כמה נבדקות צריך? גודל מדגם וכוח סטטיסטי לפני שמתחילים לאסוף

את יושבת על הצעת המחקר. השאלה ברורה: האם תוכנית כתיבה מונחית מעלה תחושת מסוגלות אקדמית אצל סטודנטיות שנה א', בהשוואה לקבוצה שלא קיבלה את התוכנית. שני משתנים, תכנון של שתי קבוצות בלתי-תלויות, שאלון מסוגלות מתוקף על סולם רציף. הכל מסודר בראש שלך, חוץ ממשפט אחד שהמנחה ביקש להוסיף לפני האישור: "כמה נבדקות את מתכננת לגייס, ולמה דווקא המספר הזה?"
וזה בדיוק המקום שבו את נתקעת. 30? 50? 100 לכל קבוצה? יש לך תחושה שכל מספר שתכתבי ייראה שרירותי, כי הוא באמת שרירותי כרגע. השאלה הזאת, כמה נבדקות צריך, היא לא ניחוש. יש לה תשובה מספרית, והיא נשענת על ארבעה גדלים שאפשר לחשב מראש. זה מה שנקרא תכנון גודל מדגם, והמאמר הזה עוסק בו.
קודם כל: זאת שאלה אחרת מ"המחקר שלך underpowered"
אם כבר קראת על כוח סטטיסטי, כנראה פגשת אותו בהקשר ההפוך. מישהו אסף נתונים, קיבל תוצאה לא מובהקת, והמנחה אמר שהמחקר חלש מדי. זאת מסגרת של בדיעבד (post-hoc): הנתונים כבר באים, השאלה היא איך לקרוא ולדווח על מה שיצא.
כאן אנחנו במסגרת ההפוכה, של מראש (a-priori). עוד לא אספת כלום. את משתמשת בכוח כמכשיר תכנון, כדי לבחור N שייתן למחקר סיכוי הוגן לזהות את האפקט שאת מצפה לו, עוד לפני שגייסת את הנבדקת הראשונה. זה הזמן הכי טוב בעולם לעשות את החישוב הזה, כי כל מה שתחליטי עכשיו עדיין פתוח. בדיעבד אפשר רק לתאר את הגבולות של מה שכבר קרה. מראש אפשר לבחור אותם.
אותו רעיון, כוח סטטיסטי, שני שימושים שונים. בדיעבד הוא מד שמתאר מחקר שכבר רץ. מראש הוא מצפן שבוחר את גודל המדגם. המאמר הזה הוא על המצפן.
מה כוח אומר, בקצרה
הכוח הסטטיסטי הוא ההסתברות לקבל תוצאה מובהקת אם האפקט שאת מצפה לו באמת קיים באוכלוסייה. כוח של 0.80, הסטנדרט המקובל, אומר שאם ההשערה שלך נכונה, יש לך 80% סיכוי שהמבחן יזהה זאת ו-20% סיכוי שתחמיצי אפקט אמיתי. (ההרחבה המלאה על המושג נמצאת במאמר על כוח, וכאן אני לא חוזרת עליה.)
הנקודה לתכנון: כוח הוא לא תכונה קבועה של המחקר שלך. הוא תוצאה של ארבעה גדלים שמתכתבים זה עם זה. קבעי שלושה מהם, והרביעי נקבע מאליו. זה הציר של כל החישוב.
ארבעת הגדלים שקובעים את ה-N
בכל חישוב גודל מדגם יש ארבעה שחקנים. הם קשורים מתמטית, כך שברגע שאת מקבעת שלושה, הרביעי נגזר:
- רמת המובהקות (α). כמעט תמיד
0.05. זה ההסתברות המקסימלית שאת מסכימה לקחת לטעות מסוג ראשון (לטעון שיש אפקט כשאין). בדרך כלל לא נוגעים בזה. - הכוח (1 − β). את בוחרת אותו כיעד.
