רגרסיה לוגיסטית: כשהתוצאה שלך היא כן או לא, ולא מספר

זה קורה בדרך כלל בפגישת הנחיה. הצגת את שאלת המחקר, האם תמיכה של חונכת קשורה לכך שמורה מתחילה נשארת בהוראה אחרי השנה הראשונה, ואמרת שתריצי רגרסיה. והמנחה עצר אותך במשפט אחד: "המשתנה התלוי שלך הוא כן/לא. אי אפשר להריץ על זה רגרסיה רגילה."
ואת חוזרת הביתה, פותחת את הקובץ, ומבינה שהוא צודק כמעט לגמרי. יש לזה פתרון מסודר, והוא נקרא רגרסיה לוגיסטית. כדי להבין למה צריך אותו, שווה קודם לראות במו עינייך איך הרגרסיה הרגילה קורסת.
הנתונים
דמייני מחקר קטן: שישים מורות בשנת ההוראה הראשונה שלהן. כל אחת דירגה את התמיכה שקיבלה מהחונכת על סולם של 1 עד 7, ובסוף השנה נרשם דבר אחד: נשארה בהוראה (1) או עזבה (0). מתוך השישים, 25 נשארו ו-35 עזבו.
ההבדל הגולמי כבר מדבר בעד עצמו. ממוצע התמיכה אצל מי שנשארו הוא 5.34. אצל מי שעזבו, 2.93. השאלה היא איך הופכים את זה למודל, כזה שלוקח ציון תמיכה ואומר משהו על הסיכוי להישאר.
למה רגרסיה רגילה קורסת כאן
במאמר על רגרסיה ליניארית ראינו שהמודל מעביר קו ישר דרך הנתונים. אפשר טכנית לעשות את זה גם פה. התוכנה לא תתלונן. היא תעביר קו ישר דרך ענן של אפסים ואחדים, והקו הזה ינסה לנבא את ההסתברות להישאר.
