ניתוח גורמים, חלק ב: איך קוראים את הפלט, מ-KMO ועד הסיבוב

הרצת ניתוח גורמים. עשית בדיוק מה שהמנחה ביקש, ועכשיו על המסך דף שלם של פלט. למעלה שני מספרים עם שמות מוזרים, KMO ו-Bartlett. אחריהם טבלה של ערכים עצמיים. גרף שיורד ומתיישר. ובסוף, התוכנה שואלת אותך באיזה סוג סיבוב לבחור, varimax או משהו שנקרא oblimin, כאילו את אמורה לדעת.
בפוסט הקודם ראינו מה זה גורם. דבר חבוי שמושך כמה פריטים לזוז יחד. עכשיו את יושבת מול הפלט עצמו וצריכה לקרוא אותו. בואי נעבור עליו מלמעלה למטה, שורה אחר שורה, ונראה על מה באמת צריך להסתכל ומה אפשר לדלג עליו.
נשתמש באותו מחקר מהפוסט הקודם. אותו שאלון, שישה פריטים על תחושת המורה בעבודה, שלושה על שחיקה רגשית (E) ושלושה על תחושת הישג (A), 200 משיבות.
שאלה ראשונה: המדגם בכלל מתאים לזה?
לפני שסופרים גורמים, התוכנה בודקת דבר בסיסי יותר. האם בנתונים האלה יש בכלל מספיק מבנה כדי שניתוח גורמים יהיה הגיוני. שני המספרים שבראש הפלט עונים על זה.
הראשון הוא מבחן הכדוריות של Bartlett. הוא שואל שאלה אחת: האם הפריטים מתואמים זה עם זה בכלל, או שאין במטריצת המתאמים שלך שום קשר, כל פריט בלתי תלוי בשאר. אם הפריטים לא מתואמים, אין שום אשכולות לחפש, ואין מה לנתח. בנתונים שלנו המבחן יצא χ²(15) = 302.6, p < .001. כלומר יש מתאמים, ובגדול. זה מה שרצינו לראות.
נקודה חשובה אחת לגביו: זה מבחן חשוב, אבל רף נמוך. כמעט כל מדגם בגודל סביר יעבור את Bartlett, כי כמעט תמיד יש מתאם כלשהו בין הפריטים. אז תוצאה מובהקת כאן היא לא הישג, היא תנאי מינימום. אם היא דווקא לא מובהקת, זה דגל אדום אמיתי שאומר לעצור.
המספר השני עובד קשה יותר. הוא נקרא KMO, מדד קייזר-מאייר-אולקין, והוא בודק אם המתאמים בין הפריטים מצטרפים לתבנית משותפת רחבה, כזאת שגורם חבוי יכול להסביר, או שהם בעיקר קשרים מקומיים בין זוגות פריטים. ככל שהמתאמים מצטרפים לתבנית משותפת, KMO גבוה יותר, והנתונים מתאימים יותר לניתוח גורמים. הוא נע בין 0 ל-1.
אצלנו KMO יצא 0.70. הנה איך קוראים אותו: מתחת ל-0.5 הנתונים לא מתאימים, וכדאי לעצור. בין 0.6 ל-0.7 זה התחום שרובם המוחלט של המקורות מקבלים. מ-0.8 ומעלה זה נחשב מצוין. 0.70 שלנו הוא ערך סביר ומספק: עובר את הרף המקובל, ויושב על הקו שחלק מהמקורות המחמירים דורשים. לא יופי של מדגם, אבל בהחלט כזה שאפשר להמשיך איתו ולכתוב את זה בלי להתנצל.
יש גם KMO לכל פריט בנפרד (לפעמים קוראים לו MSA). שווה מבט חטוף: אם לפריט בודד יוצא KMO נמוך במיוחד, מתחת ל-0.5, זה הפריט שהכי לא מסתדר עם השאר, ואולי כדאי לשקול להוציא אותו. אצלנו הנמוך ביותר היה 0.65, כולם בסדר.
שאלה שנייה: כמה גורמים, הפעם כמו שצריך
בפוסט הקודם ספרנו את הגורמים בכלל אצבע מהיר, כלל קייזר: כל ערך עצמי גדול מ-1 הוא גורם. הערכים העצמיים שלנו היו 2.35, 1.72, ואז צניחה ל-0.56, 0.52, 0.46, 0.40. שניים מעל אחד, אז שני גורמים. אמרתי אז שזה סימן ראשוני, לא הכרעה. עכשיו נראה למה, ומה הדרך הרצינית יותר.
