מבחן Fisher's exact: מה עושים כשהתאים קטנים מדי לחי-בריבוע

הרצת מחקר קטן. קבוצת התערבות, קבוצת ביקורת, וכל מה שרצית לדעת הוא אם יותר תלמידים הגיעו ליעד בקבוצה שקיבלה את ההתערבות. הרצת Crosstabs ב-SPSS, וקיבלת טבלה עם הרבה שורות. אחת מהן נקראת Pearson Chi-Square, ומתחתיה יש שורה שנייה, Fisher's Exact Test, עם p משלה. ולמטה הערה קטנה: חלק מהתאים בעלי שכיחות צפויה קטנה מ-5.
שתי שורות, שני p שונים. השאלה היא איזו מהן לדווח. וההערה הקטנה למטה היא בדיוק התשובה.
למה חי-בריבוע מתחיל לגמגם כשהמדגם קטן
מבחן חי-בריבוע עובד בשיטה שכבר ראית. הוא משווה את מה שנצפה בפועל למה שהיינו מצפים אם אין שום קשר, ומסכם את הפער במספר אחד. אבל כדי להפוך את המספר הזה ל-p, הוא עושה קיצור דרך: הוא מניח שהפער מתפזר לפי עקומה חלקה ומוכרת, ופשוט קורא את ה-p מהעקומה.
הקיצור הזה מצוין כשהמדגם גדול. העקומה החלקה היא קירוב טוב למציאות. אבל כשהספירות קטנות, הנתונים שלך קופצים במדרגות שלמות, תלמיד פה, תלמיד שם, והעקומה החלקה כבר לא יושבת עליהם. ה-p שמתקבל ממנה פשוט לא מדויק. לפעמים קטן מדי, לפעמים גדול מדי, תלוי בטבלה. אי אפשר לדעת לאיזה כיוון, ולכן אי אפשר לסמוך עליו.
כלל האצבע שמסמן את הרגע הזה ידוע בשם כלל Cochran. בניסוח המלא הוא מתיר עד כחמישית מהתאים בעלי שכיחות צפויה מתחת ל-5, אבל בטבלת 2 על 2 יש רק ארבעה תאים, אז אפילו תא אחד מתחת ל-5 כבר חורג מהכלל, ואז נהוג לעבור ל-Fisher. נראה את זה במספרים.
הנתונים
תוכנית קצרה לקידום מודעות פונולוגית. עשרה תלמידים בקבוצת ההתערבות, תשעה בקבוצת הביקורת, והשאלה היא מי הגיע לרף המיומנות בסוף.
| הגיע לרף | לא הגיע | סה"כ | |
|---|---|---|---|
| התערבות | 8 | 2 | 10 |
| ביקורת | 2 | 7 | 9 |
| סה"כ | 10 | 9 | 19 |
בקבוצת ההתערבות הגיעו לרף 8 מתוך 10, שמונים אחוז. בביקורת 2 מתוך 9, עשרים ושניים אחוז. ההבדל נראה גדול. אבל המדגם כולו הוא תשעה-עשר ילדים, וכאן צריך להיזהר.
השכיחויות הצפויות, אם אין קשר בין הקבוצה לבין ההגעה לרף, יוצאות 5.26 ו-4.74 בשורה אחת, 4.74 ו-4.26 בשנייה. בשלושה מתוך ארבעה תאים השכיחות הצפויה קטנה מ-5. כלל Cochran מופר בגדול. זאת ההערה הקטנה ש-SPSS רשם לך למטה, וזאת הסיבה שאין להסתמך על ה-p של שורת חי-בריבוע.
מה ש"מדויק" באמת אומר
השם Fisher's exact test נשמע טכני, אבל המילה החשובה בו היא "מדויק", והיא מתארת בדיוק את ההבדל. חי-בריבוע מקרב. Fisher סופר.
הנה הרעיון, והוא יפה. ארבעת הסכומים בשוליים של הטבלה הם מה שכבר ראית בפועל, והם לא במחלוקת: עשרה בהתערבות, תשעה בביקורת, עשרה הגיעו לרף, תשעה לא. השאלה היחידה היא איך עשרת המגיעים לרף מתחלקים בין שתי הקבוצות. אז משאירים את השוליים קבועים ושואלים רק את זה.
וכאן הדבר הנוח: בהינתן השוליים, כל הטבלה נקבעת על ידי מספר אחד בלבד, התא השמאלי העליון. ברגע שתחליטי כמה מההתערבות הגיעו לרף, שאר שלושת התאים נגזרים מהשוליים. אין להם חופש.
אז במקום עקומה, Fisher שואל שאלה ישירה. אילו טבלאות בכלל אפשריות עם השוליים האלה, וכמה נדירה הטבלה שלך מביניהן. התא השמאלי העליון יכול לקבל כל ערך מ-1 עד 10, אז יש בדיוק עשר טבלאות אפשריות. לכל אחת מהן יש הסתברות מדויקת להופיע, אם החלוקה לקבוצות לא קשורה לתוצאה. את ההסתברות הזאת מחשבים בנוסחה מדויקת, בלי שום קירוב, וזה כל הסוד שמאחורי המילה exact.
