המנחה אמר "אל תריצי ANOVA לכל תת-סולם": מתי צריך MANOVA

הגעת לפרק הממצאים של התזה. השאלה שלך היא אם תוכנית התערבות מלווה ברווחה נפשית גבוהה יותר אצל סטודנטיות בשנה א'. 50 משתתפות, 25 שנרשמו לתוכנית ו-25 בקבוצת ביקורת (ההרשמה הייתה וולונטרית, לא הקצאה אקראית, ונחזור לזה בסוף). את לא מדדת "רווחה" כציון אחד. מדדת אותה בשאלון עם שלושה תת-סולמות: רגש חיובי, שביעות רצון מהחיים, וחיוניות. שלושתם בסולם 1 עד 6, ושלושתם קשורים זה לזה (מי שמדווחת על רגש חיובי גבוה נוטה לדווח גם על חיוניות גבוהה).
היד כבר על העכבר. שלושה משתנים תלויים, אז שלושה מבחני ANOVA, אחד לכל תת-סולם. והמנחה עוצר אותך: "אל תריצי ANOVA לכל תת-סולם בנפרד. תריצי MANOVA."
שאלה ראשונה, ולגיטימית לגמרי: למה לא שלושה מבחנים נפרדים. הם פשוטים, את כבר יודעת לקרוא אותם, וכל אחד עונה על שאלה ברורה.
למה לא שלושה ANOVA נפרדים
שתי בעיות, אחת מוכרת ואחת פחות.
הבעיה המוכרת היא ניפוח הטעות. כל מבחן ב-α = 0.05 נושא 5% סיכון לטעות מסוג ראשון, ועם שלושה מבחנים ההסתברות לטעות באחד מהם לפחות עולה אל מעל ל-5%. זו אותה לוגיקה של ריבוי מבחנים שכבר פירקנו לגורמים בפוסט על מבחני post-hoc, רק ששם הריבוי היה של זוגות קבוצות, וכאן הריבוי הוא של משתנים תלויים. המנגנון זהה והתיקונים שם תקפים גם פה.
הבעיה הפחות מוכרת היא עמוקה יותר, וזו הסיבה האמיתית שהמנחה ביקש MANOVA. שלושה מבחנים נפרדים שואלים שלוש שאלות נפרדות: "האם הקבוצות נבדלות ברגש חיובי?", "האם הן נבדלות בשביעות רצון?", "האם הן נבדלות בחיוניות?". אף אחת מהן לא שואלת את השאלה שבאמת מעניינת אותך: האם הקבוצות נבדלות ברווחה, כמכלול. שלושת התת-סולמות הם פנים של אותו מבנה, ושלושה מבחנים נפרדים מתעלמים מהעובדה שהם קשורים זה לזה. הם מתייחסים לכל תת-סולם כאילו הוא עומד בפני עצמו.
מה MANOVA בעצם שואלת
MANOVA (Multivariate Analysis of Variance) לוקחת את שלושת המשתנים התלויים יחד, בניתוח אחד, ושואלת שאלה אחת: האם הקבוצות נבדלות על צירוף כלשהו של שלושת התת-סולמות.
זה הרעיון המרכזי, וכדאי להישאר איתו רגע. MANOVA לא בודקת כל משתנה בנפרד. היא מחפשת שילוב משוקלל של שלושת התת-סולמות, מין "ציון רווחה מורכב" שנבנה מהנתונים עצמם כך שיפריד בין הקבוצות בצורה החדה ביותר האפשרית. אחר כך היא בודקת אם ההפרדה הזו גדולה מכדי להיות מקרית. מתי הצירוף הזה חושף הבדל שאף משתנה בודד לא חושף בבירור? לא תמיד, ולא סתם כי המשתנים קשורים. זה תלוי במבנה הקשר ביניהם ובכיוון ההבדל, ושתי הדוגמאות למטה יראו לך בדיוק את ההבדל.
וכבונוס, היא עושה את כל זה במבחן רב-משתני אחד, עם שיעור טעות אחד. אין כאן שלושה מבחנים שמנפחים את הסיכון. יש מבחן אחד שמכריע על השאלה הרב-משתנית.
