נתונים חסרים: איך 100 שאלונים הפכו ל-55 בפלט

הרצת את הניתוח. השאלון יצא בסדר, אספת מאה שאלונים, ספרת אותם ביד. ואז את מסתכלת על הפלט, ובפינה כתוב שהניתוח רץ על 55 משתתפות.
מי מחק ארבעים וחמש?
אף אחת. זה קרה לבד, בשקט, ברגע שלחצת על "הרץ". וזה בדיוק מה שנעבור עליו כאן.
נתונים חסרים זה לא תקלה. זה ברירת המחדל
מישהי דילגה על שאלה 14. מישהו סגר את השאלון באמצע. מישהי השאירה את שאלת האוטונומיה ריקה כי לא הבינה אותה. זה לא רשלנות, וזה לא קורה רק לך. בכל מחקר אמיתי יש תאים ריקים.
נניח שיש לך חמישה משתנים: ותק, שחיקה, תמיכת המנהל, תחושת אוטונומיה, ורווחה נפשית. בכל אחד מהם חסרים בערך עשרה אחוז מהתשובות. עשרה אחוז זה נשמע נסבל. אחד מתוך עשרה, לא נורא.
הבעיה היא שאת לא מנתחת משתנה אחד בכל פעם.
למה עשרה אחוז הופכים לארבעים וחמישה
ברגע שהניתוח שלך צריך את כל חמשת המשתנים יחד, למשל רגרסיה או מתאם בין כולם, למשתתפת צריכים להיות נתונים מלאים בכל החמישה כדי להישאר בפנים. חסר לה תא אחד, ולו אחד, והיא יוצאת.
בהרבה ניתוחים ב-SPSS, כולל רגרסיה, זאת ברירת המחדל. קוראים לה מחיקה לפי רשימה (listwise): כל מי שחסר לה ולו ערך אחד מבין המשתנים בניתוח, נמחקת מהניתוח כולו. (לא בכל פרוצדורה זה כך, ונגיע לזה עוד מעט.)
ועכשיו החשבון שמפתיע כמעט כל אחת. נניח שהחֶסֶר בכל משתנה בלתי תלוי בשאר, ושבכל משתנה יש סיכוי של תשעים אחוז שהתא מלא. הסיכוי שלמשתתפת יהיו נתונים מלאים בכל החמישה הוא לא תשעים אחוז. הוא 0.9 בחזקת 5, שזה בערך 0.59.
במילים אחרות: גם אם כל עמודה בנפרד מלאה ב-90 אחוז, רק לכ-59 מתוך 100 משתתפות יש נתונים מלאים בכל החמישה. בנתונים שלנו המספר יצא 55, קצת פחות, כי החֶסֶר אצלנו לא בדיוק עשרה אחוז בכל משתנה ולא לגמרי אקראי.
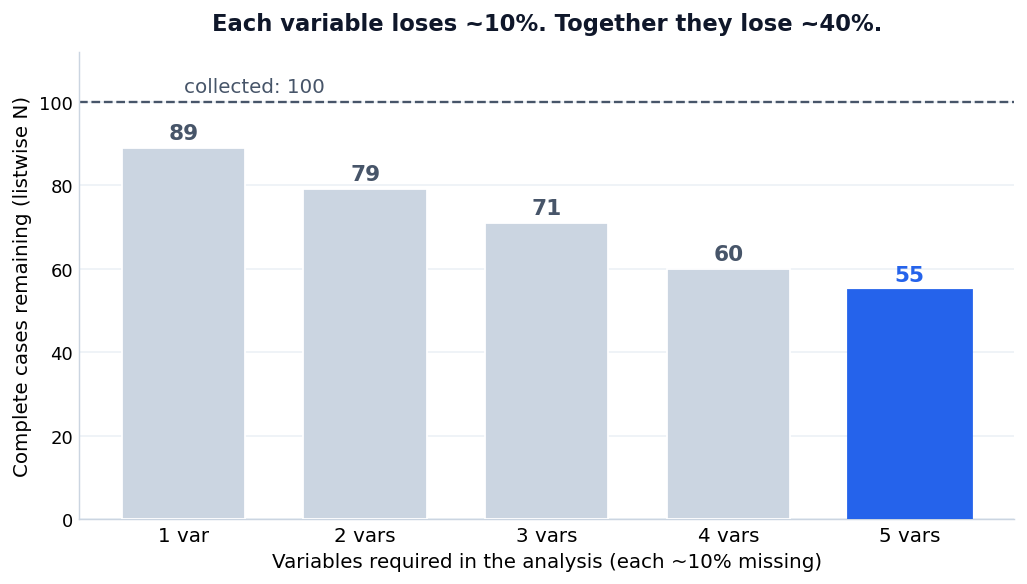
תסתכלי על הירידה. משתנה אחד, 89 משתתפות. שניים, 79. שלושה, 71. ארבעה, 60. חמישה, 55. כל משתנה שאת מוסיפה לניתוח גוזל עוד פיסה, וההפסדים מצטברים. אף עמודה בודדת היא לא האשמה. הצירוף הוא האשם.