חשוב להבין שעשר הטבלאות אינן שוות בסבירותן. חלוקה מאוזנת, חמישה וחמישה, סבירה הרבה יותר מחלוקה קיצונית של עשרה ואפס. לכל טבלה משקל משלה. לכן בהמשך לא נספור כמה טבלאות קיצוניות יש, אלא נחבר את המשקלים שלהן.
הטבלה שלך, 8 מתוך 10, היא אחת מהעשר. ההסתברות שלה לבדה היא 0.0175.
איך מרכיבים את ה-p
עכשיו הצעד שהופך את עשר ההסתברויות ל-p אחד. ה-p של Fisher הוא הסכום של ההסתברויות של כל הטבלאות שהן נדירות כמו שלך, או נדירות ממנה. לא רק שלך, אלא כל מה שקיצוני לפחות כמותה, לשני הכיוונים. השאלה שלך נשמעת חד-כיוונית, מי הגיע יותר. ובכל זאת, כברירת מחדל מדווחים דו-צדדי, במיוחד כשהכיוון לא הוגדר והוצהר מראש. מבחן חד-צדדי עונה על שאלה אחרת, מצומצמת יותר, שמתאימה רק אם קבעת את הכיוון לפני שראית את הנתונים. לכן כאן סופרים קיצוניות לשני הצדדים.
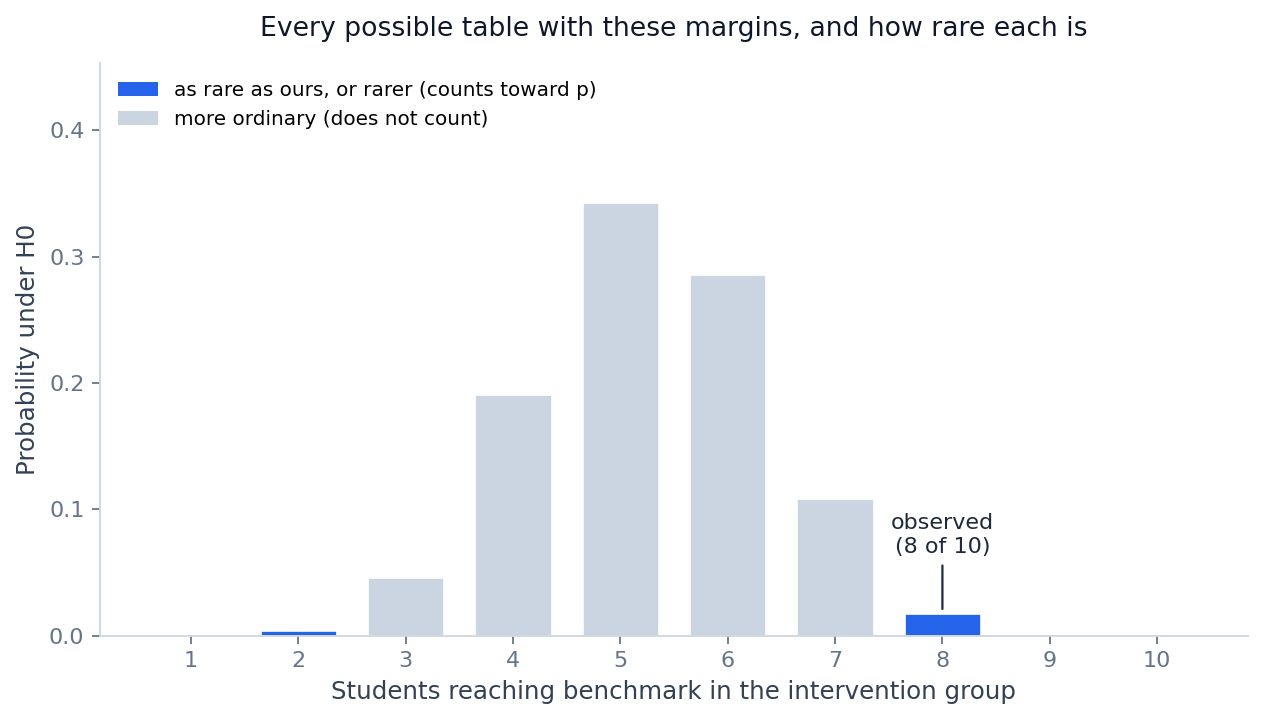
רוב ההסתברות יושבת באמצע, סביב חמישה תלמידים, שזה בערך מה שהיינו מצפים אם אין קשר. הטבלה שלך, עם שמונה, יושבת רחוק בקצה. צובעים בכחול את כל הטבלאות שנדירות כמוה או יותר, מחברים את הגבהים שלהן, ומקבלים:
Fisher's exact test, p = .023 (דו-צדדי)
זה הכול. אין דרגות חופש, אין עקומה, אין קירוב. רק רשימה של כל מה שיכול היה לקרות עם אותם שוליים, וחיבור המשקלים של כל מה שקיצוני לפחות כמו מה שקרה אצלך. בגלל זה המבחן תקף גם כשהמדגם זעיר. הוא אף פעם לא הניח שהמדגם גדול.