מאיפה מגיע המספר: Wilks' Lambda
ב-ANOVA חד-משתנית, ה-F בנוי על יחס בין שונות בין-קבוצתית לשונות בתוך-קבוצתית. ב-MANOVA אין משתנה אחד, יש שלושה, וגם מטריצת השונויות-המשותפות ביניהם. לכן הסטטיסטי הנפוץ אינו F ישיר אלא Wilks' Lambda, שמסומן Λ.
בלי להיכנס לאלגברה של מטריצות, אפשר לתפוס את Λ כך. הוא היחס בין השונות (הרב-משתנית) שנשארת בתוך הקבוצות לבין השונות הרב-משתנית הכוללת. במילים אחרות, החלק מהשונות שהקבוצה לא מסבירה.
Λ = |W| / |T|
כאן W היא מטריצת השונות בתוך הקבוצות (השארית), ו-T מטריצת השונות הכוללת. הסימן |·| הוא הדטרמיננטה, הכללה רב-משתנית של "גודל" השונות.
שני קצוות עוזרים לקרוא את Λ:
- Λ קרוב ל-1 פירושו שכמעט כל השונות נשארת בתוך הקבוצות. הקבוצות כמעט לא נבדלות. אין אפקט.
- Λ קרוב ל-0 פירושו שמעט מאוד שונות נשארת בתוך הקבוצות. רוב ההפרדה היא בין הקבוצות. אפקט חזק.
שימי לב לכיוון ההפוך מ-η². ב-ANOVA, ערך גבוה = אפקט חזק. ב-Λ, ערך נמוך = אפקט חזק. זו טעות קריאה נפוצה בפלט של SPSS.
גודל האפקט הרב-משתני נגזר ישירות מ-Λ:
partial η² = 1 − Λ^(1/s), כאשר s = min(p, g−1)
p הוא מספר המשתנים התלויים ו-g מספר הקבוצות. כשיש שתי קבוצות בלבד, g − 1 = 1, ולכן s = 1, והנוסחה מצטמצמת ל-partial η² = 1 − Λ. נקי. בשתי קבוצות, SPSS גם ממיר את Λ ל-F מדויק (לא קירוב), כך שתקבלי בפלט גם F עם דרגות חופש, וגם ערך p.
הדוגמה הראשונה: כשהתת-סולמות מסכימים זה עם זה
נתחיל בתיאור הנתונים של מחקר הרווחה: הממוצעים בכל תת-סולם, ומבחן ANOVA חד-משתני לכל אחד בנפרד (זה מה שהיית מקבלת אם היית מתעקשת על שלושה מבחנים), כולל גודל אפקט d ורווח הסמך שלו.
| תת-סולם | תוכנית M (SD) | ביקורת M (SD) | F(1,48) | p | d [95% CI] |
|---|---|---|---|---|---|
| רגש חיובי | 4.32 (0.71) | 3.96 (0.78) | 2.88 | .096 | 0.48 [−0.08, 1.04] |
| שביעות רצון | 4.18 (0.69) | 3.89 (0.74) | 2.10 | .154 | 0.41 [−0.15, 0.97] |
| חיוניות | 4.05 (0.80) | 3.71 (0.83) | 2.21 | .144 | 0.42 [−0.14, 0.98] |
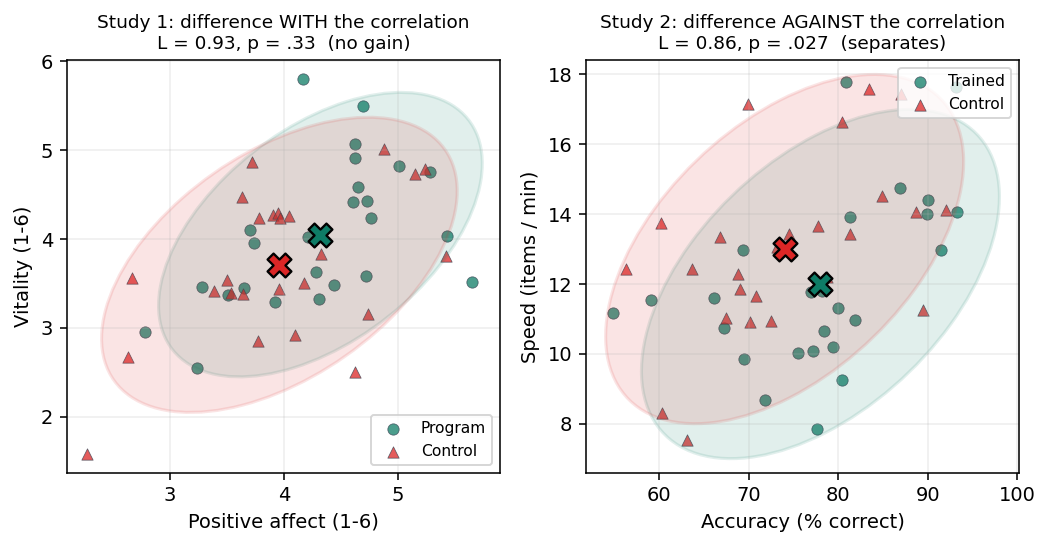
תקראי את השורות לרגע. בכל שלושת התת-סולמות קבוצת התוכנית גבוהה מהביקורת, וההפרשים בכיוון אחיד. גדלי האפקט בינוניים-קטנים (d בין 0.41 ל-0.48), אבל אף אחד משלושת המבחנים לא חוצה את סף המובהקות. ה-p הנמוך ביותר הוא 0.096. ורווחי הסמך של כל שלושת ה-d-ים חוצים את האפס, מה שעקבי עם אי-המובהקות: עם 25 בכל קבוצה, אין כאן מספיק כוח כדי לקבע אפקט קטן-בינוני בשום תת-סולם בנפרד.
