מבחן Mann-Whitney: להשוות שתי קבוצות לפי דירוגים, לא ממוצעים

יש לך שתי קבוצות, התערבות וביקורת, ומדד אחד בסולם של 1 עד 7. הרצת מבחן t, ואז המנחה עצר אותך: "המדגם קטן והנתונים לא נורמליים, תעברי למבחן לא פרמטרי". הוא אמר Mann-Whitney, ואת לא בטוחה מה המבחן הזה בכלל משווה.
זאת שאלה טובה, כי Mann-Whitney לא משווה את מה שנדמה. הוא לא בודק ממוצעים. בואי נראה מה הוא כן עושה, דרך דוגמה אחת.
למה לא פשוט להשוות ממוצעים
מבחן t שואל שאלה על ממוצעים: האם הממוצע של קבוצה אחת רחוק מספיק מהממוצע של השנייה. לפעמים זאת בדיוק השאלה הנכונה. אבל על סולם סדיר של 1 עד 7, הממוצע הוא סיכום קצת מאולץ. ממוצע של 5.17 על פריט ליקרט לא באמת אומר ש"התלמידה הטיפוסית ענתה 5.17", כי אי אפשר לענות 5.17. וגם המרחקים אינם בהכרח שווים: לא בטוח שהמרחק בין 1 ל-2 זהה למרחק בין 6 ל-7, והממוצע מניח שכן.
במדגם קטן עם נתונים סדירים כאלה, ובמיוחד כשההתפלגות עקומה, השאלה הטבעית יותר היא לא "מה ההפרש בין הממוצעים" אלא "האם קבוצה אחת נוטה לקבל ציונים גבוהים יותר". כאן נכנס Mann-Whitney. הוא לא מתקן את מבחן t ולא בא להחליף אותו בכוח. הוא פשוט שואל את השאלה השנייה.
מה Mann-Whitney באמת עושה: דירוג
הרעיון יפה בפשטותו. תשכחי מהציונים הגולמיים לרגע. קחי את כל 35 התלמידות משתי הקבוצות יחד, וסדרי אותן בשורה אחת מהמוטיבציה הנמוכה ביותר לגבוהה ביותר. עכשיו תני לכל אחת דירוג, מ-1 עד 35.
ואז שאלה אחת: האם תלמידות ההתערבות נוטות להתמקם גבוה יותר בשורה?
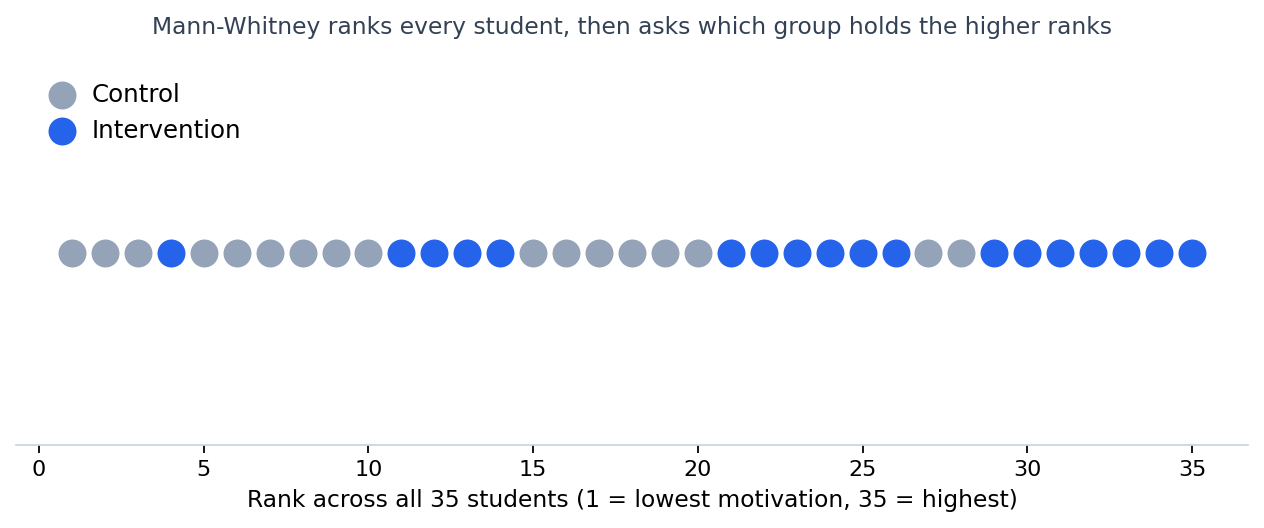
הביקורת מצטופפת בדירוגים הנמוכים, ההתערבות בגבוהים. יש חפיפה באמצע, וזה חשוב, אבל הנטייה ברורה. אפשר לכמת אותה בשתי דרכים. הראשונה: הדירוג הממוצע בקבוצת ההתערבות הוא 24.4, ובביקורת רק 11.2.