הבעיה עם כלל קייזר היא שהוא נדיב מדי. גם נתונים אקראיים לגמרי, בלי שום מבנה, מייצרים ערכים עצמיים, וכמה מהראשונים בהם מטפסים מעל 1 רק מרעש דגימה. כלל שמשווה ל-1 סופר לפעמים גורם שהוא בכלל מקריות. בדוגמה נקייה כמו שלנו הוא צודק, אבל בנתונים אמיתיים הוא נוטה לספור גורמים מדומים.
שתי שיטות טובות יותר מסתכלות על אותם ערכים עצמיים אחרת. הנה שתיהן על גרף אחד.
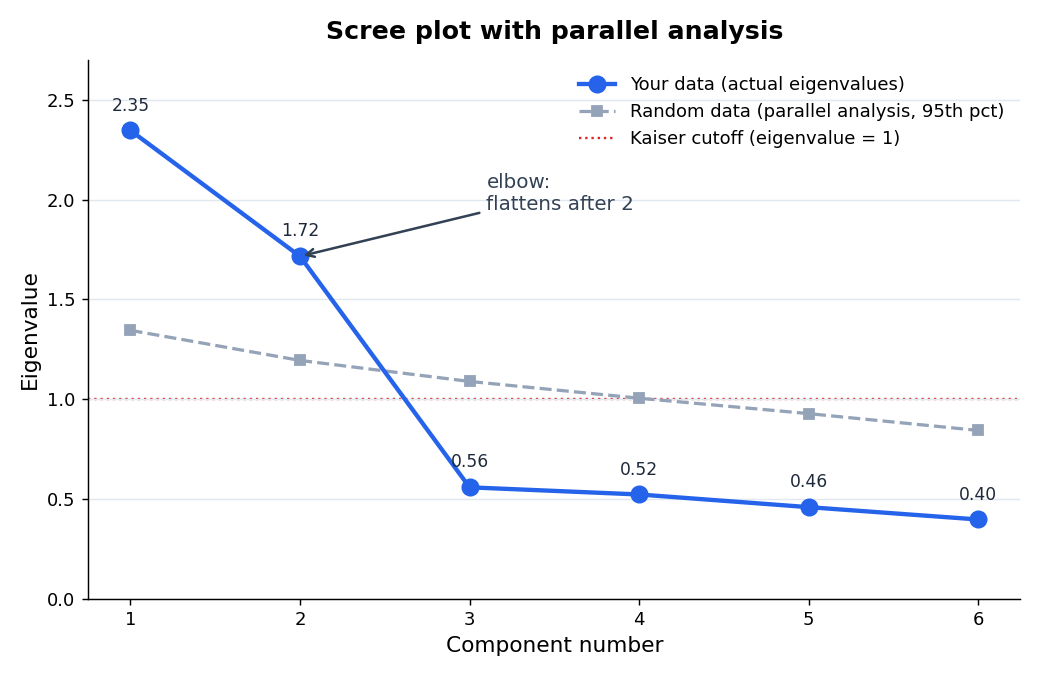
הראשונה היא תרשים ה-scree, הקו הכחול. פשוט מציירים את הערכים העצמיים לפי הסדר ומחפשים את המרפק, הנקודה שאחריה הקו נשבר ומתיישר. לפני המרפק הגורמים נושאים מידע ממשי. אחריו מתחיל ה"חצץ", scree בלעז, רכיבים שכל אחד תורם קצת ובערך אותו דבר. אצלנו המרפק חד: הקו צולל בין רכיב 2 לרכיב 3, מ-1.72 ל-0.56, ואז זוחל. שני גורמים לפני השבירה.
השיטה השנייה היא היפה באמת, ונקראת ניתוח מקביל (parallel analysis), הקו האפור המקווקו. הרעיון: ניקח את אותו גודל מדגם בדיוק, 200 משיבות ו-6 פריטים, אבל ניצור נתונים אקראיים לחלוטין, בלי שום גורם חבוי בבסיסם. נחשב את הערכים העצמיים שלהם. נחזור על זה מאות פעמים, ונקבל קו של "מה רעש טהור היה נותן לי". ואז הכלל פשוט: כדאי לשמר גורם רק אם הערך העצמי שלו מטפס מעל מה שהרעש לבדו היה מייצר.