עכשיו המבחן הרב-משתני, ה-MANOVA על שלושת התת-סולמות יחד. במחקר הזה, התת-סולמות מתואמים זה עם זה בחיוב, בערך r = .5 בתוך הקבוצות (מי שגבוהה באחד נוטה להיות גבוהה גם באחרים):
Wilks' Λ = 0.93, F(3, 46) = 1.17, p = .33, partial η² = .07(90% CI מקורב [.00, .16]).
וכאן ההפתעה הראשונה, וההפוכה ממה שאולי קיווית: גם המבחן הרב-משתני אינו מובהק. צירוף שלושת התת-סולמות לא חשף הבדל שהמבחנים הבודדים פספסו. אם משהו, הוא חלש מהמבחן הבודד החזק ביותר.
למה? כי שלושת התת-סולמות קשורים זה לזה בחיוב והם זזים יחד, באותו כיוון. כשמידע "חופף" ככה, הצירוף לא מוסיף הרבה מעבר למשתנה בודד. שלוש מדידות עקביות וחיוביות של אותו דבר אינן שלוש עדויות בלתי-תלויות, הן שלוש חזרות על אותה עדות. זו בדיוק התצורה שבה MANOVA נוטה לאבד כוח לעומת המבחנים החד-משתניים, לא להרוויח. אז את האמונה הרווחת ש-MANOVA "מצרפת אפקטים חלשים ועקביים לתוצאה חזקה" אפשר להניח בצד. במקרה השכיח של תת-סולמות מתואמים שזזים יחד, זה פשוט לא מה שקורה.
הביט הקשה: מתי MANOVA כן חושפת מה שאף מבחן בודד לא
אז מתי MANOVA כן עושה את הקסם שמייחסים לה? כשהמבנה הפוך. הנה דוגמה שנייה, עם אותו גודל מדגם בדיוק, שבה זה קורה.
מחקר על שיטת למידה. 25 סטודנטיות שעברו אימון מול 25 בביקורת, ושני משתנים תלויים: דיוק (אחוז תשובות נכונות במבחן) ומהירות (פריטים לדקה). בתוך כל קבוצה, השניים מתואמים בחיוב (r ≈ .5): סטודנטיות חזקות נוטות להיות גם מדויקות וגם מהירות. אבל האימון מלמד עבודה זהירה, אז הקבוצה המאומנת מדויקת יותר אך גם איטית יותר. כלומר ההבדל בין הקבוצות רץ נגד מבנה המתאם הפנימי.
| משתנה תלוי | מאומנות M (SD) | ביקורת M (SD) | F(1,48) | p | d [95% CI] |
|---|---|---|---|---|---|
| דיוק (% נכון) | 78.0 (10.0) | 74.0 (10.0) | 2.00 | .164 | 0.40 [−0.16, 0.96] |
| מהירות (פריט/דק׳) | 12.0 (2.5) | 13.0 (2.5) | 2.00 | .164 | −0.40 [−0.96, 0.16] |
כל מבחן בודד לא מובהק, שניהם p = .16, שני רווחי הסמך חוצים את האפס. עכשיו ה-MANOVA:
Wilks' Λ = 0.86, F(2, 47) = 3.92, p = .027, partial η² = .14(90% CI מקורב [.01, .28]).