אז למה לא פשוט להשתמש בכל מי שיש?
יש שיטה שנייה, והיא נשמעת הגיונית יותר. במקום למחוק משתתפת מכל הניתוח, נשתמש בכל פעם בכל מי שיש לה את שני המשתנים הרלוונטיים לאותו חישוב. קוראים לזה מחיקה זוגית (pairwise).
זה באמת שומר יותר נתונים. אבל יש לזה מחיר סמוי.
קחי את המתאם בין תמיכת המנהל לרווחה הנפשית. במחיקה זוגית הוא מחושב על כל מי שיש לה את שתי השאלות האלה, 81 משתתפות, ויוצא 0.25. במחיקה לפי רשימה הוא מחושב רק על ה-55 שיש להן נתונים מלאים בכל חמשת המשתנים, כולל שלושה משתנים שאין להם שום קשר למתאם הזה, ויוצא 0.27.
המתאם עצמו כמעט לא זז. אבל תסתכלי מה קרה מסביבו. ב-81 משתתפות הוא מובהק ברמה של 0.025. ב-55 משתתפות, אותו קשר כמעט, ה-p כבר 0.044, ממש על הגבול. אותו ממצא נחלש, רק כי פחות שורות שרדו את המחיקה.
וזאת בדיוק ברירת המחדל של חלק מהפרוצדורות, כמו טבלת מתאמים: מחיקה זוגית, לא לפי רשימה. לכן חשוב לדעת מה רץ אצלך, כי אותה תוכנה עושה דברים שונים בניתוחים שונים.
ובטבלת מתאמים שלמה זה נהיה חמקמק. כל תא מחושב על קבוצה אחרת. המתאם בין ותק לאוטונומיה רץ על 76 משתתפות, בין תמיכה לרווחה על 81, בין שחיקה לאוטונומיה על 77. אין מאחורי הטבלה מדגם אחד. בכל תא יושב N אחר, וקשה להשוות בין התאים. במקרים קיצוניים, טבלה כזאת יכולה אפילו לא להיות עקבית מתמטית עם עצמה.
החלק שבאמת חשוב: לא כמה חסר, אלא למי
זה הרגע הקשה במאמר, אז נעבור עליו לאט.
עד עכשיו דיברנו על כמה את מאבדת. אבל יש שאלה חשובה ממנה: מי חסר. ופה נחתך אם הנתונים החסרים שלך הם אי-נוחות או בעיה.
אם התאים הריקים נופלים באקראי, פחות או יותר הגרלה, אז בעיקר איבדת כוח סטטיסטי. המדגם קטן יותר, אבל באופן שיטתי הוא עדיין מייצג את אותם אנשים. לא נעים, אבל לא מטה את התוצאה לכיוון מסוים.
רק שבמציאות, לעיתים קרובות, התאים לא ריקים באקראי.