הבעיה היא שקו ישר לא יודע לעצור. אצלנו הוא חוצה את הנתונים יפה באמצע, אבל בקצוות הוא ממשיך וחורג מגבולות המציאות. למורה עם תמיכה של 1 הוא מנבא הסתברות של מינוס 0.13 להישאר. מינוס 13 אחוז. זה לא מספר שקיים. ובכיוון השני, מעט מעבר לראש הסולם, הקו כבר חוצה את 1 ומבטיח יותר ממאה אחוז. הסתברות קיימת רק בין 0 ל-1, וקו ישר פשוט מתעלם מהגבולות האלה.
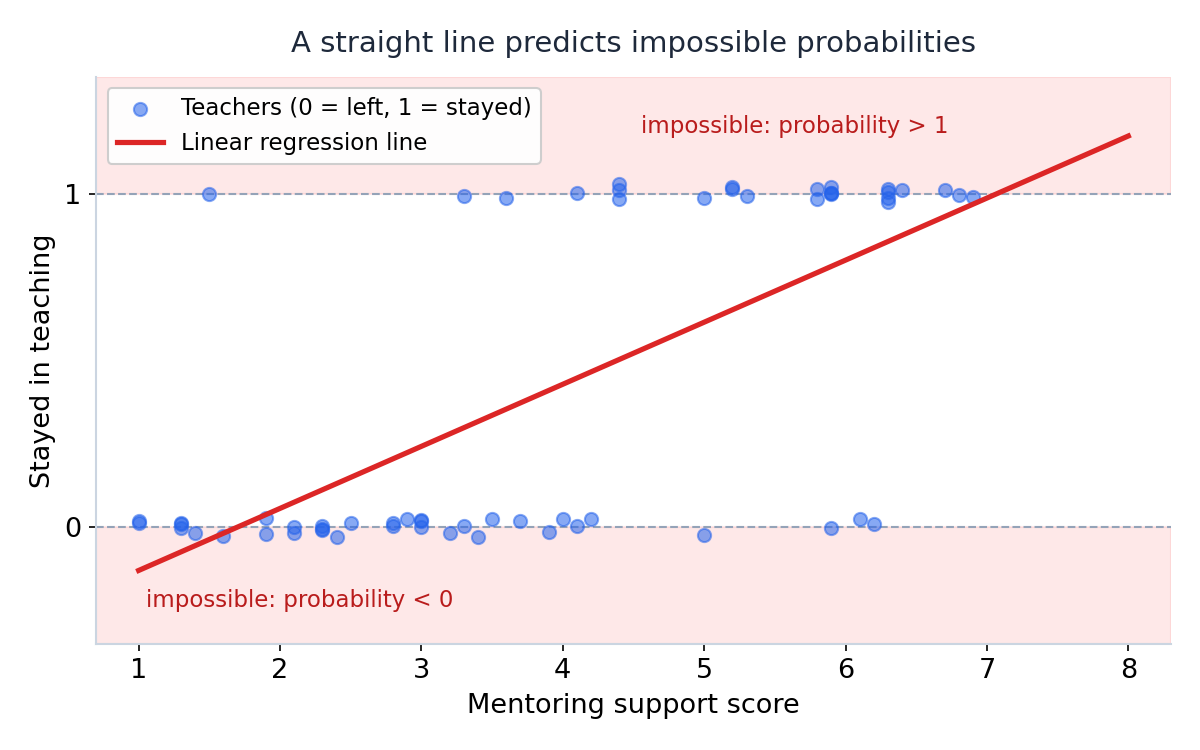
יש לקו הישר עוד בעיה, סמויה יותר. הוא מניח שכל נקודת תמיכה נוספת שווה את אותה תוספת סיכוי, בכל מקום על הסולם. אבל למי שכבר יש סיכוי של 90 אחוז להישאר אין לאן לטפס עוד 19 נקודות. הקשר חייב להתמתן בקצוות. הצורה המתאימה לזה היא לא קו. היא עקומה בצורת S.
העקומה שכן שומרת על הגבולות
רגרסיה לוגיסטית לא מנבאת את התשובה עצמה, נשארה או עזבה. היא מנבאת הסתברות. ובמקום קו ישר היא מתאימה עקומת S, שמתחילה קרוב ל-0, מטפסת בתלילות באמצע, ומתיישרת כשהיא מתקרבת ל-1. לעולם לא חוצה את הגבולות, כי הנוסחה שלה פשוט לא מאפשרת את זה.
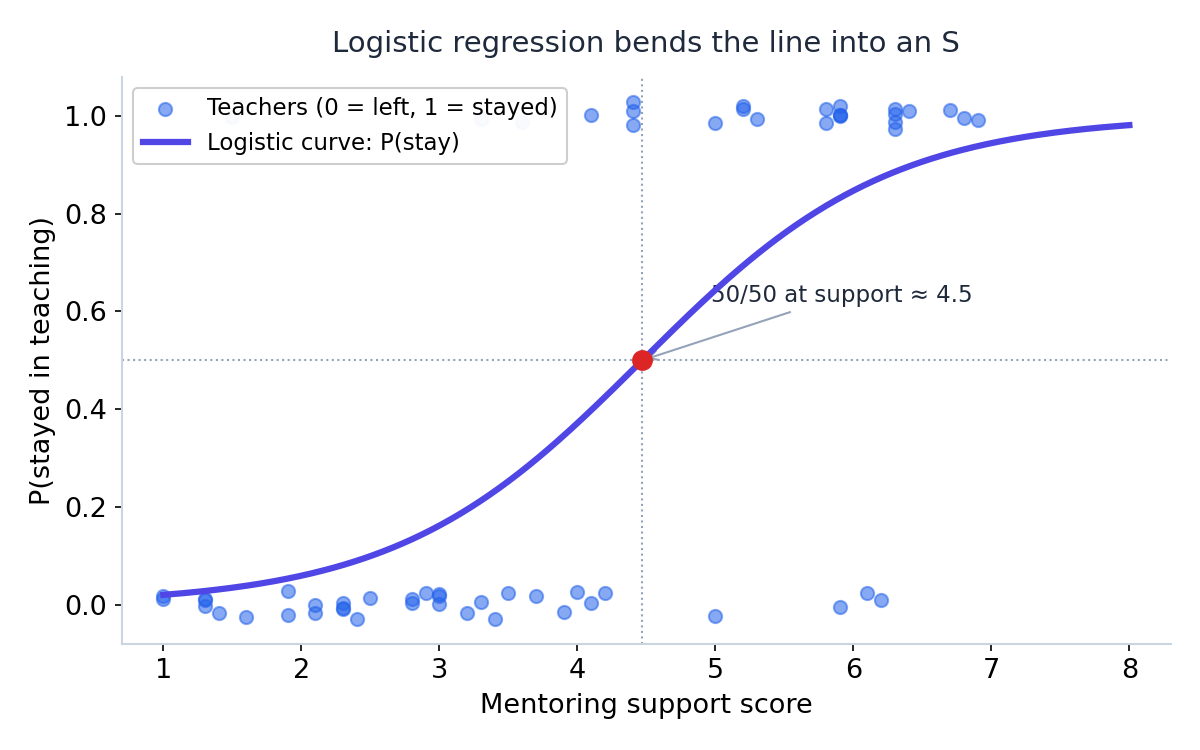
הנקודה האדומה על העקומה היא נקודת ה-50/50. אצלנו היא יושבת בציון תמיכה של 4.47. מתחתיה המודל מהמר על עזיבה, מעליה על הישארות.
