רגרסיה אורדינלית: כשהתוצאה שלך היא דירוג, נמוך-בינוני-גבוה, ולא מספר

המשתנה התלוי שלך הוא דירוג. רמת שחיקה: נמוכה, בינונית, גבוהה. או שביעות רצון: נמוכה, בינונית, גבוהה. שלוש מדרגות, בסדר ברור, אבל לא מספר שמדדת. ופה את נתקעת, כי רגרסיה, ככל שאת זוכרת, רוצה מספר.
אז עשית אחד משניים. או שהרצת רגרסיה רגילה על הקידוד 1, 2, 3, כאילו אלה מספרים. או שהמנחה עצר אותך לפני כן ואמר שאי אפשר. שתי הדרכים מובילות לאותו מקום: יש פתרון מסודר, הוא נקרא רגרסיה אורדינלית, וכדי להבין אותו צריך קודם לראות למה שתי הדרכים האחרות לא עובדות.
הנתונים
דמייני מחקר על 150 מורות. כל אחת דירגה את רמת השחיקה שלה בשלוש רמות: נמוכה (74 מורות), בינונית (44) או גבוהה (32). ולכל אחת יש גם משתנה רציף אחד: כמה שעות בשבוע היא מקדישה לעבודה מנהלית, טפסים, דוחות, מיילים, מ-0 עד 20.
ההבדל הגולמי כבר ברור. אצל מי שדיווחה על שחיקה נמוכה, ממוצע השעות המנהליות הוא 6.5. אצל הבינונית, 13.1. אצל הגבוהה, 16.0. ככל שיותר עומס מנהלי, כך הדירוג עולה. השאלה היא איך הופכים את הקשר הזה למודל.
למה רגרסיה רגילה על 1, 2, 3 שגויה
במאמר על רגרסיה ליניארית ראינו שהמודל מעביר קו ישר ומנבא מספר. אפשר טכנית להריץ אותו על הקידוד 1, 2, 3. התוכנה לא תתלונן. אבל היא תיתן לך תשובות שאין להן פירוש.
אצלנו הקו הישר יוצא שחיקה = 0.785 + 0.089 × שעות. תכניסי 20 שעות מנהלה, והוא מנבא 2.57. אבל 2.57 של מה? זה ממוצע של התוויות שאת בחרת. אם היית מקדדת את אותן שלוש רמות כ-10, 20, 30 במקום 1, 2, 3, אותם נתונים בדיוק היו מנבאים 25.7. המספר משתנה לפי הקידוד השרירותי שבחרת, כי הקו הישר מתייחס לתוויות הדירוג כאל כמויות אמיתיות. הוא גם עלול לחרוג מהסולם ולנבא ערך מתחת ל-1 או מעל ל-3, רמות שלא קיימות.
ויש בעיה שנייה, עמוקה יותר. הקו הישר מניח שהמרחק מ"נמוכה" ל"בינונית" שווה למרחק מ"בינונית" ל"גבוהה", כי 2 פחות 1 שווה 3 פחות 2. אבל את לא מדדת מרחקים. את מדדת סדר. המספרים 1, 2, 3 הם תוויות של דירוג, לא כמויות. אולי הקפיצה מבינונית לגבוהה היא תהום, והקפיצה מנמוכה לבינונית היא צעד קטן. הקו הישר לא יודע את זה, והוא מתייחס לשתי הקפיצות כאל זהות.
ולמה לא פשוט להתעלם מהסדר
אז אולי בכלל לא להתייחס לזה כמספרים. אפשר להתייחס לשלוש הרמות כשלוש קטגוריות נפרדות, בלי סדר. מבחן חי-בריבוע היה דורש קודם לחלק גם את שעות המנהלה לקטגוריות, וכך לאבד מידע. רגרסיה מולטינומית, אחותה של הלוגיסטית לכמה קטגוריות, שומרת את השעות רציפות, אבל עדיין מתעלמת מהסדר בין הרמות.