הפעם זה קרה: כל מבחן חד-משתני אינו מובהק, אבל הרב-משתני כן (p = .027). למה כאן ולא בדוגמה הראשונה? כי כאן ההבדל בין הקבוצות גר בכיוון שבתוך הקבוצות כמעט אין בו שונות. תארי לעצמך ענן נקודות שמתמשך באלכסון "גבוה-גבוה / נמוך-נמוך" (זה המתאם החיובי: מי שמדויקת גם מהירה). ההבדל בין הקבוצות שלנו רץ באלכסון השני, "מדויקת-ואיטית" מול "פחות-מדויקת-ומהירה". בכיוון הזה הקבוצות מופרדות היטב, גם אם על כל ציר בנפרד הן חופפות. MANOVA בונה בדיוק את הצירוף הזה ומודדת אותו.
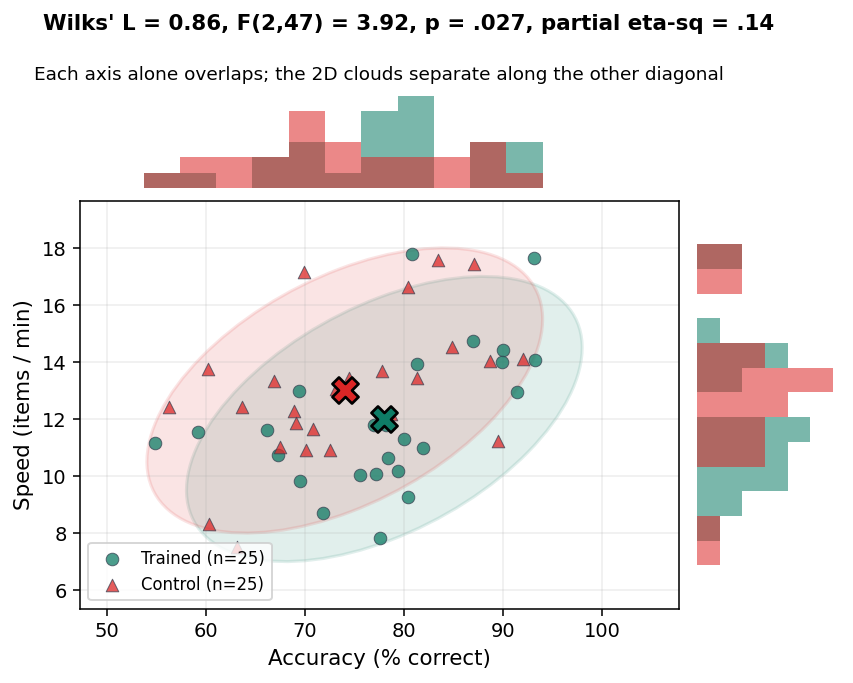
שימי לב מה הפך את הדוגמאות: לא עצם קיומו של מתאם, אלא הכיוון של ההבדל ביחס למתאם. בדוגמה הראשונה ההבדל רץ עם המתאם, והרווח נעלם (אפילו הפך להפסד). בדוגמה השנייה ההבדל רץ נגד המתאם, והרווח דרמטי. לכן "MANOVA מובהקת, אף ANOVA לא" היא תוצאה אפשרית ומאירת-עיניים, לא הבטחה, ובוודאי לא תכונה אוטומטית של MANOVA. תצורות כמו זו השנייה דורשות ניגוד בין כיוון ההבדל למבנה המתאם, למשל אפקטים שרצים בכיוונים מנוגדים על משתנים מתואמים.
מתי MANOVA מוצדקת, ומתי עדיף ANOVA נפרדים עם תיקון
הטעות הנפוצה היא להניח ש-MANOVA תמיד "נכונה יותר" כשיש כמה משתנים תלויים. לא. השאלה היא מה את באמת רוצה לדעת.
