נקודה אחת וזזה לי הרגרסיה: leverage, Cook's D, ומה לעשות

הרצת רגרסיה. הסתכלת בפיזור. יש שם נקודה אחת בקצה, רחוקה מהענן הכללי. הרצת שוב בלעדיה. ה-β זז משמעותית. עכשיו את לא בטוחה מה לעשות איתה.
הראית למנחה. הוא אמר: "תבדקי את Cook's distance. ותסתכלי גם על leverage."
שני מושגים שאף אחד לא לימד אותך. אבל מאחוריהם יש שאלה אחת ברורה: האם תצפית אחת מזיזה את כל הרגרסיה. זה ההבדל בין נקודה חריגה (קל לזהות) ובין נקודה חריגה שמשפיעה על המודל (חשוב יותר).
שלוש שאלות, שלוש מדידות
כל תצפית במדגם שלך נושאת שלושה מספרים שצריך להבדיל ביניהם.
Leverage (מינוף): כמה רחוק ה-X של התצפית מהמרכז של ה-X-ים. נקודה עם X קיצוני, גבוה במיוחד או נמוך במיוחד, היא בעלת leverage גבוה. זה לא מסתכל בכלל על Y. רק על המיקום של התצפית על ציר ה-X. הצורה של leverage גבוה הופיעה כבר במאמר על פירסון לעומת ספירמן, באותו הקשר אבל במתאם. סימול: h_ii. הוא נע בין 0 ל-1, וסכומו על פני כל המדגם הוא k (מספר הפרמטרים, כולל החיתוך).
שארית מתוקננת (studentized residual): כמה רחוק ה-Y הנצפה של התצפית מה-Y שהמודל מנבא לה. השארית הגולמית היא המרחק האנכי בין הנצפה למנובא. הגרסה המתוקננת מחלקת את המרחק הזה בסטיית התקן של השארית, ולוקחת בחשבון גם את ה-leverage של אותה תצפית (דרך sqrt(1 − h_ii) במכנה). כלומר X משפיע על השארית המתוקננת בעקיפין, דרך התקנון. ערך מעל 3 בערך מוחלט הוא חריג ברוב המודלים. במאמר הזה מוצגים ערכים של השארית המתוקננת הפנימית (internal studentized residual).
Cook's distance: שילוב של השניים. כמה הקו הנאמד יזוז אם נסיר את התצפית מהמדגם. הנוסחה משלבת את ה-leverage ואת השארית: D_i = (r_i² / k) · (h_ii / (1 − h_ii)). ההשפעה החזקה ביותר נוצרת בדרך כלל כשגם ה-leverage גבוה וגם השארית גדולה. אבל גם רכיב אחד קיצוני יכול להספיק להשפעה לא-זניחה, אז אסור לפסול תצפית רק בגלל ש"רק אחד מהמדדים גבוה".
למה זה חשוב? כי הרבה סטודנטיות רצות להוריד תצפית רק כי היא "נראית חריגה". אבל בלי אבחנה מסודרת, "חריגה" יכולה להיות כל דבר, מתצפית בקצה ציר ה-X שלא משפיעה בכלל, ועד תצפית במרכז שמושכת את הקו דרמטית. שלושת המדדים מאפשרים לדעת איזה סוג של חריגה יש לך.
הדוגמה: 50 מורות, רגרסיה אחת, שלוש נקודות מעניינות
נתונים מ-50 מורות בתכנית M.Ed. כל אחת דיווחה על שעות הוראה שבועיות (X) ועל שביעות רצון מהעבודה בסולם 1 עד 100 (Y). המודל: satisfaction ~ hours. במדגם יש שלוש נקודות שמודגשות, ושאר 47 הן נקודות "רגילות".