וזה המחיר. ברגע שאת מתייחסת לרמות כאל קטגוריות חסרות סדר, את זורקת את הדבר הכי שימושי שאת יודעת עליהן: שגבוהה היא יותר מבינונית, ובינונית יותר מנמוכה. הסדר הזה הוא מידע. הוא מאפשר למודל לנצל את מבנה הקשר עם העומס המנהלי, במקום לאמוד כל קטגוריה בנפרד. לוותר עליו זה כמו לנתח ציוני בחינה אחרי שהפכת אותם לשמות צבעים.
הפתרון: לפצל את הסולם, אבל עם שיפוע אחד
הרעיון של רגרסיה אורדינלית פשוט ויפה. במקום לנבא מספר, ובמקום לזרוק את הסדר, היא חותכת את הסולם בנקודות, ושומרת על הסדר בין הקטגוריות.
במאמר על רגרסיה לוגיסטית ראינו מודל לתוצאה של כן או לא, חיתוך אחד. כאן יש שלוש רמות, ולכן שני חיתוכים. הראשון: נמוכה מול בינונית-או-גבוהה. השני: נמוכה-או-בינונית מול גבוהה. כל חיתוך הוא בעצם שאלת כן/לא: "האם המורה מעל הקו הזה?"
וכאן הטריק שמחזיק את כל המודל. במקום שלכל חיתוך יהיה שיפוע משלו, המודל מאלץ את שני החיתוכים לחלוק שיפוע אחד. כלומר, ההשפעה של שעת מנהלה נוספת על הסיכויים להיות ברמה גבוהה יותר היא אותה השפעה, בין אם מסתכלים על החיתוך התחתון ובין אם על העליון. ההנחה הזאת נקראת הנחת הסיכויים היחסיים (proportional odds), והיא הלב של השיטה.
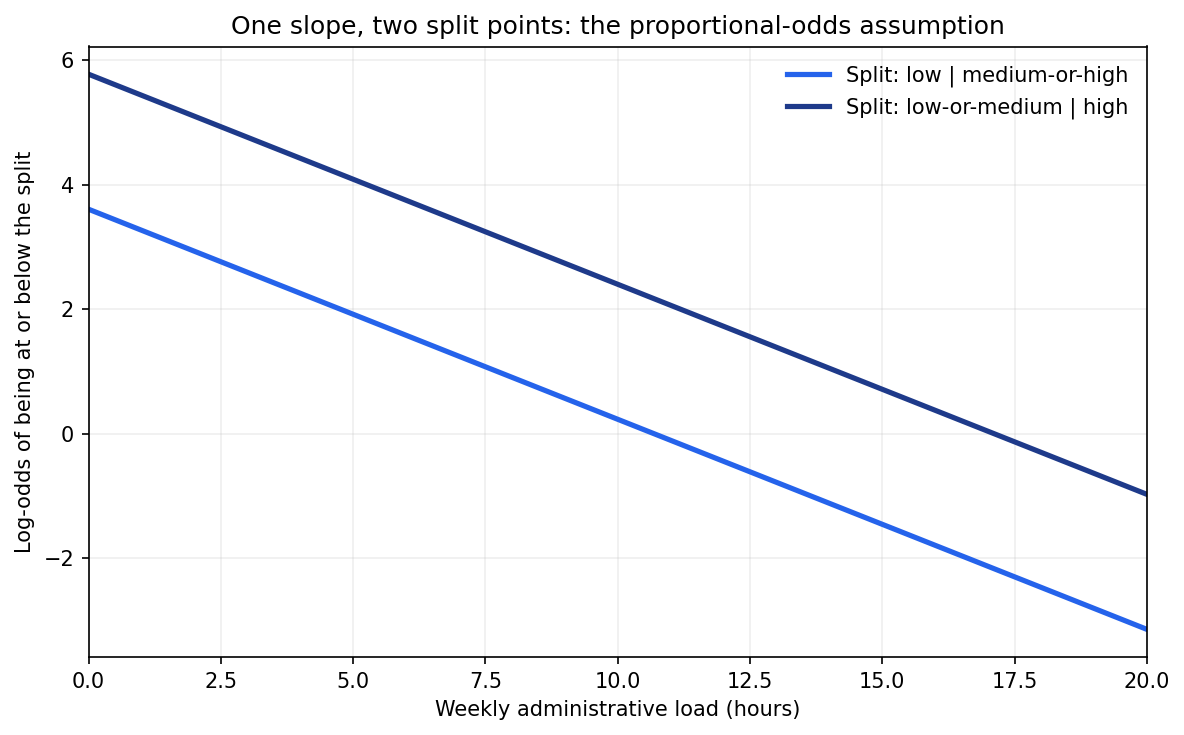
שני הקווים מקבילים. זאת התמונה של הנחת הסיכויים היחסיים: אותו שיפוע, רק נקודת התחלה שונה לכל חיתוך. הקווים יורדים מפני שהם מתארים את הלוג-סיכויים להיות ברמה נמוכה או שווה לחיתוך, וזה פוחת ככל שהמנהלה עולה. במונחים ההפוכים, הסיכויים להיות מעל החיתוך גדלים, וזה המספר שנראה עוד רגע.