MANOVA אינה משודרגת אוטומטית רק כי יש כמה תוצאות. שלושה תנאים צריכים להתקיים יחד לפני שמריצים אותה: שהמשתנים התלויים קשורים זה לזה תיאורטית (פנים של אותו מבנה, לא תוצאות זרות שנערמו יחד), שהם מתואמים במידה סבירה בפועל, ושעומדת מאחוריהם שאלה רב-משתנית אחת אמיתית. בלי שלושת אלה, ערימת משתנים לא קשורים תחת מבחן אחד לא מרוויחה דבר, ולעתים אף שוחקת כוח לעומת מבחנים נפרדים.
MANOVA מתאימה כאשר:
- יש לך שאלה רב-משתנית אמיתית: "האם הקבוצות נבדלות בפרופיל הכולל". זו ההצדקה החזקה ביותר, והיא תקפה גם כשהמבחן הרב-משתני יוצא חלש, כי הוא עדיין השואל הנכון.
- המשתנים קשורים זה לזה. שימי לב: עצם המתאם לא מבטיח רווח בכוח. כפי שראית, הרווח תלוי אם ההבדל בין הקבוצות רץ עם המתאם או נגדו. אם הם בלתי תלויים לחלוטין, השילוב המשוקלל לא מוסיף הרבה מעבר למבחנים נפרדים.
- יש לך מספיק נבדקות. ככלל אצבע, n בתוך כל קבוצה צריך לעלות על מספר המשתנים התלויים, ורצוי בהרבה. הרבה משתנים תלויים עם מדגם קטן שוחקים כוח ופוגעים ביציבות.
עדיף ANOVA נפרדים עם תיקון כאשר:
- המשתנים התלויים אינם מבנה אחד אלא תוצאות נפרדות מבחינה תיאורטית (ציון מבחן, שעות שינה, שביעות רצון מהקורס), ואין שאלה רב-משתנית שמעניינת אותך. אז כל משתנה הוא שאלה לעצמו.
- במקרה כזה, הריצי ANOVA לכל משתנה ותקני את הסף לריבוי המבחנים. אילו תיקונים, ולמה Bonferroni לעומת Holm, פירקנו בפוסט על מבחני post-hoc. אותם תיקונים בדיוק, רק שכאן הריבוי הוא על פני משתנים ולא על פני זוגות.
הערה על הנחות: MANOVA דורשת נורמליות רב-משתנית והומוגניות של מטריצות השונות-המשותפת בין הקבוצות (זה מה ש-Box's M בודק). היא רגישה יותר מ-ANOVA לחריגות מההנחות וגם להפרשי גודל בין קבוצות, אז שווה לבדוק את ההנחות לפני שמסתמכים על ה-p.
מה עושים אחרי MANOVA מובהקת
נישאר עם הדוגמה השנייה, זו שיצאה מובהקת. MANOVA מובהקת אומרת: הקבוצות נבדלות על הפרופיל הרב-משתני. היא לא אומרת איפה, על איזה משתנה. בדיוק כמו ש-ANOVA מובהקת לא אומרת בין אילו קבוצות יושב ההבדל. צריך מעקב.
המסלול הסטנדרטי בעבודות תזה הוא univariate follow-up: אחרי MANOVA מובהקת, מריצים ANOVA חד-משתני לכל משתנה תלוי, ומתקנים את הסף לריבוי המבחנים (אותם תיקונים מהפוסט על post-hoc). הרעיון הוא ש-MANOVA משמשת "שומר סף": רק אם המבחן הרב-משתני עבר, ממשיכים לבדוק את המשתנים הבודדים. זה נותן שכבת הגנה מסוימת מפני ניפוח טעות.
אל תעצרי ב-Wilks' Lambda. ה-Λ אומר רק שיש הבדל בפרופיל הרב-משתני, ולא יותר מזה. כדי לדעת מה ההבדל הזה, בדקי את המבחנים החד-משתניים (או ניגודים מתוכננים, אם הייתה לך השערה ממוקדת מראש) עם תיקון לסף, וקראי את התבנית שעולה מהם: על אילו משתנים יושב ההבדל, ובאיזה כיוון על כל אחד. הסיפור הוא בתבנית, לא במספר הרב-משתני לבדו.