| נקודה | X (שעות) | Y (שביעות רצון) | הסיפור החזותי |
|---|---|---|---|
| A | 27.0 | 20.0 | X באמצע הטווח, Y רחוק מתחת לקו |
| B | 42.0 | 27.0 | X בקצה הימני, Y בערך על הקו |
| C | 45.0 | 75.0 | X בקצה הימני, Y רחוק מעל הקו |
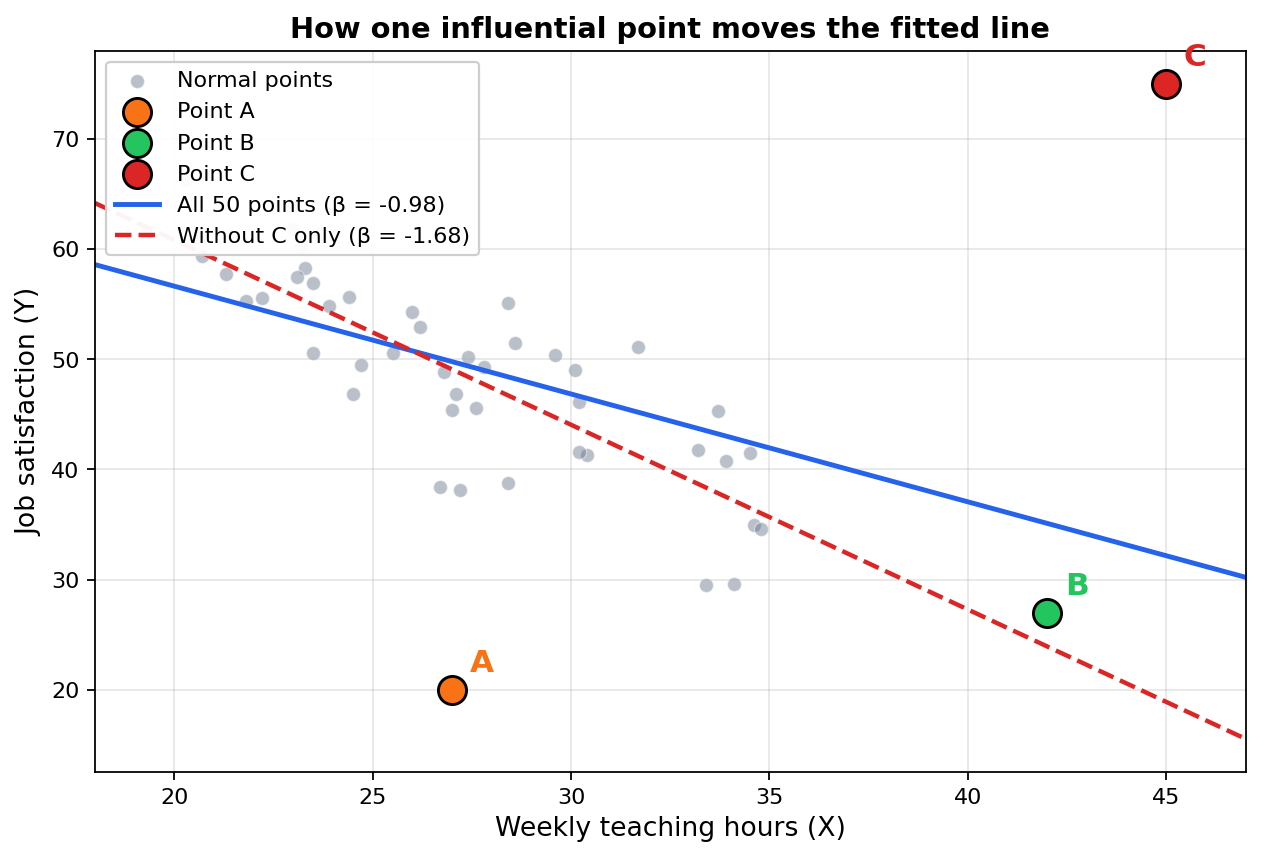
הרגרסיה על כל 50 הנקודות:
β = -0.978, SE = 0.257, t(48) = -3.81, p < .001, R² = 0.232
על פניו, הקשר מובהק. כל שעת הוראה נוספת מנבאת ירידה של כ-1 נקודה בשביעות הרצון. אבל ה-R² נמוך, רק 23%. עוד נחזור לזה.