0.80הוא ברירת המחדל המקובלת בוועדות, יש שמכוונים ל-0.90כשהמחיר של החמצה גבוה. - גודל האפקט הצפוי. כמה גדול ההבדל או הקשר שאת מצפה לו, בשפה סטנדרטית (
Cohen's dלהבדל בין קבוצות,fל-ANOVA,f²לרגרסיה). זה הגודל היחיד מהארבעה שאת לא בוחרת באופן חופשי. את מעריכה אותו, מתוך הספרות או ממחקר חלוץ. - גודל המדגם (N). בדרך כלל זה הנעלם שאת פותרת. את מזינה את שלושת האחרים, והחישוב מחזיר לך כמה נבדקות דרושות.
הכיוון הזה, "תני לי α, כוח וגודל אפקט, ואני אחזיר לך N", הוא בדיוק ניתוח a-priori. שימי לב לכיוון הקשר בין הגדלים: כדי לזהות אפקט קטן יותר בכוח קבוע, את צריכה N גדול יותר. כדי להעלות את הכוח מ-0.80 ל-0.90 בגודל אפקט קבוע, את צריכה עוד נבדקות. שום ארוחה כאן לא חינם.
הדוגמה: כמה נבדקות לתוכנית הכתיבה
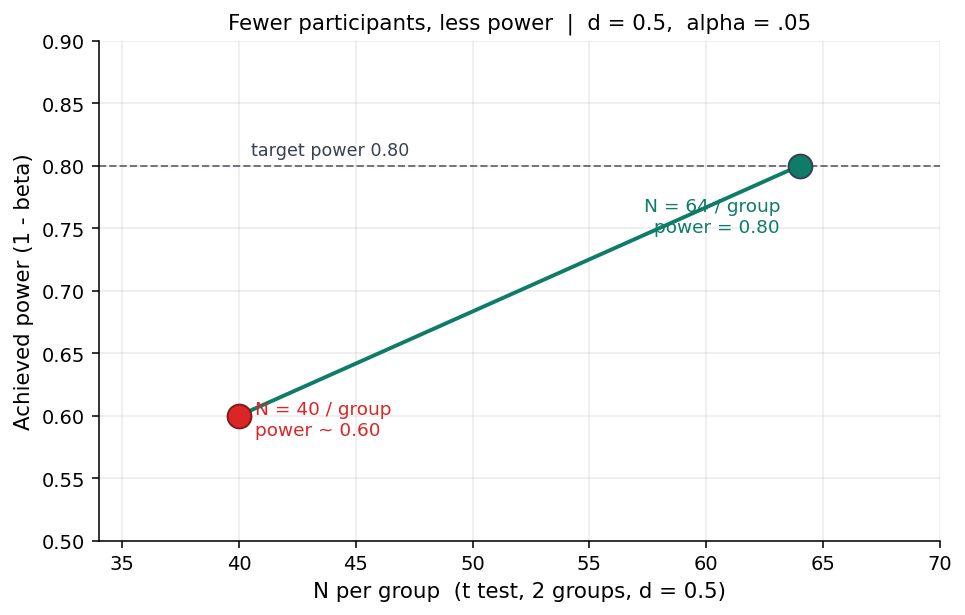
נחזור למחקר שלך. שתי קבוצות בלתי-תלויות, התערבות מול ביקורת, ואת מצפה לאפקט בגודל בינוני על סמך הספרות, d = 0.5. את מקבעת α = 0.05 דו-צדדי וכוח יעד של 0.80. את פותרת ל-N.
התוצאה: 64 נבדקות בכל קבוצה, 128 בסך הכל.
זה המספר שצריך להיכנס להצעת המחקר, יחד עם המשפט שמסביר מאיפה הוא בא: "גודל המדגם נקבע בניתוח כוח a-priori עבור מבחן t לשתי קבוצות בלתי-תלויות, d = 0.5, α = .05 דו-צדדי, כוח 0.80; נדרשות 64 נבדקות בכל קבוצה." פתאום המספר לא שרירותי. הוא נגזרת של הנחות שאת יכולה להגן עליהן.
ומה אם תוכלי לגייס בפועל רק 40 לכל קבוצה (80 בסך הכל)? אפשר להריץ את החישוב בכיוון ההפוך: עם 40 לכל קבוצה ו-d = 0.5, הכוח יורד לכ-0.60. כלומר אפילו אם ההתערבות עובדת בדיוק כמו שצפית, יש בערך 40% סיכוי שהמבחן לא יזהה זאת. זה לא פוסל את המחקר, אבל זה מספר שכדאי לדעת מראש, כדי להחליט אם להילחם על עוד נבדקות או לכתוב מראש על המגבלה.
