מבחן Levene יצא מובהק: איזו שורה לקרוא במבחן t

השווית שתי כיתות. שיטת לימוד אחת מול אחרת, אותו מבחן בסוף. הרצת מבחן t, וקיבלת תוצאה מובהקת. נראה שהשיטה החדשה עדיפה.
ואז המנחה שאל: "בדקת שוויון שונויות?" או, בתרחיש אחר, פתחת את הפלט ב-SPSS וראית שורה שמעולם לא הסתכלת עליה. כתוב בה Levene's Test, ולידה Sig. קטן מ-0.05.
פתאום את לא בטוחה אם המבחן שהרצת בכלל תקף. בואי נראה מה השורה הזאת בודקת, למה היא חשובה, ומה עושים כשהיא יוצאת מובהקת.
מה Levene בודק, ולא את הממוצעים
מבחן t שואל אם הממוצעים של שתי הקבוצות שונים. אבל מתחת לשאלה הזאת מסתתרת הנחה סמויה: שלשתי הקבוצות יש בערך אותו פיזור. אותה שונות. שתי הקבוצות מתנדנדות סביב הממוצע שלהן באותה עוצמה.
מבחן Levene בודק בדיוק את ההנחה הזאת. הוא לא בודק את ממוצעי הציונים עצמם. הוא שואל שאלה אחת: האם השונות בקבוצה אחת שווה לשונות בשנייה?
אם Levene יוצא לא מובהק (p גדול מ-0.05), אין עדות מספקת שהשונויות שונות, ואפשר להמשיך עם המבחן הרגיל. אם Levene יוצא מובהק (p קטן מ-0.05), כמו אצלך, יש עדות שהשונויות באמת שונות, וההנחה הופרה.
הדוגמה
נסתכל על מספרים אמיתיים. הכיתה שלמדה בשיטה הרגילה: 40 תלמידות, ממוצע 69.65, סטיית תקן 8.37. הכיתה שלמדה בשיטה החדשה: 20 תלמידות, ממוצע 77.65, סטיית תקן 20.04.
שימי לב לסטיות התקן. 8 מול 20. בשיטה הרגילה כולן קרובות יחסית לממוצע. בשיטה החדשה הפיזור עצום: הציונים מפוזרים על פני טווח רחב בהרבה, מצב שיכול לקרות אם חלק מהתלמידות זינקו וחלק נשארו מאחור. השונות (סטיית התקן בריבוע) גדולה כמעט פי שש בקבוצה החדשה.
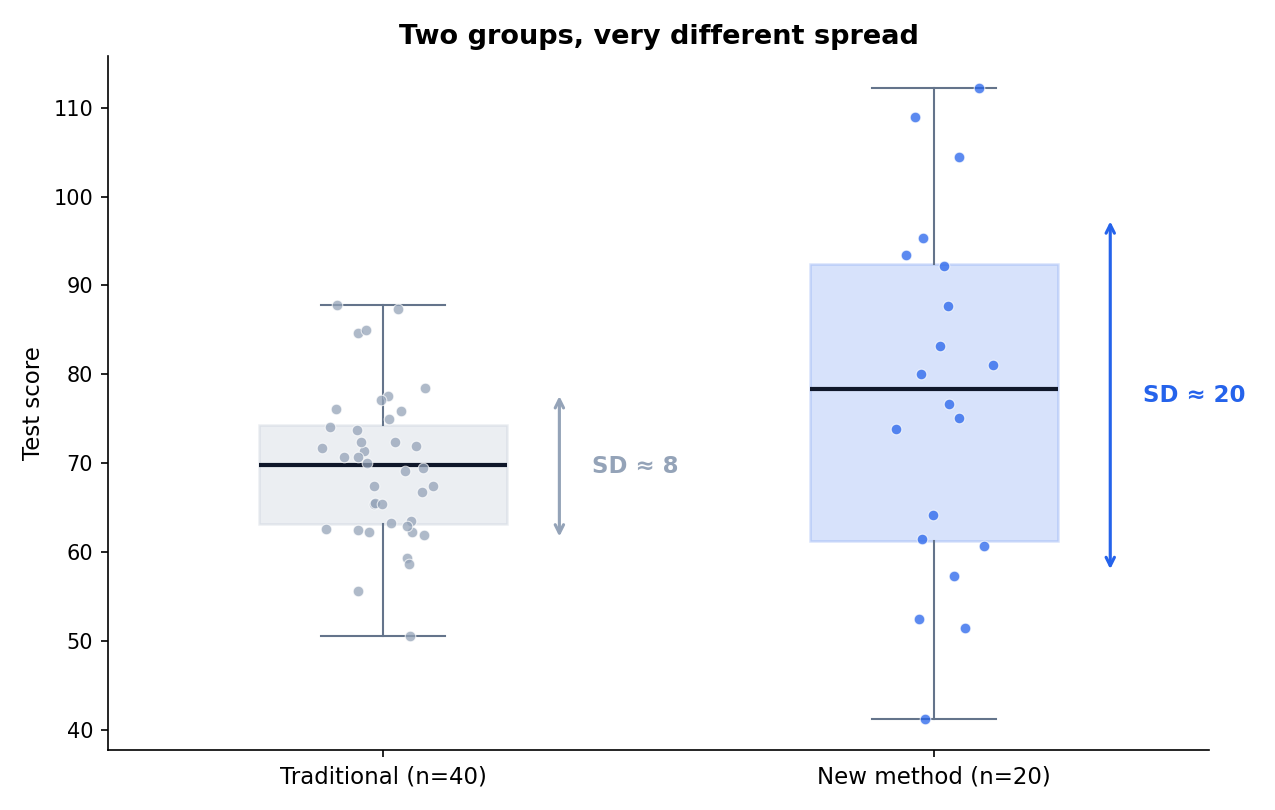
זה בדיוק מה ש-Levene תופס. במקרה שלנו הוא מחזיר ערך גבוה, p קטן מ-0.001. יש כאן עדות חזקה שהשונויות שונות, והן אפילו לא קרובות. קשה להניח כאן שוויון שונויות.
