תצפית אחת קופצת בקצה הנתונים: למחוק, לתקן, או להשאיר אותה?

סיימת לאסוף נתונים. 90 משתתפים בניסוי על זיכרון עבודה, כל אחד עשה מטלת זמן תגובה (במילישניות) ומילא מבחן זיכרון עבודה. הכנסת הכל ל-SPSS, ביקשת Descriptives כדי "להכיר את הנתונים" לפני הניתוח, והעין נתפסת על שתי שורות: הגיל המקסימלי במדגם יצא 220, וזמן התגובה הארוך ביותר יצא 920 מילישניות בזמן שכמעט כולם בין 400 ל-700.
הגיל 220 ברור: מישהו הקליד 22 ונשאר עם האצבע על המקש. אבל ה-920 מבלבל הרבה יותר. הוא רחוק מהשאר, אבל הוא אפשרי. אולי יש לך באמת משתתפת אחת איטית. ועכשיו את לא יודעת אם למחוק את השורה הזאת, לתקן אותה, או להשאיר אותה ולקוות שהמנחה לא ישאל. נלך דרך זה לאט, כי לכל אחת מהאפשרויות יש מחיר, וההחלטה הזאת נכנסת לפרק השיטה.
חריג זה לא דבר אחד, זה שלוש שאלות נפרדות
המילה "חריג" מערבבת שלוש שאלות שונות, וכל הבלבול מתחיל מזה שלא מפרידים ביניהן.
השאלה הראשונה היא איתור: האם תצפית רחוקה מהשאר, ובאיזה כלי בכלל מודדים "רחוק". השאלה השנייה היא אבחנה: אם היא רחוקה, האם זאת טעות (הקלדה, יחידת מדידה, ערך חסר שנקרא כמספר) או מקרה קיצוני אמיתי שבאמת קיים באוכלוסייה. השאלה השלישית היא טיפול: מה עושים עם זה בפועל, ואיך מדווחים על ההחלטה בכנות.
זה המאמר על שלב ניקוי הנתונים, לפני שהרצת מבחן. החריגות שמשפיעות בתוך מודל רגרסיה, אלה שמזיזות את קו הרגרסיה דרך leverage ו-Cook's distance, הן סיפור נפרד שמתואר במאמר על נקודות משפיעות ברגרסיה. כאן אנחנו צעד אחד אחורה: התצפית חריגה ביחס לנתונים עצמם, עוד לפני שיש מודל.
הערה לפני הדוגמאות: המספרים פה נוצרו במחשב כדי שהמהלך יהיה נקי. נתונים אמיתיים תמיד מבולגנים יותר, וזה בדיוק העניין.
איתור חד-משתני: כלל ה-boxplot
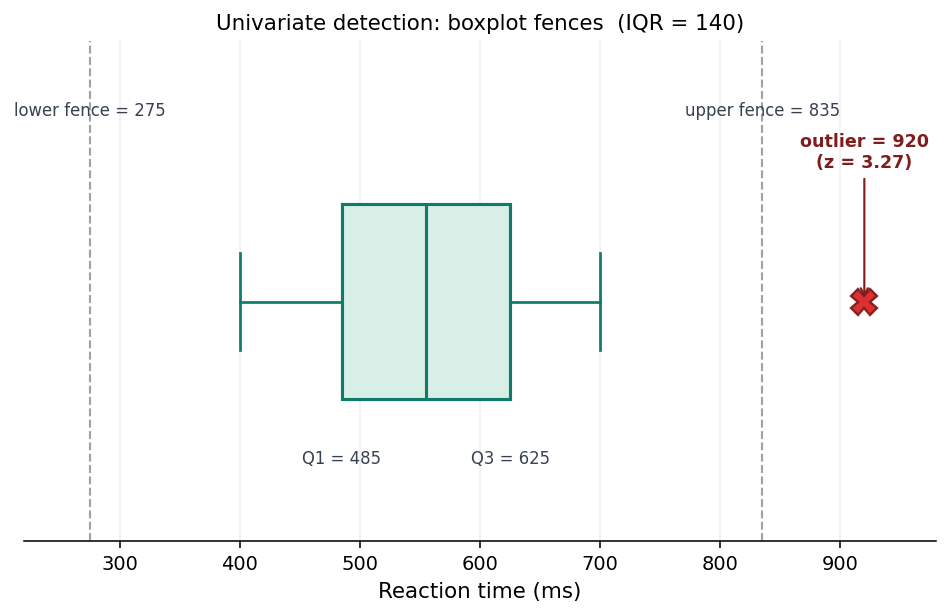
הדרך הראשונה והנפוצה ביותר לאתר חריג במשתנה בודד היא כלל הגדרות (Tukey's fences), זה שמצויר מאחורי כל תרשים קופסה (boxplot). הוא לא נשען על ממוצע, אלא על הרבעונים, ולכן הוא יציב יחסית.