מספרי עוגן: t, ANOVA ורגרסיה
לכל מבחן יש "מספר עוגן" משלו לאפקט בינוני, כוח 0.80 ו-α = .05. כדאי שיהיו לך בראש בערך, כדי לזהות מתי תכנון נשמע לא ריאלי. אלה ערכים מקורבים, לא תחליף לחישוב על ההנחות הספציפיות שלך:
| מבחן | אפקט בינוני | N מקורב לכוח 0.80 |
|---|---|---|
| t לשתי קבוצות בלתי-תלויות | d = 0.5 | 64 לכל קבוצה, 128 סה"כ |
| t מזווג (לפני/אחרי) | d_z = 0.5 | חסכוני בהרבה (ראי המאמר על כוח) |
| ANOVA חד-כיוונית, 3 קבוצות | f = 0.25 | כ-53 לכל קבוצה, 159 סה"כ |
| רגרסיה מרובה, 5 מנבאים | f² = 0.15 | כ-92 סה"כ |
שני דברים בולטים מהטבלה. ראשית, התכנון המזווג חסכוני בצורה דרמטית, כי כל נבדקת משמשת כביקורת של עצמה, וה-N הדרוש קטן בהרבה מאשר בתכנון בלתי-תלוי. את הערך המדויק לאותן הנחות (d_z = 0.5, כוח 0.80) ואת ההיגיון מאחורי החיסכון מראה המאמר על כוח. שנית, ככל שמספר המנבאים ברגרסיה עולה, ה-N הדרוש עולה איתו. כל מנבא נוסף הוא עוד פרמטר שצריך להעריך, ועוד דרישה על המדגם.
שלוש הערות לפני שאת מאמצת מספר. ראשית, כל ה-N-ים שמופיעים כאן ובטבלאות הם עוגני תכנון להמחשה, לא המלצות גורפות שמתאימות לכל מחקר. הם נגזרים מהנחות ספציפיות (גודל אפקט, כוח,
α), ושינוי בהנחות מזיז את המספר. שנית, גודל האפקט הצפוי חייב לבוא ממקור אמיתי, מהספרות, ממחקר חלוץ, או מהאפקט הקטן ביותר שבאמת היה מעניין אותך מבחינה תיאורטית, לא ממשאלת לב. שלישית, את לא מחשבת את זה ביד: כלי חינמי כמוG*Power(או חבילתpwrב-R) מחזיר את ה-N ברגע שמזינים לו את ההנחות שלך.
ההנחה ששולטת בכל החישוב: גודל האפקט
כאן הרגע שמבלבל את רוב הסטודנטיות, וגם הכי חשוב. מבין ארבעת הגדלים, שלושה כמעט קבועים: α הוא 0.05, הכוח הוא 0.80, וה-N הוא הנעלם. כל החישוב, ולמעשה כל המספר שתכתבי בהצעה, תלוי כמעט לגמרי בגודל אחד שאת לא יכולה למדוד מראש: האפקט הצפוי. ושינוי קטן בהנחה הזאת מזיז את ה-N בצורה אדירה.