למה זה משנה את ה-p שלך
מבחן t רגיל, זה שנקרא מבחן t לדגימות בלתי תלויות בגרסתו הקלאסית (Student), עושה דבר אחד מרכזי: הוא מאחד את שתי השונויות למספר אחד משותף. הוא מניח שיש פיזור אמיתי אחד באוכלוסייה, ומשתמש בשתי הקבוצות יחד כדי לאמוד אותו.
כשהשונויות באמת שוות, זה הגיוני וגם יעיל. אבל כשהפער ביניהן גדול, ובמיוחד כשהקבוצה הקטנה יותר היא גם המפוזרת יותר, האיחוד הזה מטעה. הוא נותן לקבוצה הגדולה והצפופה משקל רב מדי, ומחזיר טעות תקן קטנה מדי. וטעות תקן קטנה מדי מייצרת p קטן מדי.
והשילוב המסוכן הוא לא רק שונות לא שווה, אלא שונות לא שווה יחד עם גדלי קבוצות לא שווים. כששתי הקבוצות שוות בגודלן, מבחן t הרגיל עמיד הרבה יותר להפרה הזאת. כאן יש 40 מול 20, וזה בדיוק הצירוף שמכשיל אותו.
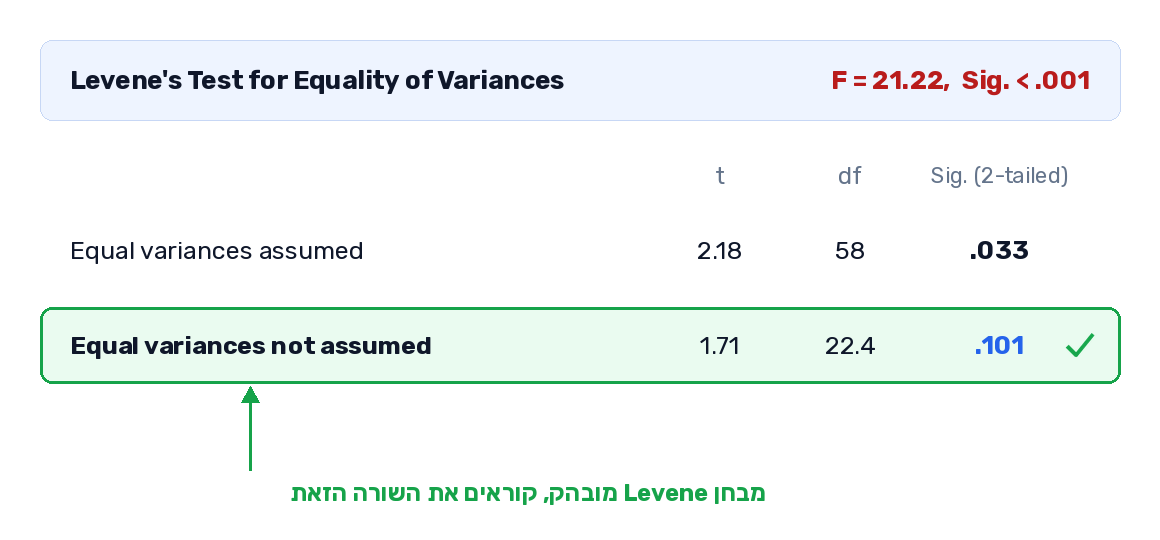
הנה זה בפועל. על אותם נתונים בדיוק, מבחן Student (דו-צדדי) מחזיר t(58) = 2.18, p = 0.033. מובהק. היית מתפתה לכתוב שהשיטה החדשה עדיפה.