תראי מה זה עושה לסף. הרעש לא עוצר ב-1. ברכיב הראשון הוא מטפס עד 1.35, וברכיב השני עד 1.19, כי דווקא הערכים העצמיים הגדולים הם אלה שהמקריות מנפחת. הנתונים שלנו עוברים את הרף הזה בקלות בשני הרכיבים הראשונים (2.35 ו-1.72, הרבה מעל האפור), ונופלים מתחתיו כבר ברכיב השלישי (0.56 לעומת 1.09). התשובה שוב שניים, אבל הפעם היא נבחנה מול רף מבוסס, לא מול 1 שרירותי.
פה כל שלוש השיטות הסכימו, וזה כי המבנה נקי. הערך של ניתוח מקביל מתגלה כשהן לא מסכימות. כשקייזר אומר ארבעה גורמים ותרשים ה-scree מהסס, ניתוח מקביל הוא בדרך כלל ההכרעה השקטה והאמינה. אם התוכנה שלך מציעה אותו, בחרי בו.
הערה טכנית קטנה לפני שממשיכים. הערכים העצמיים שראינו, וגם הקו של הניתוח המקביל, מחושבים כאן על בסיס רכיבים, ולכן בגרף כתוב "component". יש תוכנות שמחשבות אותם על בסיס מודל הגורמים עצמו, והמספרים יוצאים מעט שונים. שתיהן יכולות לשמש ככלי החלטה למספר הגורמים, כל עוד ברור מה חושב ומה מדווח. מה שבאמת חשוב הוא לציין בדיווח באיזו שיטת חילוץ בחרת לחלץ את הגורמים, למשל ציר ראשי (principal axis) או נראות מרבית (maximum likelihood). בדוגמה כאן החילוץ נעשה בשיטת שאריות מינימליות (minres).
שאלה שלישית: איזה סיבוב
נשארה השאלה שהתוכנה שאלה אותך, על הסיבוב. קודם דבר אחד על הסדר: אחרי שהחלטנו לשמור שני גורמים, התוכנה מחלצת פתרון של שני גורמים, ורק אז מסובבת אותו. כדי להבין למה בכלל צריך לסובב, צריך לראות איך נראות הטעינויות לפני הסיבוב. הנה הפתרון הלא מסובב של שני הגורמים:
| פריט | גורם 1 | גורם 2 |
|---|---|---|
| E1 | 0.56 | 0.50 |
| E2 | 0.48 | 0.49 |
| E3 | 0.49 | 0.47 |
| A1 | 0.60 | -0.54 |
| A2 | 0.61 | -0.27 |
| A3 | 0.60 | -0.42 |
נסי לקרוא את זה. כל הפריטים, גם E וגם A, טוענים חזק על גורם 1. הוא הפך לגורם "כללי" שכולם נתלים בו, וההבדל בין שתי הקבוצות נדחק לגורם 2. אי אפשר להסתכל על הטבלה הזאת ולומר "אלה שני תת-סולמות". המבנה קיים בנתונים, אבל הצירים מונחים בזווית לא נוחה, והוא מטושטש.
זה כל מה שסיבוב עושה. הוא מסובב את שני הצירים, בלי לשנות את הנתונים בכלל, עד שכל פריט יישען חזק על ציר אחד וכמעט אפס על השני. אותו מבנה בדיוק, רק מוגש בצורה קריאה. למבנה הקריא הזה קראנו בפוסט הקודם מבנה פשוט.
ופה מגיעה הבחירה. יש שתי משפחות של סיבוב, וההבדל ביניהן הוא שאלה אחת: האם מותר לשני הגורמים להיות מתואמים זה עם זה.