המספר שמדווחים: יחס סיכויים אחד
בזכות השיפוע המשותף, יוצא מספר אחד שמתאר את כל הקשר. אצלנו השיפוע הוא 0.34 על סקאלת הלוג, וכמו ברגרסיה לוגיסטית מוציאים אותו מהלוגריתם: e בחזקת 0.34 שווה 1.40. זה יחס הסיכויים.
הפירוש: על כל שעת מנהלה נוספת, הסיכויים מוכפלים פי 1.40, כלומר עולים בכ-40 אחוז. ובגלל הנחת הסיכויים היחסיים, אותו 1.40 תקף לשני החיתוכים בנפרד. גם לסיכוי להימצא בבינונית-או-גבוהה לעומת נמוכה, וגם לסיכוי להימצא בגבוהה לעומת נמוכה-או-בינונית. זה לא יחס סיכויים למעבר ישיר ממדרגה אחת לשכנתה, אלא לחיתוך מצטבר.
הערה על הסימן: תוכנות שונות מנסחות את המודל בכיוונים הפוכים, ולכן לפעמים המקדם יופיע אצלך עם סימן מינוס. זה לא אומר שמשהו השתבש. יחס הסיכויים שמדווח כאן מתאר את הכיוון האינטואיטיבי, יותר מנהלה קשורה לסיכוי גבוה יותר לשחיקה גבוהה.
פי 1.40 לשעה נשמע מתון, אבל זה מצטבר בכפל בדיוק כמו ברגרסיה הלוגיסטית. הפרש של ארבע שעות מנהלה מכפיל את הסיכויים פי 1.40 בחזקת 4, שזה 3.86. הסיכויים של מורה עם ארבע שעות מנהלה יותר מחברתה גבוהים כמעט פי ארבעה, להיות ברמת שחיקה גבוהה יותר.
וכמו תמיד, לאומדן יש רווח סמך: [1.28, 1.53] ברמת ביטחון של 95 אחוז. הוא לא נוגע ב-1, שהוא הערך של "אין קשר", וה-p קטן מ-.001. הקשר מובהק.
ומה זה אומר בהסתברויות
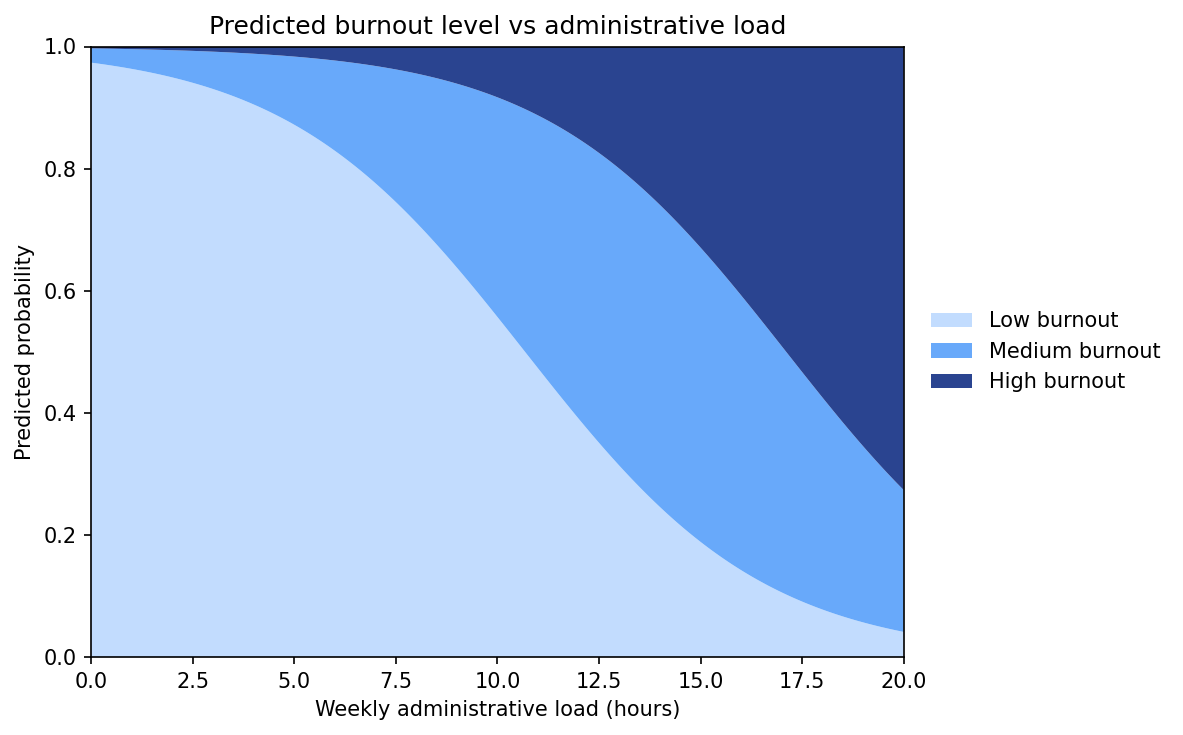
יחס הסיכויים מדויק, אבל קשה להרגיש אותו. לפרק הממצאים, הדרך הקריאה היא להראות את ההסתברות החזויה לכל רמה, לאורך הסולם:
| שעות מנהלה | נמוכה | בינונית | גבוהה |