השנייה היא המספר שהמבחן מחזיר, U. בפשטות, U סופר כמה פעמים תלמידת התערבות מקבלת ציון גבוה יותר מתלמידת ביקורת, כשתיקו נספר כחצי. יש כאן 18 כפול 17, כלומר 306 זוגות אפשריים, ומתוכם ההתערבות גבוהה יותר ב-269. מכאן:
U = 269, p < .001
ה-p אומר שאם הקבוצות לא נבדלו זו מזו באוכלוסייה, פיצול דירוגים לא מאוזן כמו שראינו היה קורה רק לעיתים נדירות מאוד. לכן דוחים את ההנחה הזאת. יש הבדל בין הקבוצות.
כמה גדול ההבדל, בשפה של בני אדם
כמו תמיד, מובהק זה לא אותו דבר כמו גדול. ה-p הראה שקשה ליישב את הנתונים עם היעדר הבדל. עכשיו גודל האפקט אומר כמה ההבדל גדול.
אפשר לתרגם את תוצאת Mann-Whitney לגודל אפקט אינטואיטיבי במיוחד שנקרא CLES, וכאן הוא יוצא 0.88. שימי לב שזה בדיוק אותו 269 חלקי 306 מקודם. הנה הפירוש: תבחרי באקראי תלמידה אחת מההתערבות ותלמידה אחת מהביקורת. בכ-81% מהזוגות תלמידת ההתערבות מקבלת ציון גבוה ממש, ובעוד כ-14% השתיים שוות. כשסופרים תיקו כחצי נקודה, מגיעים ל-88%. זה גודל האפקט, בשפה שאפשר להגיד לוועדה.
יש גם מדד מקובל נוסף, מתאם דו-סדרתי של דירוגים (rank-biserial r), שכאן יוצא 0.76. לפי כללי האצבע (0.1 קטן, 0.3 בינוני, 0.5 גדול), זה אפקט גדול. שני המספרים מראים את אותה תמונה: ההבדל לא רק קיים, הוא מהותי.
מה מותר לך להגיד בעקבות המבחן, ומה לא
הרבה מורים לסטטיסטיקה מלמדים ש-Mann-Whitney הוא "מבחן לחציונים". זה נכון רק כשלשתי ההתפלגויות יש בערך אותה צורה. במדויק יותר, המבחן בודק האם קבוצה אחת נוטה להציג ערכים גבוהים מהשנייה, לא האם החציון שלה גבוה במספר מסוים.
בפועל זה אומר שהניסוח הנכון בפרק התוצאות הוא לא "הממוצע עלה" ולא "החציון השתנה ב-2 נקודות", אלא "קבוצת ההתערבות נטתה לדווח על מוטיבציה גבוהה יותר". את מדווחת את החציונים כתיאור (התערבות 5, ביקורת 3), ואת המסקנה כנטייה.
איך מדווחים
שורת דיווח מסודרת כוללת חציונים, את שם המבחן, U, p וגודל אפקט. למשל:
קבוצת ההתערבות (חציון 5) דיווחה על מוטיבציה גבוהה יותר מקבוצת הביקורת (חציון 3), מבחן Mann-Whitney, U = 269, p < .001, r = .76.
שורה אחת שאומרת את שלושת הדברים: יש הבדל, באיזה כיוון, וכמה הוא חזק.
מתי זה המבחן הנכון
Mann-Whitney הוא המבחן לשתי קבוצות בלתי תלויות, כשהנתונים סדירים (כמו ליקרט) או כשהמדגם קטן וההתפלגות לא נורמלית. זו המקבילה הלא פרמטרית של מבחן t לקבוצות בלתי תלויות.
אם המבנה שלך שונה, אותן נבדקות שנמדדו לפני ואחרי, זה כבר תכנון מזווג, והכלי הלא פרמטרי שלו הוא מבחן Wilcoxon לדגימות מזווגות. שם מדרגים את ההפרשים בתוך כל זוג, ולא את כל הציונים יחד, ולכן הוא מתאים בדיוק לתכנון שבו כל נבדקת משמשת לעצמה כביקורת.
בשני המקרים, המעבר למבחן לא פרמטרי הוא לא ויתור ולא "פלן B" מביך. הוא בחירה מדויקת בכלי שמתאים למה שיש לך ביד: מדד סדיר, מדגם קטן, או התפלגות שמסרבת להיות נורמלית. הדירוגים פשוט שואלים את השאלה הנכונה כשהממוצע לא מתאים.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.