קחי את זמן התגובה. הרבעון התחתון (Q1) הוא הערך שמתחתיו 25% מהמדגם, והעליון (Q3) הוא זה שמתחתיו 75%. אצלנו Q1 = 485 ו-Q3 = 625. המרחק ביניהם הוא הטווח הבין-רבעוני: IQR = 625 − 485 = 140. עכשיו מותחים גדר במרחק של 1.5 פעמים ה-IQR מעל ומתחת לקופסה:
- גדר עליונה:
625 + 1.5 × 140 = 835 - גדר תחתונה:
485 − 1.5 × 140 = 275
כל ערך מעל 835 או מתחת ל-275 מסומן כחריג. זמן התגובה 920 נופל מעל הגדר העליונה, אז הוא מסומן. שימי לב מאיפה בא המספר 1.5: זה לא חוק טבע, זה כלל אצבע שטיוקי הציע כי בהתפלגות נורמלית הוא מסמן רק כאחוז אחד מהתצפיות. יש מי שמשתמש ב-3.0 כדי לסמן רק חריגים קיצוניים. הסף הוא בחירה, לא אמת.
איתור חד-משתני: ציון התקן
הדרך השנייה היא דרך ציון התקן. לוקחים תצפית, מחשבים כמה סטיות תקן היא מהממוצע, ומסמנים אותה אם היא רחוקה מדי. עבור זמן התגובה, עם M = 560 ו-SD = 110, התצפית 920 נותנת:
z = (920 − 560) / 110 = 3.27
הסף הנפוץ הוא |z| > 3.29 (שמתאים ל-p < .001 דו-צדדי, הכלל ש-Tabachnick ו-Fidell ממליצות עליו), ויש מי שמסתפק ב-|z| > 3. לפי 3 התצפית מסומנת, לפי 3.29 היא ממש על הגבול. שוב, אותה תצפית, שני סִפים, שתי תשובות.
זהירות אחת חשובה לגבי ציון התקן: הממוצע וסטיית התקן עצמם מושפעים מהחריגים שאת מחפשת. אם בטעות נשאר במשתנה ערך בלתי אפשרי כמו 18500 מילישניות, סטיית התקן מתנפחת, וכל ה-z-ים מתכווצים, עד שחריג אמיתי ומתון יותר "מתחבא" מתחת לסף. התופעה הזאת נקראת מיסוך (masking). לכן כדאי קודם לתקן ערכים בלתי אפשריים ברורים, ורק אז לחשב z. מי שרוצה כלי עמיד יותר משתמש בחציון ובחציון הסטיות המוחלטות (MAD) במקום בממוצע ובסטיית התקן הרגילה.
איתור רב-משתני: מרחק מהלנוביס, והנקודה שאף boxplot לא יתפוס
וכאן מגיע החלק שמפתיע הכי הרבה אנשים. תצפית יכולה להיות תקינה לחלוטין בכל משתנה בנפרד, ועדיין להיות חריגה קשה בצירוף שלהם.