ועכשיו החלק שמבלבל: המקדם מדבר בשפה של סיכויים
זה הרגע הקשה במאמר, אז נעבור עליו לאט.
המודל לא עובד ישירות על ההסתברות. הוא עובד על הסיכויים, ה-odds. סיכויים הם היחס בין ההסתברות שזה יקרה להסתברות שלא: P חלקי 1 פחות P. אם ההסתברות להישאר היא 64 אחוז, הסיכויים הם 0.64 חלקי 0.36, בערך 1.8. כמעט שתי נשארות על כל עוזבת. אם ההסתברות היא 16 אחוז, הסיכויים הם בערך 0.19. נשארת אחת על כל חמש עוזבות.
והנה הדבר היפה: הקו הישר לא נעלם כשכיפפנו אותו ל-S. הוא רק עבר לסקאלה אחרת. על הלוגריתם של הסיכויים הוא חוזר להיות קו ישר. אצלנו:
log(odds) = -5.00 + 1.118 × support
כל נקודת תמיכה מוסיפה 1.118 ללוג של הסיכויים. זה כל הטריק. וכשמתרגמים את הקו הישר הזה בחזרה לסקאלת ההסתברות, מקבלים בדיוק את עקומת ה-S מהתרשים.
לוג של סיכויים הוא לא מספר שאפשר להרגיש. אף אחד לא חושב ככה על העולם, וזה בסדר. הוא שפת הביניים של המודל, לא שפת הדיווח שלך.
המספר שכן מדווחים: יחס הסיכויים
כדי לחזור לשפה קריאה, מוציאים את המקדם מהלוגריתם: e בחזקת 1.118 שווה 3.06. זה יחס הסיכויים, ה-odds ratio, ואותו כבר פגשנו במאמר על מבחן פישר. הפירוש: על כל נקודת תמיכה נוספת, הסיכויים להישאר מוכפלים פי 3.06.
שימי לב לניסוח. הסיכויים מוכפלים פי 3.06, לא ההסתברות. מורה בציון תמיכה 4, עם הסתברות של 37 אחוז להישאר, לא קופצת ל-113 אחוז כשהתמיכה עולה ל-5. הסיכויים שלה הם שמוכפלים, וההסתברות עולה ל-64 אחוז. זאת הטעות הנפוצה ביותר בפירוש רגרסיה לוגיסטית.
היחס הזה גם מצטבר בכפל. שתי נקודות תמיכה מכפילות את הסיכויים פי 3.06 בריבוע, שזה 9.36. בדקי בעצמך: בתמיכה 3 הסיכויים הם 0.19, בתמיכה 5 הם 1.81, והיחס ביניהם הוא בדיוק 9.36.
וכמו תמיד, לאומדן מצורפת אי-ודאות. רווח הסמך של יחס הסיכויים הוא [1.83, 5.13] ברמת ביטחון של 95 אחוז. הוא לא נוגע ב-1, שהוא הערך של "אין קשר", וה-p קטן מ-.001. הקשר מובהק, וגם בקצה הזהיר של הרווח הוא עדיין לא קטן.
ומה זה אומר בהסתברויות
בשביל פרק הממצאים, הדרך הכי קריאה להראות את המודל היא כמה הסתברויות חזויות לאורך הסולם:
| ציון תמיכה | הסתברות חזויה להישאר |
|---|---|
| 2 | 6% |
| 3 | 16% |
| 4 | 37% |
| 5 | 64% |
| 6 | 85% |
תסתכלי על המדרגות. מ-2 ל-3 ההסתברות עולה ב-10 נקודות. מ-4 ל-5 היא עולה ב-27. אותה נקודת תמיכה, תוספת שונה לגמרי, כי אנחנו על עקומה ולא על קו. בקצוות ההשפעה מתונה, באמצע היא חדה.