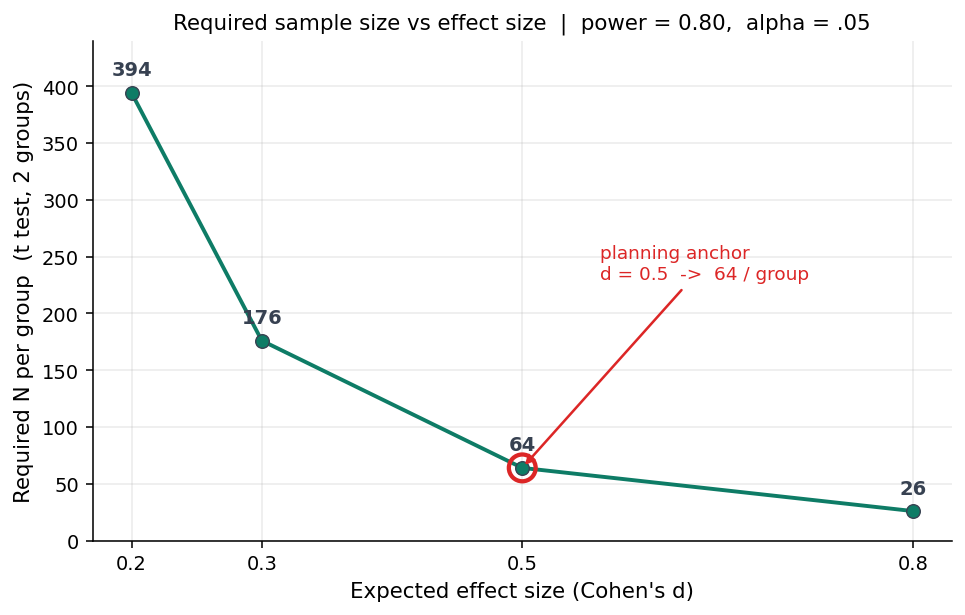
תסתכלי מה קורה לאותו מבחן t לשתי קבוצות בלתי-תלויות, כוח 0.80 ו-α = .05, כשמשנים רק את האפקט הצפוי:
| אפקט צפוי | N לכל קבוצה | N סה"כ |
|---|---|---|
d = 0.8 (גדול) | 26 | 52 |
d = 0.5 (בינוני) | 64 | 128 |
d = 0.3 | 176 | 352 |
d = 0.2 (קטן) | 394 | 788 |
תראי את הקפיצה בין d = 0.5 ל-d = 0.3. הנחת אפקט קצת יותר צנוע, מ-0.5 ל-0.3, וה-N כמעט שילש את עצמו, מ-128 ל-352. וזה רלוונטי אלייך באופן מעשי: בחינוך ובמדעי ההתנהגות, אפקטים אמיתיים של התערבויות נוטים לשבת סביב d = 0.2 עד 0.4, לא 0.5. אם תכננת ל-0.5 רק כי "בינוני נשמע סביר", ייתכן מאוד שבנית מחקר עם פחות כוח ממה שחשבת.
ולכן ההנחה הזאת צריכה מקור, לא ניחוש. אם יש לך מחקר חלוץ קטן שהראה d = 0.48, שימי לב שזאת הערכה רועשת: רווח הסמך 95% סביבה עשוי להיות רחב, נניח [0.05, 0.91]. כלומר האפקט האמיתי תואם גם לכמעט-אפס וגם לגדול. במצב כזה, תכנון על קצה הרווח האופטימי הוא הימור. הזהירות אומרת לתכנן על אפקט שמרני יותר מהאומדן הנקודתי, או לפחות לדווח בהצעה שני תרחישים, מה ה-N הדרוש לאפקט אופטימי ומה לאפקט שמרני, ולתת לוועדה לראות שחשבת על זה.
G*Power: איך מריצים את זה בפועל
את לא צריכה לחשב את המספרים האלה ביד. הכלי הסטנדרטי, ובחינם, הוא G*Power. הוא עושה בדיוק את החישוב שתיארנו, ומקובל בוועדות. ההיגיון בעבודה איתו הוא תמיד אותו היגיון של ארבעת הגדלים:
- בוחרים את משפחת המבחן ואת המבחן הספציפי (למשל
t tests → Means: Difference between two independent means). - בוחרים את סוג הניתוח:
A priori: Compute required sample size. זה הניתוח שמחזיר N. - מזינים את שלושת הגדלים הידועים: גודל האפקט הצפוי,
α, והכוח הרצוי. (אם יש לך הבדל ממוצעים וסטיות תקן מהספרות במקוםdמוכן, יש מחשבון פנימי שממיר אותם.) - לוחצים
Calculate, ומקבלים את ה-N הדרוש, כולל פירוק לכל קבוצה.
שימי לב לשדה "סוג הניתוח". A priori מחזיר N וזה מה שאת רוצה בשלב התכנון. יש שם גם Post hoc, שמחזיר כוח מתוך N נתון, וזה כלי אחר למצב אחר (ועל הבעייתיות של כוח בדיעבד על האפקט שנצפה, ראי את המאמר על כוח). אל תתבלבלי בין השניים בתפריט.