נניח שזמן התגובה וציון זיכרון העבודה קשורים שלילית במדגם שלך, r = −.42: מי שמגיב מהר נוטה לציון זיכרון גבוה. עכשיו תכירי משתתפת אחת עם זמן תגובה 770 מילישניות (איטית יחסית) וציון זיכרון עבודה 135 (גבוה מאוד). נבדוק כל משתנה לחוד:
| משתנה | הערך שלה | ציון תקן | מסומנת חד-משתנית? |
|---|---|---|---|
| זמן תגובה | 770 | z = 1.91 | לא, מתחת ל-3 |
| זיכרון עבודה | 135 | z = 2.33 | לא, מתחת ל-3 |
שני ה-boxplot-ים שלך, אחד לכל משתנה, נותנים לה לעבור בשקט. היא בתוך הגדרות בשני המקרים. ובכל זאת היא חריגה, כי השילוב שלה סותר את התבנית: היא איטית וגם בעלת זיכרון גבוה, בדיוק ההפך מהקשר השלילי שכל השאר מצייתים לו.
זה מה שמרחק מהלנוביס (Mahalanobis distance) נועד לתפוס. במקום למדוד מרחק מהממוצע בכל ציר בנפרד, הוא מודד מרחק ממרכז הענן הרב-ממדי תוך התחשבות בקשר בין המשתנים. לשני משתנים עם מתאם r, המרחק בריבוע של תצפית עם ציוני תקן z_x ו-z_y הוא:
D² = (z_x² − 2·r·z_x·z_y + z_y²) / (1 − r²)
נציב את המספרים שלה. שימי לב ל-r שנכנס לנוסחה: לוקחים את המתאם של המדגם כמו שהוא, כולל המשתתפת הזאת, כלומר אותו −.42 שכבר חישבנו. לא מורידים אותה לפני החישוב, וזה בדיוק מה שעושה את המבחן הוגן (כך מחושב מרחק מהלנוביס הקלאסי):
D² = (1.91² − 2·(−.42)·1.91·2.33 + 2.33²) / (1 − .42²)
D² = (3.65 + 3.74 + 5.43) / 0.8236 = 12.82 / 0.8236 ≈ 15.6
מאיפה יודעים אם 15.6 גדול? משווים אותו להתפלגות חי-בריבוע עם דרגות חופש כמספר המשתנים, כאן 2. הסף המקובל ל-p = .001 הוא χ²(2) = 13.82. המרחק שלה, 15.6, גדול ממנו. היא מסומנת כחריגה רב-משתנית, למרות ששני ה-boxplot-ים בירכו אותה לשלום. זה ההבדל שכדאי לקחת: בדיקה חד-משתנית בודקת כל עמודה לבד, ומרחק מהלנוביס בודק את הצירוף. למחקר עם כמה משתנים תלויים או מנבאים, את צריכה את שניהם.
(לשם הסדר: כשמרחק מהלנוביס מחושב על המנבאים בתוך מודל רגרסיה, הוא קשור ישירות ל-leverage. הגרסה התלויה במודל הזאת מתוארת במאמר על נקודות משפיעות, ולא נחזור עליה כאן.)
הצומת האמיתי: טעות מול מקרה קיצוני אמיתי
סימנת תצפית. עכשיו השאלה היחידה שבאמת קובעת מה לעשות איתה היא לא סטטיסטית, היא בלשית: מאיפה הערך הזה הגיע.
חזרי לשתי השורות מההתחלה. הגיל 220 הוא ערך בלתי אפשרי. אין בן אדם בגיל 220. זאת לא תצפית קיצונית, זאת טעות: הקלדה, יחידת מדידה שגויה, או קוד של ערך חסר (כמו 999) שנקרא בטעות כמספר אמיתי. כשערך בלתי אפשרי, את חוזרת לשאלון המקורי, מתקנת אם אפשר, ואם אי אפשר, ממירה לערך חסר. זאת לא "מחיקת חריג", זאת תיקון שגיאה, והיא לגיטימית לחלוטין.