כמה גדול ההבדל
ה-p הקטן אומר שטבלה קיצונית כמו שלך נדירה אם אין קשר בין הקבוצה לתוצאה. הוא לא אומר כמה הקשר גדול. כמו תמיד, מובהק וגדול הם לא אותו דבר.
בטבלת 2 על 2 גודל האפקט הטבעי הוא יחס הסיכויים, ה-odds ratio, וכדאי לדייק מה הוא. בקבוצת ההתערבות הסיכוי להגיע לרף מול לא להגיע הוא 8 ל-2, כלומר 4. בביקורת הוא 2 ל-7, כלומר 0.29. היחס בין השניים הוא 14. זה לא אומר שפי 14 יותר ילדים הגיעו לרף, השיעורים עצמם הם 80 אחוז מול 22 אחוז. זה אומר שיחס הסיכויים גבוה פי 14, וזה אפקט גדול.
אבל שימי לב לרווח הסמך שלו, מ-1.54 עד 127. הוא רחב מאוד, וזה לא טעות, ככה זה במדגם של תשעה-עשר. הכיוון ברור, ההתערבות קשורה לסיכוי גבוה יותר, אבל העוצמה המדויקת עדיין מטושטשת, כי יש מעט מאוד ילדים. את מדווחת את שניהם, גם את האומדן הגדול וגם את חוסר הדיוק סביבו.
ומה היה אומר חי-בריבוע
אם בכל זאת היית קוראת את שורת חי-בריבוע, היית מקבלת p של 0.012. גם הוא מובהק, אז כאן שני המבחנים מסכימים על המסקנה. זה משאיר רושם מטעה, כאילו לא משנה איזו שורה בוחרים.
אבל זה לא תמיד כך. במאמר על חי-בריבוע ראינו דוגמה הפוכה, שבה חי-בריבוע נתן p של 0.025 ו-Fisher דווקא 0.070, ושני המבחנים נתנו תוצאות משני צידי הסף. שם הבחירה בשורה הנכונה שינתה את כל המסקנה. ההבדל בין המבחנים אינו דרמה שקורית כל פעם, הוא עניין של תוקף. כשהתאים קטנים, Fisher הוא המבחן המתאים, בין אם הוא מסכים עם חי-בריבוע ובין אם לא. וכשהשכיחות הצפויה קטנה, את המסקנה לא מבססים על שורת חי-בריבוע, אלא מדווחים את Fisher.
איך מדווחים
שיעור ההגעה לרף היה גבוה יותר בקבוצת ההתערבות (8 מתוך 10, 80%) מאשר בביקורת (2 מתוך 9, 22%). מאחר ששלושה מהתאים היו בעלי שכיחות צפויה קטנה מ-5, נעשה שימוש במבחן Fisher's exact, שהראה קשר מובהק בין הקבוצה להגעה לרף, p = .023, OR = 14.0, 95% CI [1.54, 127.23].
שורה אחת, והיא אומרת מה ראית, למה בחרת את המבחן הזה, שהקשר מובהק, ושהוא גדול אבל נמדד על מדגם קטן.
מתי זה המבחן הנכון
Fisher's exact הוא המבחן לטבלת 2 על 2 כשהמדגם קטן והשכיחויות הצפויות יורדות מתחת ל-5. זה הבן זוג הישיר של חי-בריבוע לאי-תלות, לאותה שאלה בדיוק, האם שני משתנים קטגוריאליים קשורים, רק שהוא תקף גם בקטן.
שני סייגים מעשיים. ראשית, כל תלמיד נספר פעם אחת ויחידה, בתא אחד. זאת ההנחה של תצפיות בלתי תלויות, ושום מבחן לא יציל אותך אם היא מופרת. שנית, אם הטבלה שלך גדולה מ-2 על 2 ויש בה תאים דלילים, אפשר לאחד קטגוריות קרובות, אבל רק כשיש לכך היגיון תוכני ולא כתרגיל להעלים את הבעיה, או להשתמש בגרסת ה-exact שהתוכנה מציעה לטבלאות גדולות.
את הרעיון שמאחורי כל זה כדאי לקחת הלאה. כשהמדגם קטן מכדי לסמוך על עקומה, אפשר פשוט לספור. לרשום כל תוצאה שיכלה לקרות, לשקלל כמה סבירה כל אחת, ולבדוק כמה רחוק בקצה נפלה התוצאה שלך. זאת לא תחבולה לטבלאות קטנות. זאת הצורה הכי בסיסית של p: תחת ההנחה שאין קשר, כמה נדיר מה שראית. העקומות נכנסו לתמונה אחר כך, כקיצור דרך שחוסך את הספירה כשהמדגם גדול.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.