אותן שלוש נקודות, שלושה פרופילים שונים
הרצת את הדיאגנוסטיקה. הנה מה שיצא לכל אחת מ-A, B, C, יחד עם הספים המקובלים.
| נקודה | Leverage (h) | שארית מתוקננת | Cook's D |
|---|---|---|---|
| A | 0.020 | -3.13 | 0.10 |
| B | 0.168 | -0.93 | 0.09 |
| C | 0.236 | 5.10 | 4.03 |
| סף נפוץ | > 2k/n = 0.080 | > |3| | > 4/n = 0.080 (לבחינה), > 1 (חמור) |
שלוש נקודות חריגות באופן שונה לחלוטין.
נקודה A: ה-X שלה הוא 27, ממש באמצע הטווח. leverage נמוך מאוד (0.02). אבל ה-Y שלה הוא 20, שביעות רצון מאוד נמוכה ביחס למה שהמודל מנבא לה. השארית המתוקננת היא -3.13, מעבר לסף הנפוץ של 3 בערך מוחלט. נקודה כזאת היא residual outlier: רחוקה אנכית מהקו, אבל לא קיצונית בציר ה-X.
נקודה B: ה-X שלה הוא 42, רחוק מהמרכז של הנתונים, ולכן ה-leverage שלה (0.168) גבוה משמעותית מהסף 2k/n. ה-Y שלה (27) קרוב יחסית למה שהמודל המלא מנבא, השארית המתוקננת היא -0.93, קטנה. נקודה כזאת היא high-leverage observation: יש לה כוח פוטנציאלי להזיז את הקו, אבל היא לא מנצלת אותו במלואו כי היא תואמת את המגמה הכללית. נראה בהמשך שיש לה השפעה מתונה על β, אבל לא כמו ל-C.
נקודה C: ה-X שלה הוא 45, leverage גבוה (0.236). ה-Y שלה 75, רחוק מאוד מעל הקו. השארית המתוקננת היא 5.10. שני המרכיבים גדולים. Cook's D הוא 4.03, פי 50 מהסף הליברלי של 4/n, ומעל הסף החמור של D > 1. נקודה כזאת היא influential observation: לא רק חריגה, אלא משפיעה בפועל.
מפת האבחנה
אפשר לראות את שלושת הפרופילים בבירור גם בגרף. ציר X של ההמחשה הוא leverage. ציר Y הוא השארית המתוקננת. הקווים האדומים המקווקווים הם הספים.