זמן התגובה 920 הוא סיפור אחר. הוא רחוק, אבל הוא אפשרי. יכול להיות שבאמת ישבה מולך משתתפת איטית, או עייפה, או שהתפזרה לרגע. כאן אין תשובה אוטומטית. ערך אפשרי שמסומן כחריג הוא מקרה קיצוני אמיתי עד שיוכח אחרת, והוא חלק מהאוכלוסייה שלך. מחיקה שלו רק כי הוא "מפריע" היא הטיה של המדגם לכיוון הנוח לך.
| הערך | אפשרי פיזית? | מה זה כנראה | פעולה |
|---|---|---|---|
גיל 220 | לא | טעות הקלדה/קידוד | לתקן מהמקור או להמיר לחסר |
זמן תגובה 920 | כן | מקרה קיצוני אמיתי | להחליט במודע (ראי האפשרויות למטה) |
הכלל המנחה: טעות מתקנים או מסירים בלי היסוס. מקרה קיצוני אמיתי דורש שיקול דעת מוצהר, לא מחיקה שקטה.
ארבע האפשרויות, וכמה כל אחת עולה
הנחנו שזמן התגובה 920 הוא אמיתי. יש לך ארבע דרכים לטפל בו, מהשמרנית לדרסטית.
1. להשאיר כמו שהוא. אם המבחן שלך עמיד יחסית, או אם החריג משקף תופעה אמיתית שמעניינת אותך, הדבר הכן ביותר הוא פשוט להשאיר. המחיר: תצפית אחת קיצונית יכולה למשוך ממוצע או להחליש מתאם.
2. ווינזוריזציה (winsorizing). במקום למחוק, את "גוזמת" את הערך הקיצוני אל הערך הלא-חריג הקרוב ביותר, למשל אל האחוזון ה-95 או אל הגדר העליונה 835. כך התצפית נשארת במדגם (לא מאבדים n), אבל מאבדת את הקיצוניות שלה. המחיר: שינית ערך נתון אמיתי, וזה חייב להיות מדווח.
3. טרנספורמציה. אם כל המשתנה מוטה ימינה עם זנב ארוך (כמו זמני תגובה, שכמעט תמיד מוטים), טרנספורמציה לוגריתמית דוחסת את הזנב, והערך הקיצוני נעשה פחות קיצוני באופן יחסי, יחד עם כל השאר. היתרון: לא נוגעים בתצפית בודדת, מטפלים בצורת ההתפלגות כולה. המחיר: הפרשנות עוברת ליחידות לוג, ופחות אינטואיטיבית לקורא.
4. מחיקה. השמורה לטעויות מאומתות, או למקרים שבהם יש נימוק מהותי ברור (למשל משתתפת שלא הבינה את ההוראות). מחיקת מקרה קיצוני אמיתי רק כי הוא חריג היא הבחירה הבעייתית ביותר, כי היא משנה את המדגם שעליו את מסיקה.
כדי לראות למה זה לא טכני בלבד, הנה ההשפעה בפועל של אותה תצפית רב-משתנית (האיטית עם הזיכרון הגבוה) על המתאם בין זמן תגובה לזיכרון עבודה:
| מדגם | מתאם פירסון | רווח סמך 95% |
|---|---|---|
כל 90 המשתתפים | r = −.42 | [−.58, −.23] |
| בלי התצפית החריגה | r = −.55 | [−.68, −.39] |
תצפית בודדת אחת שסותרת את התבנית החלישה את עוצמת הקשר מ-−.55 ל-−.42, והרחיבה את רווח הסמך. שימי לב לניסוח: הקשר הזה הוא שיוך, לא סיבתיות. זמן תגובה איטי לא "גורם" לזיכרון נמוך, השניים פשוט נעים יחד במדגם. וגם: העובדה שהמתאם "משתפר" בלי התצפית היא לא הצדקה למחוק אותה. שיפור ההתאמה אף פעם אינו סיבה להסרה. הסיבה היחידה הלגיטימית היא שיקול מהותי על התצפית עצמה.