וכאן הדוגמה שלנו מכריחה אותך להתבגר. אחרי MANOVA מובהקת, אף אחד משני ה-ANOVA-ים החד-משתניים לא חוצה את הסף, גם לא את הסף הלא-מתוקן (שניהם p = .16), קל וחומר אחרי תיקון. מה כותבים אז?
כותבים את האמת, וזו אמת מעניינת, לא כישלון: הקבוצות נבדלות בפרופיל הרב-משתני (Λ = .86, p = .027, partial η² = .14), אבל ההבדל לא יושב בדיוק לבדו ולא במהירות לבדה. הוא חי בצירוף, ב"יחס" שבין דיוק למהירות. הקבוצות נבדלות באיזון בין השניים (מדויקות-ואיטיות מול פחות-מדויקות-ומהירות), לא בשום ציר בודד. זו טענה לגיטימית ומדויקת, ובמקרים רבים מעניינת יותר מ"משתנה X עלה".
אם רוצים לרדת לשאלה "איזה שילוב של המשתנים מפריד בין הקבוצות", הכלי הקפדני יותר הוא ניתוח מבחין תיאורי (descriptive discriminant analysis), שמתאר את אותו צירוף משוקלל שה-MANOVA בנתה ואת המשקל היחסי של כל משתנה בו. זה מעבר למסלול הבסיסי, ולא כל ועדה תצפה לו בתזה, אבל שווה להכיר את שמו.
הערה אחת על שפה, וחשובה: שני המחקרים כאן משווים קבוצות, אז מותר לדבר על הבדל בין הקבוצות. אבל בשניהם ההקצאה לקבוצות לא הייתה אקראית (הנבדקות בחרו להשתתף), אז הימנעי מניסוח סיבתי כמו "האימון שיפר" או "ההתערבות השפיעה". תארי שהקבוצות נבדלות, ושמרי טענה סיבתית למערך שבאמת תומך בה, כלומר הקצאה אקראית.
מה לקחת מפה לעבודה שלך
- אם יש לך שאלה רב-משתנית אמיתית על הפרופיל, MANOVA היא השאלה הנכונה. היא בודקת אם הקבוצות נבדלות בפרופיל הכולל, לא בכל רכיב לחוד, ועושה זאת במבחן יחיד בלי לנפח את שיעור הטעות. זו ההצדקה שלה גם כשהתוצאה יוצאת חלשה.
- MANOVA היא לא מכונה שמצרפת אפקטים חלשים לתוצאה חזקה. כשהמשתנים התלויים מתואמים בחיוב וההבדלים רצים באותו כיוון (התצורה השכיחה לתת-סולמות של מבנה אחד), היא נוטה לאבד כוח, לא להרוויח. הרווח הדרמטי מגיע דווקא כשההבדל בין הקבוצות רץ נגד מבנה המתאם הפנימי.
- אם המשתנים התלויים הם תוצאות נפרדות מבחינה תיאורטית, אל תכריחי MANOVA. הריצי ANOVA לכל אחד ותקני את הסף לריבוי המבחנים (ראי את הפוסט על post-hoc). שאלות נפרדות, מבחנים נפרדים, סף מתוקן.
- קראי את Wilks' Lambda בכיוון הנכון. Λ נמוך = אפקט חזק (הפוך מ-η²). בשתי קבוצות,
partial η² = 1 − Λ, ו-SPSS ייתן לך F מדויק עם p. - אל תדווחי רק את ה-p הרב-משתני. דווחי
Λ, את ה-F עם דרגות החופש, את ערך p, ואתpartial η²כגודל אפקט. הוסיפי את הממוצעים והסטיות בכל משתנה כדי שהקוראת תראה את הפרופיל. - MANOVA מובהקת היא תחילת המעקב, לא סופו. המשיכי ל-ANOVA חד-משתני לכל משתנה עם תיקון. ואם אף משתנה בודד לא שורד את התיקון, זו תוצאה אמיתית: ההבדל חי בצירוף בין המשתנים, לא בציר בודד. כתבי את זה ככה, במדויק, בלי לייפות ובלי להתנצל.
- בדקי הנחות לפני שאת סומכת על המספר. נורמליות רב-משתנית, הומוגניות מטריצות השונות (Box's M), ו-n בתוך כל קבוצה גדול ממספר המשתנים התלויים. MANOVA רגישה לחריגות יותר מ-ANOVA.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.