ולמה "כלל אצבע" לבד לא מספיק
בטח שמעת כללי אצבע: "10 נבדקים לכל מנבא ברגרסיה", "לפחות 30 בכל קבוצה", או הנוסחה של Green לרגרסיה, N ≥ 50 + 8k לבדיקת R² כולל. הכללים האלה לא חסרי ערך. הם נותנים בדיקת שפיות מהירה, ולפעמים זה כל מה שצריך כדי לפסול תכנון לא ריאלי.
הבעיה היא שהם מתעלמים משני הגדלים החשובים ביותר: גודל האפקט הצפוי והכוח שאת מכוונת אליו. "10 לכל מנבא" נותן אותו N בין אם את מחפשת אפקט גדול שקל לזהות לבין אפקט קטן שחומק. ראית בטבלה למעלה שההבדל הזה הוא בין 52 ל-788 נבדקות. כלל אצבע לא יודע להבחין ביניהם, כי הוא בכלל לא שואל על האפקט.
בפועל: כלל אצבע טוב ל"רגע, המספר הזה בכלל בטווח ההיגיון?". ניתוח כוח טוב ל"זה המספר, ואלה ההנחות שמאחוריו". בהצעת מחקר שמנחה או ועדה קוראים, השני הוא שמחזיק. כשמבקשים ממך לנמק את ה-N, "10 לכל מנבא" הוא לא נימוק שמחזיק מים מול שאלה ישירה.
כבר אספת נתונים? זה עדיין בשבילך
אם הגעת למאמר הזה אחרי שכבר אספת, זה לא מבוזבז, גם אם הוא נכתב לשלב שלפני. ההיגיון של ארבעת הגדלים הוא בדיוק מה שיעזור לך לתאר את הרגישות של המחקר שכבר רץ: מה היה גודל האפקט המינימלי שהיה לו סיכוי סביר להיתפס ב-N שלך. זאת אמירה לגיטימית ושימושית לפרק המגבלות, והיא שונה מ"כוח בדיעבד" שמחושב על האפקט שנצפה בפועל.
על איך לכתוב את זה נכון על מחקר שכבר הסתיים, כולל את ההבחנה העדינה הזאת ואת הניסוחים לפרק הדיון, יש מאמרים נפרדים: "המחקר שלך underpowered, מה זה אומר" ו"התוצאה לא יצאה מובהקת". שם המסגרת היא בדיעבד. כאן היא מראש.
מה לקחת מפה לעבודה שלך
- תכנון גודל מדגם הוא חישוב, לא ניחוש. ארבעה גדלים,
α, כוח, גודל אפקט ו-N, קשורים מתמטית. קבעי שלושה והרביעי נגזר. בשלב התכנון את פותרת ל-N. - קבעי α = 0.05 וכוח = 0.80 כברירת מחדל, אלא אם יש סיבה ספציפית לסטות. אלה הערכים שוועדה מצפה להם.
- גודל האפקט הוא ההנחה ששולטת בכל החישוב. מצאי לו מקור: ספרות או מחקר חלוץ, לא תחושת בטן. ובחינוך, אל תניחי 0.5 כברירת מחדל, אפקטים אמיתיים נוטים להיות קטנים יותר.
- הריצי a-priori ב-G*Power, בחרי את המבחן הנכון ואת המצב
A priori: Compute required sample size, ושמרי צילום מסך לנספח. - השתמשי בכלל אצבע רק כבדיקת שפיות, לא כנימוק סופי. בהצעה כתבי את החישוב המלא: המבחן, גודל האפקט, המקור שלו,
α, הכוח, וה-N שיצא. - אם כבר אספת, הפכי את אותו היגיון לניתוח רגישות: מה האפקט המינימלי שלמחקר שלך היה כוח סביר לזהות, ודווחי עליו במגבלות.
המשפט הקטן שהמנחה ביקש, "כמה נבדקות ולמה דווקא כך", הוא לא מלכודת. הוא הזמנה לכתוב מספר אחד שאת באמת יכולה להגן עליו. וכשאת עושה את החישוב לפני האיסוף, את עוד יכולה לשנות את התשובה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.