|---|---|---|---|
| 4 | 91% | 8% | 1% |
| 8 | 71% | 24% | 4% |
| 12 | 39% | 46% | 15% |
| 16 | 14% | 45% | 41% |
תסתכלי על מה שקורה משורה לשורה. הרמה הנמוכה מתכווצת, מ-91 אחוז ל-14. הגבוהה תופחת, מאחוז אחד ל-41. והבינונית עולה באמצע ואז מתחילה לרדת, כי היא נדחקת מלמטה ומלמעלה בו זמנית. זה דפוס אופייני שהמודל האורדינלי מייצר לקטגוריית האמצע, ואי אפשר לראות אותו בקו ישר אחד.
האם המודל בכלל טוב
גם לזה יש תשובה מסודרת, ובדיוק כמו ברגרסיה הלוגיסטית. משווים את המודל עם העומס המנהלי למודל ריק, בלי שום מנבא, ובודקים כמה הוא משתפר. אצלנו χ²(1) = 90.48, p < .001. המודל עם המנבא מתאים לנתונים טוב יותר, באופן מובהק.
בנוסף מדווחים מדד בסגנון R², ואצל המשפחה הזאת הנפוץ הוא McFadden pseudo R², שיצא .29. כלל אצבע מקובל אומר שערכים בין 0.2 ל-0.4 נחשבים טובים מאוד, אבל קחי אותו בעירבון מוגבל. הוא לא "אחוז שונות מוסברת" כמו ה-R² הרגיל, והוא תלוי בסוג הנתונים.
איך מדווחים
נערכה רגרסיה אורדינלית (מודל סיכויים יחסיים) לניבוי רמת השחיקה (נמוכה / בינונית / גבוהה) על פי היקף העבודה המנהלית השבועית. המודל היה מובהק, χ²(1) = 90.48, p < .001, McFadden R² = .29. עומס מנהלי גבוה יותר היה קשור לסיכויים גבוהים יותר לרמת שחיקה גבוהה יותר, OR = 1.40, 95% CI [1.28, 1.53], p < .001, כך שכל שעת מנהלה נוספת הייתה קשורה לעלייה של כ-40 אחוז בסיכויים להימצא ברמת שחיקה גבוהה יותר. הנחת הסיכויים היחסיים נבדקה באמצעות מבחן הקווים המקבילים, ולא נמצאה מופרת.