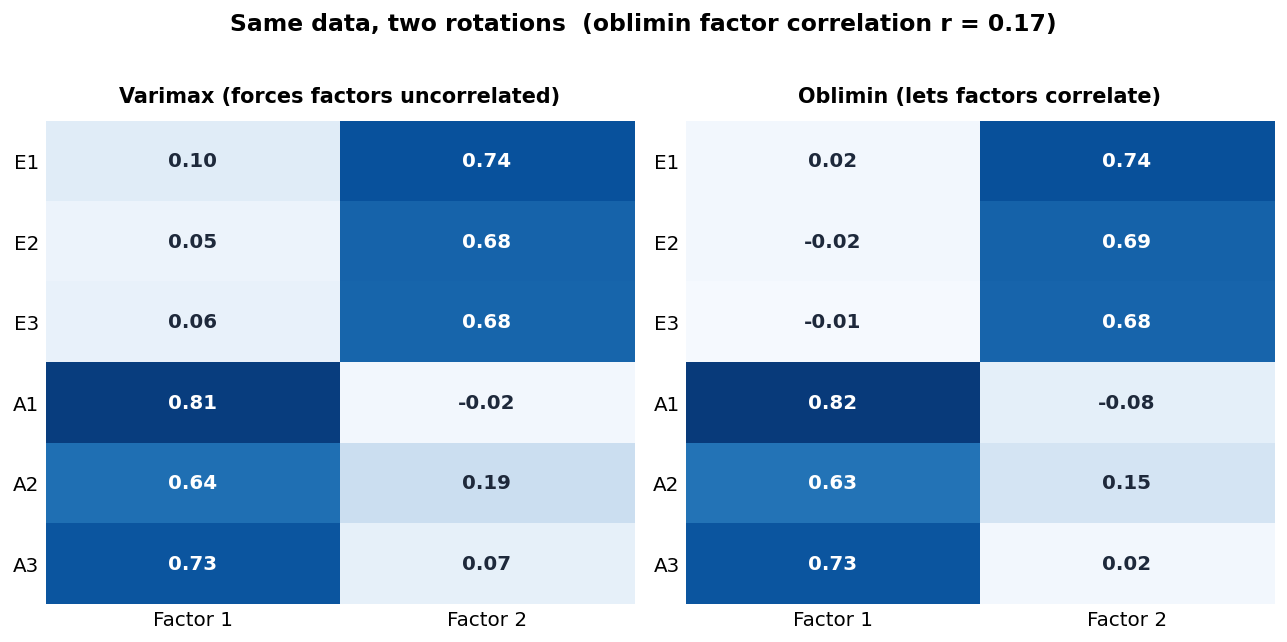
סיבוב ניצב (varimax, משמאל) מכריח את שני הצירים להישאר בזווית של 90 מעלות זה לזה. כלומר מניח שהגורמים בלתי מתואמים לחלוטין. נוח, נקי, וקל לדיווח. אבל זו הנחה, לא ממצא.
סיבוב אלכסוני (oblimin, מימין) מרשה לצירים להתקרב זה לזה אם הנתונים מבקשים, כלומר מאפשר לגורמים להיות מתואמים. וזאת בדרך כלל ההנחה הריאליסטית יותר במדעי החברה. שחיקה רגשית ותחושת הישג הן לא שני דברים מנותקים, הן קשורות. למה להכריח אותן לזווית של 90 מעלות אם במציאות הן משתנות יחד. (הטבלה שמדווחים בסיבוב אלכסוני נקראת מטריצת ה-pattern. יש לצידה גם טבלת structure, ולא ניכנס כאן להבדל ביניהן.)
הדבר היפה ב-oblimin הוא שהוא נותן לך מספר נוסף שאין ל-varimax: את המתאם בין הגורמים עצמם. אצלנו הוא יצא 0.17. כלומר שני הממדים קשורים, אבל קשר חלש. וזאת בדיוק התשובה שמדריכה את הבחירה: כשהמתאם בין הגורמים קטן כל כך, שתי הטבלאות יוצאות כמעט זהות (תראי בעצמך, הטעינויות החזקות כמעט לא זזו), ושתיהן לגיטימיות לחלוטין. זה המצב אצלנו. אבל כשהמתאם בין הגורמים גדול, נניח סביב 0.30 ומעלה, varimax מעוות את התמונה כדי לשמור על 90 המעלות, ואז עדיף לדווח oblimin.
אז הכלל המעשי פשוט: הריצי oblimin. אם המתאם בין הגורמים יצא קטן, לא הפסדת כלום, ויש לך אפילו ראיה שמותר היה לפשט. אם הוא יצא גדול, טוב שלא הכרחת זווית שלא קיימת בנתונים.