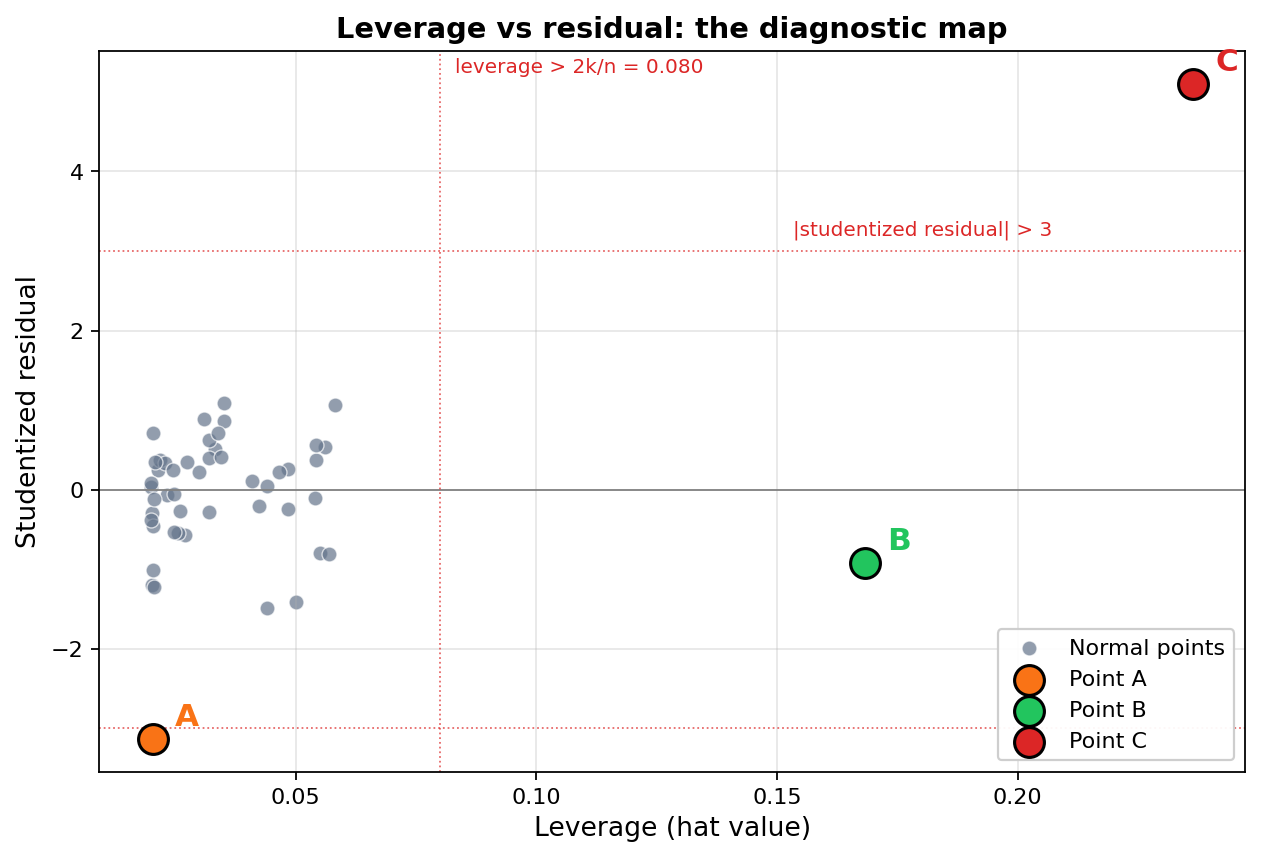
A משמאל לסף האנכי (leverage נמוך), מתחת לסף האופקי התחתון (שארית שלילית גדולה). B מימין לסף האנכי (leverage גבוה), אבל בתחום של שאריות קטנות. C נמצאת רחוק מימין ורחוק למעלה, גם וגם, יחידה לבדה.
מה קורה כשמסירים כל אחת מהן
Cook's D מסכם את השינוי הכולל בהתאמת המודל כשמסירים תצפית אחת. Δβ של מקדם בודד הוא בדיקה צרה יותר, רק על השיפוע שמעניין אותך. השניים קשורים אבל לא זהים, ולפעמים ערכי Cook's D דומים מתבטאים ב-Δβ שונים בסדרי גודל. הנה התוצאה בפועל לכל אחת מהשלוש.
| מודל | β (שעות) | R² | Δβ ביחס למודל המלא |
|---|---|---|---|
| כל 50 | -0.978 | 0.232 | — |
| בלי A | -0.991 | 0.280 | -0.013 |
| בלי B | -0.878 | 0.174 | +0.100 |
| בלי C | -1.676 | 0.602 | -0.698 |
| בלי A, B, ו-C | -1.728 | 0.691 | -0.750 |
הסרה של A הזיזה את β בשיעור זניח. הסרה של B הזיזה אותו פי 7 ממנה (0.10 לעומת 0.013), אבל עדיין מעט. הסרה של C הזיזה אותו פי 50 מ-A (0.70 לעומת 0.013), והכפילה את ה-R² פי שניים וחצי. C היא היחידה שמשפיעה דרמטית על ההערכה של β במודל הזה.
שתי תופעות שכדאי לקלוט מהטבלה הזאת.
ראשית: ל-A ול-B יש Cook's D דומה (0.10 לעומת 0.09), שתיהן מעל הסף הליברלי של 4/n. אבל ה-Δβ בפועל שונה בסדר גודל. ההבדל הזה לא סתירה. Cook's D מסכם את השינוי הכולל בהתאמת המודל; Δβ בודק את השיפוע בלבד. ערכי D דומים יכולים לבוא עם שינויי שיפוע שונים, וזה בדיוק מה שקורה כאן. הסף 4/n הוא ליברלי, נועד לסמן רשימת מועמדות לבדיקה, לא להכריז על השפעה חמורה. הסף החמור יותר הוא D > 1, ובו רק C נכנסת.