שימי לב למילה "קשור". המורות לא הוגרלו להיקף עבודה מנהלית. ייתכן שמי שכבר שחוקה נדחפת לתפקידים מנהליים, או שבית ספר עמוס מייצר גם שחיקה וגם מנהלה. המודל מתאר קשר, לא מוכיח סיבה.
הבדיקה שאי אפשר לדלג עליה
זה הרגע הקשה במאמר, אז נעבור עליו לאט.
כל היופי של רגרסיה אורדינלית, יחס סיכויים אחד שמתאר את כל הסולם, נשען על הנחה אחת: שההשפעה של המנבא זהה בכל החיתוכים. אם זה לא נכון, המספר האחד היפה הזה הוא שקר, כי הוא ממוצע של שתי השפעות שונות שהתחזו לאחת.
אז בודקים. הדרך האינטואיטיבית היא להריץ כל חיתוך בנפרד, כשתי רגרסיות לוגיסטיות של כן/לא, ולהשוות את השיפועים. אצלנו השיפוע בחיתוך התחתון נותן יחס סיכויים של 1.39, ובחיתוך העליון 1.40. קרובים מאוד, וזה מתיישב יפה עם ההנחה.
אבל זאת בדיקה תיאורית בלבד. שני שיפועים כמעט אף פעם לא יוצאים זהים בדיוק, גם כשההנחה נכונה, כי יש רעש דגימה. השאלה האמיתית היא אם הפער ביניהם גדול מהרעש הזה, וזאת כבר בדיקה פורמלית. ב-SPSS היא מופיעה אוטומטית בפלט של הרגרסיה האורדינלית, תחת השם "מבחן הקווים המקבילים" (Test of Parallel Lines). שימי לב להיפוך: במבחן המודל קודם, p נמוך היה הבשורה הטובה. כאן הפוך, p לא מובהק הוא מה שמקווים לו, כי הוא אומר שאין עדות לכך שההנחה הופרה. (יש גם מבחנים ייעודיים אחרים, כמו מבחן Brant, לפי התוכנה.)
ומה אם ההנחה כן מופרת, אם השיפועים רחוקים זה מזה? אז יחס סיכויים אחד כבר לא מספר את הסיפור. שעת מנהלה לא משפיעה באותה צורה על החיתוך התחתון של הסולם ועל החיתוך העליון שלו. במקרה כזה לא נשארים עם המודל הפשוט. עוברים למודל שמאפשר לשיפוע להשתנות בין החיתוכים (סיכויים יחסיים חלקיים), או, אם נאלצים, חוזרים למולטינומי ומוותרים על הסדר. הבדיקה הזאת היא ההבדל בין מודל שאפשר להגן עליו לבין מודל שנראה תקין ואינו.
אם מבחן הקווים המקבילים יצא מובהק (ההנחה הופרה), שלוש דרכים פתוחות:
1. סיכויים יחסיים חלקיים (partial proportional odds): משחררים את ההנחה רק עבור המנבא שמפר אותה, ומשאירים שיפוע משותף לשאר. כך נשמר הסדר בלי לכפות מספר אחד שאינו נכון.
2. רגרסיה מולטינומית: מוותרים על הסדר לגמרי, ומקבלים מקדם נפרד לכל קטגוריה. פחות חסכוני, אבל לא מניח דבר שלא בדקת.
3. אם בכל זאת את נשארת עם המודל האורדינלי, דווחי על ההפרה במפורש כמגבלה, ואל תציגי את יחס הסיכויים האחד כאילו הוא תקף באותה מידה לכל אורך הסולם.
וזה העיקרון שלוקחים מכאן, אותו עיקרון שראינו ברגרסיה הלוגיסטית. כשהמשתנה התלוי מפסיק להיות מספר רציף, לא מוותרים על רגרסיה. כן/לא מוביל ללוגיסטית. נמוך-בינוני-גבוה מוביל לאורדינלית. בכל פעם מחליפים את הסקאלה שעליה הקו ישר, ושומרים בדיוק את המבנה של מה שמדדת.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.