![תרשים יער המשווה את מתאם פירסון בין זמן תגובה לזיכרון עבודה עם ובלי התצפית החריגה. עם כל 90 המשתתפים המתאם הוא r=-0.42 עם רווח סמך 95% של [-0.58, -0.23]; בלי התצפית החריגה המתאם מתחזק ל-r=-0.55 עם רווח סמך צר יותר [-0.68, -0.39]. תצפית סוטה אחת החלישה את הקשר והרחיבה את רווח הסמך.](/blog/outliers-detection-and-handling/correlation-sensitivity.png)
איך מדווחים על זה בלי לאבד אמון
החלק שסטודנטיות הכי נוטות לדלג עליו, והוועדה הכי שמה לב אליו, הוא הדיווח. כל החלטה על חריגים צריכה להופיע בכתב בפרק השיטה, לפני התוצאות. לא כי זה פורמלי, אלא כי בלי זה אי אפשר לדעת אם התוצאות שלך אמיתיות או "מסודרות".
דיווח כן כולל ארבעה דברים: באיזה כלי איתרת (boxplot, ציון תקן, מהלנוביס), כמה תצפיות סומנו, מה החלטת לגבי כל סוג, ולמה. הנה דוגמה למשפט שאפשר להעתיק לתבנית:
"הנתונים נבדקו לאיתור תצפיות חריגות. ערך גיל בלתי אפשרי אחד(220)זוהה כשגיאת קידוד ותוקן מהשאלון המקורי. במשתנה זמן התגובה זוהתה תצפית חד-משתנית אחת מעל הגדר העליונה(920מ"ש), ובבדיקת מרחק מהלנוביס זוהתה תצפית רב-משתנית אחת(D² = 15.6, p < .001). שתיהן נמצאו ערכים אפשריים, ולכן נשמרו בניתוח. הניתוח הראשי הורץ פעמיים, עם התצפיות ובלעדיהן, והמסקנות לא השתנו."
השורה האחרונה היא הכי חזקה. ניתוח רגישות, כלומר להריץ פעם עם החריגים ופעם בלי ולדווח את שתי התוצאות, פותר את רוב הוויכוח. אם המסקנה זהה, הוכחת שהיא לא תלויה בקומץ נקודות. אם היא משתנה, גילית את זה בעצמך לפני שמישהו אחר גילה.
מה לקחת מפה לעבודה שלך
- הפרידי בין שלוש השאלות: איתור (רחוק?), אבחנה (טעות או אמיתי?), טיפול (מה עושים?). רוב הבלבול נולד מערבוב שלהן.
- אתרי בשתי רמות. boxplot או ציון תקן לכל משתנה בנפרד, ומרחק מהלנוביס לצירוף. נקודה תמימה בכל עמודה יכולה להיות חריגה קשה בשילוב, וזה נראה רק רב-משתנית.
- שאלי קודם "האם הערך אפשרי". בלתי אפשרי הוא טעות, מתקנים או מסירים בלי היסוס. אפשרי הוא מקרה קיצוני אמיתי, ודורש החלטה מודעת.
- אל תמחקי מקרה אמיתי רק כי הוא מפריע. שקלי קודם להשאיר, לווינזר, או לטרנספרם. מחיקה שמורה לטעויות מאומתות ולנימוק מהותי.
- הריצי ניתוח רגישות. פעם עם, פעם בלי, ודווחי את שתי התוצאות. זה ההבדל בין החלטה שקופה לבין נתון שנעלם בשקט.
- כתבי הכל בפרק השיטה. כלי, כמות, החלטה, נימוק. השקיפות הזאת היא מה שהופך את ניקוי הנתונים מ"לסדר את התוצאה" ל"להכיר את המדגם".
- זכרי שזה שלב אחד לפני המודל. את החריגות שמשפיעות בתוך רגרסיה ספציפית בודקים אחרת, עם leverage ו-Cook's distance, וזה מתואר במאמר הנפרד.
ניקוי חריגים הוא לא שלב טכני שעוברים בריצה לפני הניתוח האמיתי. ההחלטות פה קובעות אילו אנשים נשארים במדגם שעליו את מסיקה, וכל אחת מהן צריכה להיות כתובה, מנומקת, וניתנת לבדיקה חוזרת. זה לא קוסמטיקה. זאת ההגינות של התוצאה.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.