שנית: ה-R² במודל המלא הוא 0.232, ובלי C קופץ ל-0.602. שימוש זהיר ב-R² כאן: לא "ה-R² עלה כי הסרת התצפית 'שיפרה' את המודל". זאת מסקנה שגויה. R² מוצג כדי להמחיש את עוצמת ההשפעה של תצפית אחת על איכות ההתאמה, לא כקריטריון להחלטה אם להסיר אותה. האבחון נשען על leverage, שארית מתוקננת ו-Cook's D, ועל שיקול מהותי לגבי התצפית עצמה. R² הוא תוצאה משנית של ההחלטה, לא הצדקה לה. במדגמים גדולים יותר ההשפעה היחסית של תצפית בודדת קטנה, אלא אם ה-leverage שלה קיצוני יוצא דופן.
הספים בפועל
אין סף קסם אחד. אלה הספים המקובלים בספרות, כללי אצבע, לא ערכים שמחושבים מהנתונים שלך. כל אחד נועד לעניין שונה.
| מדידה | סף נפוץ | איך לקרוא אותו |
|---|---|---|
| Leverage (h) | > 2k/n או > 3k/n | X רחוק מהמרכז; מועמדת לבדיקה, לא בהכרח בעיה |
| שארית מתוקננת | > |3| (לפעמים |2|) | Y רחוק מהקו; מועמדת לבדיקה, לא בהכרח בעיה |
| Cook's D | > 4/n | סף ליברלי, מסמן רשימת מועמדות לבדיקה |
| Cook's D | > 0.5 | סף בינוני, ראויה לדיון בכתב |
| Cook's D | > 1 | סף חמור, השפעה ברורה על המודל |
k הוא מספר הפרמטרים, כולל החיתוך. ברגרסיה לינארית פשוטה הוא 2 (חיתוך + שיפוע). ברגרסיה מרובה הוא 1 + מספר המנבאים, וה-leverage שם מתאר את מיקום התצפית במרחב הרב-ממדי של המנבאים, לא רק את המרחק שלה ממרכז ציר X בודד. n הוא מספר התצפיות.
מה לעשות בפועל
תצפית שעוברת את הסף היא לא בהכרח טעות. היא מועמדת לבדיקה. שלוש האפשרויות שעומדות בפנייך.
אפשרות ראשונה: לוודא שאין טעות הקלדה. אם הנתונים הוקלדו ידנית, נקודה חריגה היא הזמן לחזור לטופס המקורי ולוודא. 70 כתוב כשבעצם 7. 45 כתוב כשבעצם 4.5. זה קורה. אם זו טעות, מתקנים, ומריצים מחדש בלי דיון נוסף.
אפשרות שנייה: להשאיר, ולדווח את שני המודלים. אם הנתון תקין מבחינת הקלדה אבל לא טיפוסי, הדרך הנקייה ביותר היא להריץ את המודל גם עם וגם בלי התצפית, ולדווח על שתי התוצאות. אם המסקנה לא משתנה, מצוין. אם היא משתנה, זה ממצא בפני עצמו שצריך לדון בו, לא להחביא.
אפשרות שלישית: להסיר, עם הצדקה כתובה. אם יש סיבה תיאורטית או מתודולוגית, אפשר להסיר. אבל ההסרה חייבת להיות מנומקת בכתב לפני שהיא מבוצעת, לא אחריה. "המורה הזאת היא היחידה במדגם שעובדת במשרה חלקית" היא הצדקה. "המורה הזאת לא התאימה למודל" היא לא הצדקה אלא בחירה רטרואקטיבית, וועדה תזהה אותה.
הסרה שתיתפס בוועדה כדגל אדום היא הסרה בלי הסבר, או הסרה רק כי "Cook's D היה גבוה". זה לא נימוק. זה נימוק לבדוק, לא להסיר.
