים נורמליים", כי בנתונים אמיתיים הם כמעט תמיד לא נורמליים בדיוק. השאלה היא "האם הקירוב מספיק טוב להסקה שאני רוצה לעשות". וזאת בדיוק השאלה שמבחן כמו Shapiro-Wilk מתחיל לתת עליה אינדיקציה, בלי להכריע אותה לבדו. הצורה של ההתפלגות, גודל המדגם וקיומם של חריגים נכנסים כולם לשיקול.
בגלל זה גם רווחי הסמך שאת מדווחת נשענים על אותו רעיון: רוחב הרווח נגזר מסטיית התקן, מגודל המדגם, ומהקירוב הנורמלי של התפלגות הממוצע. ברגע שמבינים את הפעמון, חלק גדול מההסקה מפסיק להיות קסם.
מה לקחת מפה
ההתפלגות הנורמלית היא לא חוק טבע שהנתונים שלך חייבים לציית לו. היא מודל, צורה אחת, נקייה וסימטרית, שמוגדרת לגמרי על ידי ממוצע וסטיית תקן. מתוך שני המספרים האלה נובע הכל: איפה יושב השיא, כמה רחב הפעמון, איזה חלק מהנתונים נופל בכל טווח, ובאיזה אחוזון יושבת תלמידה עם ציון מסוים.
בפעם הבאה שתקראי "בהנחת נורמליות", לא תהיה זאת עוד שורה שעוברים מעליה. תדעי בדיוק על איזו צורה מדברים, ולמה למבחן אכפת ממנה. ומשם, כשהמנחה יבקש לבדוק את ההנחה, יהיה לך הרבה יותר ברור מה בעצם בודקים, וכמה קרוב הנתונים שלך צריכים להיות לפעמון הזה כדי שהכל יחזיק.