ועוד דבר על הטעינויות, שמבלבל בהתחלה: הסימן שלהן שרירותי. אותה תוצאה בדיוק יכולה להופיע עם כל הטעינויות על גורם הפוכות בסימן, פלוס במקום מינוס, בלי שום שינוי במשמעות. אם אצל חברה ללימודים אותו גורם יצא עם סימנים הפוכים, אף אחת מכן לא טעתה. זאת מוסכמה של התוכנה, לא ממצא.
ולקרוא את הטבלה הסופית
אחרי שבחרת סיבוב, נשארת לפנייך טבלת הטעינויות, ויש שלושה דברים שמסתכלים עליהם בה.
קודם, הטעינות הראשית של כל פריט. כלל אצבע נפוץ: טעינות מעל 0.40 (יש שמחמירים ל-0.50) נחשבת מספיק חזקה כדי לומר שהפריט "שייך" לגורם. אצלנו כל הפריטים מעל 0.62 על הגורם שלהם, חזק ויפה.
שנית, טעינויות צולבות. לא מספיק שהטעינות הראשית תהיה גבוהה, כדאי שיהיה גם פער ברור בינה לבין הטעינות המשנית. פריט שטוען 0.55 על גורם אחד ו-0.45 על השני הוא פריט בעייתי שלא יודע לאן הוא שייך, גם אם 0.55 נשמע גבוה כשלעצמו. כלל אצבע נפוץ דורש פער של לפחות 0.2 בין הראשית למשנית. אצלנו אין בעיה כזאת, הטעינות המשנית הגבוהה ביותר נשארת מתחת ל-0.2, הרבה מתחת לטעינויות הראשיות. בנתונים אמיתיים, פריט עם טעינות צולבת גבוהה הוא מועמד להוצאה.
שלישית, יש מספר ששמו שיתופיות (communality), אחד לכל פריט, שאומר כמה מהשונות של הפריט שני הגורמים מצליחים להסביר. פריט עם שיתופיות נמוכה מאוד, נניח מתחת ל-0.2, הוא פריט שכמעט לא קשור לשום גורם, ושוקלים להוציא גם אותו. אצל פריטי הדוגמה שלנו השיתופיות נעה בערך בין 0.45 ל-0.65, סביר לגמרי.
איך כותבים את זה בפרק השיטות
כל מה שעברנו עליו מתכווץ לכמה משפטים מסודרים. קודם ההתאמה, אחר כך מספר הגורמים והשיטה שקבעה אותו, אחר כך הסיבוב, ובסוף הממצא.
"התאמת הנתונים לניתוח גורמים נבדקה ונמצאה מספקת (KMO = 0.70; מבחן הכדוריות של Bartlett: χ²(15) = 302.6, p < .001). מספר הגורמים נקבע על פי ניתוח מקביל ותרשים scree, ושניהם הצביעו על שני גורמים. שני הגורמים חולצו בשיטת שאריות מינימליות (minres), ועליהם הופעל סיבוב אלכסוני (oblimin); המתאם בין הגורמים היה r = 0.17. פתרון שני הגורמים הסביר יחד 52% מהשונות, וכל הפריטים נטענו על הגורם התאורטי שלהם בטעינות שמעל 0.62, ללא טעינויות צולבות."
שימי לב מה יש שם ומה אין. יש את ארבעת המספרים שבודק רוצה לראות, ואת ההחלטות שקיבלת ולמה. אין שם הסבר מה זה ערך עצמי, ואין התנצלות. את מדווחת מה עשית ומה יצא, בשורות ספורות.
וזה כל הפלט. KMO ו-Bartlett אומרים אם בכלל להתחיל. ניתוח מקביל ותרשים scree אומרים כמה גורמים. הסיבוב הופך את הטעינויות לברורות, ו-oblimin מגלה לך תוך כדי כמה הגורמים קשורים. כל מספר בדף ענה על שאלה אחת, ועכשיו את יודעת על מה כל אחד מהם עונה.
נשאר חוט אחד פתוח. בכל מה שעשינו כאן נתנו לנתונים להציע את המבנה, ושאלנו אותם כמה גורמים יש. אבל מה אם כבר יש לך מבנה בראש, מתוך התאוריה או מתוך מאמר, ואת רוצה לבדוק אם הנתונים מתיישבים דווקא איתו. זאת שאלה אחרת, וכלי אחר, ניתוח גורמים מאשש (CFA). הוא התחנה הבאה בסדרה.