איך לכתוב בפרק הממצאים
לפני האמידה הסופית של המודל, נבחנו תצפיות בעלות השפעה אפשרית באמצעות leverage, שאריות מתוקננות ו-Cook's distance. נמצאה תצפית אחת מובהקת בכל שלוש המדידות (
h = .24, studentized residual = 5.10, D = 4.03), חורגת מסף Cook's D > 1. בבדיקת רישומים מקוריים לא נמצאה טעות הקלדה, והערכים תקפים. בהתבסס על השיקול שהמורה הזאת מייצגת מקרה אמיתי באוכלוסיית המחקר ולא חריגה מתודולוגית שיש להחריג, המודל מדווח עם התצפית. במקביל, נאמד גם מודל ללא התצפית לשם השוואה, וכיוון ההשפעה נשמר (β = -.98, R² = .23במודל המלא;β = -1.68, R² = .60ללא התצפית). שני הניתוחים מדווחים, וההמשך מתבסס על המודל המלא תוך ציון השפעת התצפית על עוצמת ההערכה.
ארבעה משפטים. הדיאגנוסטיקה שעשית, התוצאה, הקריטריון שבחרת לפיו, ההשוואה. הקריטריון חשוב במיוחד. "בחרתי במודל המלא כי..." חייב לעמוד על נימוק מהותי (למה התצפית רלוונטית לאוכלוסייה) ולא רק על "כיוון β נשמר". את לא חייבת להסביר את Cook's D עצמו לוועדה (יש להניח שמכירים), אבל את כן חייבת להראות שבדקת, שיש לך החלטה, ושההחלטה מנומקת.
סייגים
שלוש הערות לפני שאת מריצה את זה על הנתונים שלך.
הדיאגנוסטיקה תלויה במודל. Cook's D של תצפית מסוימת ישתנה אם תוסיפי או תסירי מנבא מהמודל. תצפית שהייתה "בלתי משפיעה" עם מנבא אחד יכולה להפוך לבעלת השפעה כשמוסיפים מנבא שני שמחזק את ההגיון של המודל. בכל פעם שאת משנה את הרגרסיה, חוזרים על האבחון.
הספים הם קונבנציות, לא חוקי טבע. 2k/n ו-4/n ו-D > 1 הם כללי אצבע נפוצים. במאמרים שונים תמצאי גם 3k/n ל-leverage, או 2.5 כסף לשארית מתוקננת במקום 3. הם נועדו לכוון את העין, לא להחליף שיקול דעת. נקודה עם Cook's D של 0.95 לא פחות בעייתית מנקודה עם 1.05.
במדגמים קטנים, כמעט תמיד תהיה לפחות תצפית אחת מעל הסף 4/n. זה לא בהכרח אומר שיש לך בעיה. כדוגמה כללית (לא מתוך הנתונים פה), במדגם של 30 תצפיות הסף הוא 4/30 = 0.133, וברעש סטטיסטי טבעי סביר שתצפית אחת או שתיים יחצו אותו. הסף הזה נועד לסנן רשימה לבחינה, לא להכריז על כשל. השאלה האמיתית היא תמיד: כמה המקדמים זזים כשמסירים את התצפית, וכמה המודל משתנה מהותית.
בקיצור
שלוש מדידות נפרדות לנקודה ברגרסיה. leverage שואל "כמה X רחוק מהמרכז". שארית מתוקננת שואלת "כמה Y רחוק מהקו". Cook's D מחבר ושואל "כמה הקו זז אם נסיר את התצפית".
X קיצוני לבדו לא בהכרח בעיה. שארית גדולה לבדה גם לא בהכרח בעיה. ההשפעה החזקה ביותר על המודל נוצרת בדרך כלל בצירוף שלהם, וזה מה ש-Cook's D מסכם.
תצפית שעוברת סף היא מועמדת לבדיקה, לא מועמדת להסרה. הסרה דורשת הצדקה מתודולוגית בכתב, או דיווח של שני המודלים, או שניהם. הסרה שקטה היא דגל אדום בוועדה. תיעוד של החלטה מנומקת הוא להפך, סימן למתודולוגיה רצינית.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.