האם המודל בכלל טוב
גם לזה יש תשובה מסודרת. משווים את המודל עם התמיכה למודל ריק, בלי שום מנבא, ובודקים כמה הוא משתפר. אצלנו χ²(1) = 31.86, p < .001. המודל עם התמיכה מתאים לנתונים טוב יותר, באופן מובהק, מהמודל הריק.
בנוסף מדווחים בדרך כלל מדד בסגנון R², אצל רגרסיה לוגיסטית הנפוץ הוא McFadden pseudo R², ואצלנו הוא .39. כלל אצבע מקובל אומר שערכים בין 0.2 ל-0.4 נחשבים טובים מאוד, אבל קחי אותו בעירבון מוגבל, כי המדד הזה תלוי בתחום ובסוג הנתונים, והוא לא מתורגם ישירות ל"אחוז שונות מוסברת" כמו ה-R² הרגיל. ובשפה פשוטה יותר: אם מסווגים לפי המודל מי תישאר ומי תעזוב (חזוי מעל 50 אחוז נחשב תישאר), מצליחים ב-82 אחוז מהמקרים, על אותם נתונים שהמודל הותאם עליהם. לשם השוואה, ניחוש גורף של "כולן יעזבו" היה מצליח ב-58 אחוז. וזה מדד תיאורי בלבד, לא בדיקה של יכולת ניבוי על נתונים חדשים.
איך מדווחים
נערכה רגרסיה לוגיסטית לניבוי התמדה בהוראה בתום השנה הראשונה (נשארה = 1, עזבה = 0) על פי רמת התמיכה מהחונכת. המודל היה מובהק, χ²(1) = 31.86, p < .001, McFadden R² = .39. רמת תמיכה גבוהה יותר הייתה קשורה לסיכויים גבוהים יותר להישאר בהוראה, B = 1.12, OR = 3.06, 95% CI [1.83, 5.13], p < .001, כך שכל נקודת תמיכה נוספת הכפילה את הסיכויים להישאר פי 3.06.
שימי לב למילה "קשורה". המורות לא הוגרלו לרמות תמיכה. ייתכן שבתי ספר תומכים הם גם בתי ספר טובים בעוד דרכים, וייתכן שמורות שממילא נוטות להישאר מגייסות יותר תמיכה. המודל מתאר קשר, לא מוכיח סיבה.
שלוש בדיקות לפני שאת סוגרת את הפרק
ראשית, הנחת הליניאריות לא נעלמה, היא רק עברה דירה. המודל מניח שכל נקודת תמיכה מוסיפה אותה תוספת ללוג-הסיכויים, לאורך כל הסולם. אם הקשר האמיתי מתעקל גם שם, המודל יפספס. בדיקה פשוטה היא להוסיף איבר ריבועי של התמיכה ולראות אם הוא תורם.
שנית, התצפיות צריכות להיות בלתי תלויות. אם המורות שלך מקובצות בתוך בתי ספר, מורות מאותו בית ספר דומות זו לזו, וזה דורש מודל שמתחשב בכך (רגרסיה לוגיסטית רב-רמתית), לא את הגרסה הפשוטה.
שלישית, גודל המדגם. ברגרסיה לוגיסטית מה שקובע הוא לא 60 המורות אלא הקבוצה הקטנה מבין השתיים, אצלנו 25 הנשארות. כלל אצבע נפוץ ממליץ על בערך עשרה מקרים בקבוצה הקטנה על כל מנבא במודל. עם מנבא אחד אנחנו בתוך הטווח. אם תרצי להוסיף עוד מנבאים, וזה עובד בדיוק כמו המעבר לרגרסיה מרובה, 25 הנשארות מספיקות בערך לשניים-שלושה. לא לשבעה. וגם זה כלל אצבע לאזהרה מוקדמת, לא תעודת כשרות למודל.
ומה אם המשתנה התלוי שלך הוא לא כן/לא אלא סולם, נמוך-בינוני-גבוה, או שביעות רצון מ-1 עד 5? יש לזה קרובת משפחה, רגרסיה אורדינלית, והיא שייכת לפוסט אחר. העיקרון שלקחת מכאן יחזיק גם שם: כשהמשתנה התלוי מפסיק להיות מספר רציף, לא מוותרים על רגרסיה. מחליפים את הסקאלה שעליה הקו ישר.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.