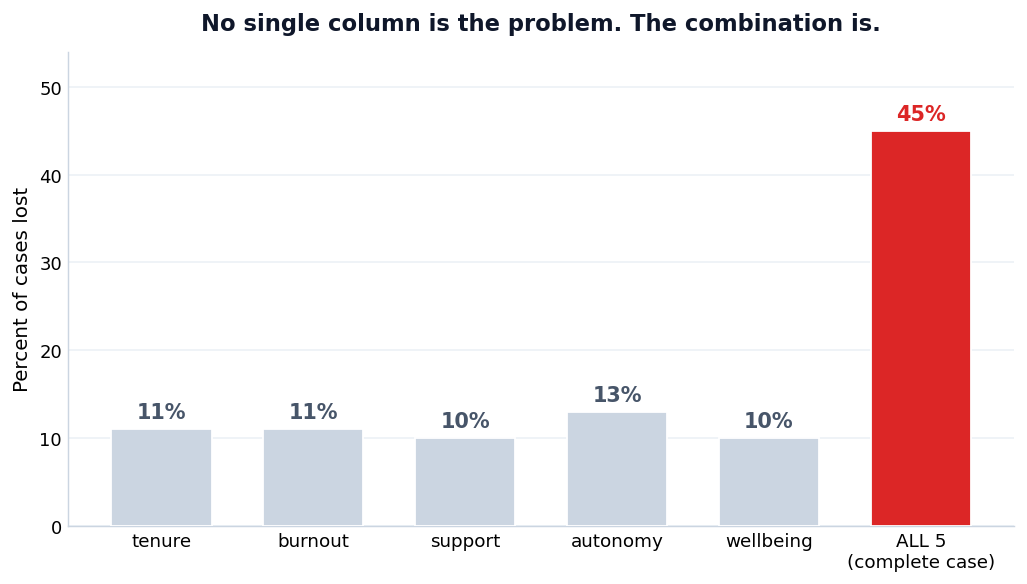
תראי מה קרה אצלנו עם שאלת האוטונומיה. 13 משתתפות השאירו אותה ריקה. השחיקה הממוצעת שלהן הייתה 56. אצל מי שכן ענתה, הממוצע היה קרוב ל-50. כלומר העמודה של האוטונומיה חסרה דווקא אצל המורות השחוקות יותר.
עכשיו תחשבי מה זה אומר. כל ניתוח שדורש את האוטונומיה משאיר בחוץ, באופן לא פרופורציונלי, את המורות השחוקות יותר. מי שנושרת מהחישוב הזה אינה חתך אקראי של המדגם. היא נוטה לכיוון אחד.
זאת ההבחנה שמאחורי כל הנושא. השאלה אינה רק "כמה נתונים חסרים לי", אלא "האם הם חסרים באקראי, או שהחֶסֶר קשור למשהו שאני חוקרת". כשהחֶסֶר קשור לדבר עצמו שאת מודדת, מחיקה, לפי רשימה או זוגית, כבר לא רק מקטינה את המדגם. היא עלולה להטות אותו, לא רק לפגוע בדיוק.
מה לעשות עם זה בפועל
לא צריך פתרון דרמטי. צריך לעצור לפני שמריצים, ולבדוק שלושה דברים.
ראשית, כמה חסר ואיפה. הסתכלי על אחוז החֶסֶר בכל משתנה, ובעיקר על ה-N של המקרים השלמים. אם אספת 100 והניתוח רץ על 55, את רוצה לדעת את זה לפני המנחה, לא ממנו.
שנית, האם יש דפוס. אם חסרים אחוזים בודדים בלבד, מחיקה לפי רשימה היא לרוב בחירה סבירה ומקובלת. אבל מעט חֶסֶר לא מבטיח שהוא אקראי, אז עדיין שווה להציץ אם דווקא קבוצה מסוימת משאירה תאים ריקים. אם חסר הרבה, או שהחֶסֶר מרוכז אצל סוג מסוים של משתתפות, זה הדגל האדום. שם כבר לא מספיק למחוק, ונכנסות שיטות של השלמת נתונים (imputation), וזה כבר נושא לפוסט נפרד.
שלישית, תדווחי. משפט אחד בפרק השיטות: "כ-10 אחוז מהנתונים היו חסרים בכל משתנה, וטופלו במחיקה לפי רשימה, כך שה-N הסופי עמד על 55." כשהוועדה שואלת "איך טיפלת בנתונים החסרים", יש לך תשובה, ולא שתיקה.
ה-N שיושב בראש הפלט שלך הוא לא עובדה. הוא החלטה. לפעמים החלטה שתוכנת SPSS קיבלה במקומך, בלי לשאול. שווה לדעת איזו החלטה התקבלה, ולמה היא בסדר.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.