אותם נתונים, מבחן אחר, מסקנה הפוכה
עכשיו נריץ את הגרסה שלא מניחה שוויון שונויות. היא נקראת מבחן Welch, וה-SPSS נותן לך אותה באותה טבלה בדיוק, בשורה "Equal variances not assumed".
Welch לא מאחד את השונויות. הוא מתייחס לכל קבוצה בנפרד, ומשלם על זה מחיר בדרגות החופש: הן צונחות מ-58 ל-22.4. פחות דרגות חופש זה פחות ביטחון, וזה בדיוק הביטחון שלא היה לך מלכתחילה, כי הפיזור בקבוצה אחת היה עצום.
התוצאה: t(22.4) = 1.71, p = 0.101. לא מובהק.
קראי את שני המספרים זה לצד זה. אותן 60 תלמידות, אותם ציונים, אותו הפרש של 8 נקודות בממוצע. מבחן אחד אומר מובהק (p = 0.033), השני אומר לא מובהק (p = 0.101). כל ההבדל הוא בשאלה אחת: האם הנחת ששתי הקבוצות מתפזרות אותו דבר. הן לא, ולכן המובהקות של Student כאן היא בעיקר תוצר של הנחה שגויה.
זאת בדיוק הסכנה. בלי להסתכל על שורת Levene, היית מדווחת על תוצאה מובהקת שנשענת על הנחה שגויה, ולכן אינה הבחירה התקפה כאן.
אז מה עושים
הכלל פשוט. בגישה המקובלת ב-SPSS, שורת Levene היא לא חלק מהתוצאה שלך, אלא ההוראה איזו תוצאה לקרוא.
אם Levene לא מובהק (p מעל 0.05), אין עדות ברורה להפרת ההנחה, ובגישה הקלאסית קוראים את שורת "Equal variances assumed".
אם Levene מובהק (p מתחת ל-0.05), קראי את שורת "Equal variances not assumed". מבחן Welch הוא התשובה שלך.
יש גם גישה שהולכת ומתקבעת בספרות: פשוט להשתמש ב-Welch תמיד. כשהשונויות שוות הוא כמעט זהה ל-Student, וכשהן לא, הוא מתקן. הוא כמעט לא עולה דבר, ומגן עלייך מהמלכודת הזאת מראש. אם המנחה לא דורש אחרת, זו ברירת מחדל סבירה לחלוטין.
וב-ANOVA?
אותו רעיון בדיוק. גם ANOVA חד-כיוונית מניחה שוויון שונויות בין הקבוצות, וגם שם Levene הוא הבדיקה. אם הוא יוצא מובהק, זה לא אומר שה-ANOVA הרגילה אסורה, אבל כדאי לשקול את הגרסה של Welch (או חלופה בשם Brown-Forsythe), במיוחד כשגדלי הקבוצות אינם שווים. אותו היגיון, יותר משתי קבוצות.
אל תבלבלי בין שתי ההנחות
שוויון שונויות הוא לא אותה הנחה כמו נורמליות. Levene בודק אם שתי הקבוצות מתפזרות באותה עוצמה. מבחן Shapiro-Wilk בודק אם הנתונים בכלל מתפלגים נורמלית. אלה שתי שאלות נפרדות, עם שני מבחנים נפרדים, ועם שני פתרונות שונים כשהן מופרות. כשהמנחה מדבר על "ההנחות של מבחן t", הוא בדרך כלל מתכוון לשתיהן יחד.
איך לדווח
בפרק הממצאים, משפט אחד שמתעד את הבדיקה ואת הבחירה שנגזרה ממנה. "מבחן Levene הצביע על הפרת הנחת שוויון השונויות (p < .001), ולכן נעשה שימוש במבחן t של Welch. לא נמצא הבדל מובהק בין השיטות, t(22.4) = 1.71, p = .101, הפרש ממוצעים = 8.00, 95% CI [-1.68, 17.68]." את מתעדת שראית את הבעיה, ושבחרת את המבחן שמתמודד איתה.
רווח הסמך הזה חוצה את האפס, אבל נמתח עד כמעט 18 נקודות. במילים אחרות, הנתונים עוד תואמים גם להיעדר הבדל וגם להבדל גדול. בדיוק לכן כדאי לצרף גודל אפקט ורווח סמך, ולא להישען על ה-p לבדו.
הערה קטנה: הערך המספרי של Levene יכול להשתנות מעט בין תוכנות, לפי שיטת החישוב הפנימית. ההחלטה, מובהק או לא, היא מה שחשוב, והיא יציבה.
ועוד דבר: בדרך כלל לא מדווחים על Levene עצמו כממצא מחקרי. הוא לא השערת המחקר שלך, אלא כלי ניווט שאומר איזו שורת תוצאה לקרוא.
שורת Levene לא נמצאת בפלט כדי להכשיל אותך. היא נמצאת שם כדי לומר לך איזו משתי השורות שמתחתיה היא הנכונה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.