בדיקת הנחות הרגרסיה: חמש בדיקות, שתי בעיות חבויות

הרצת את הרגרסיה. הטבלה יצאה, יש R² סביר, וכבר כתבת חצי פסקה בפרק התוצאות. ואז הגיע המייל מהמנחה, שורה אחת: "בדקת את ההנחות?"
המילה "הנחות" נשמעת כמו עוד משוכה בירוקרטית. היא לא. מאחוריה מסתתרת שאלה אמיתית: האם המספרים שבטבלה אומרים מה שנדמה לך שהם אומרים. לפעמים מודל נראה תקין לגמרי על פני השטח, ושתי בעיות חבויות בתוכו משנות את כל הפרשנות.
הפוסט הזה לוקח דוגמה אחת ובודק עליה חמש בדיקות אבחון. שתיים מהן ייכשלו, וזה בכוונה. ככה רואים מה כל בדיקה תופסת, ומה עושים כשהיא נדלקת באדום.
הדוגמה: 60 מורות, שלושה מנבאים שנראים סבירים
נניח שאת מנבאת שביעות רצון מהעבודה (סולם 0 עד 100) משלושה משתנים: ותק בהוראה בשנים, גיל, ושעות הוראה שבועיות. כל אחד מהם נשמע רלוונטי, אם כי תיאורטית הוותק מעניין אותך יותר מהגיל, כי הוא קשור ישירות לניסיון המקצועי. לצורך הדוגמה נניח גם שהמדגם תוכנן כך שיש מורה אחת מכל בית ספר, כדי שהתצפיות יהיו בלתי תלויות (נחזור לזה בבדיקה האחרונה).
הרגרסיה המרובה מחזירה:
| מנבא | b (לא מתוקנן) | SE | t | p |
|---|---|---|---|---|
| ותק (שנים) | −0.34 | 0.84 | −0.41 | .684 |
| גיל | −0.17 | 0.84 | −0.20 | .842 |
| שעות שבועיות | 0.43 | 0.17 | 2.58 | .013 |
R² = 0.274, F(3, 56) = 7.05, p < .001. המודל כולו מובהק. שעות מנבאות שביעות רצון. אבל ותק וגיל שניהם לא מובהקים, p של 0.68 ו-0.84.
הנה הרגע שבו קל לטעות. את עלולה לכתוב: "לוותק ולגיל אין קשר לשביעות הרצון". זה מה שהטבלה כאילו אומרת. וזה שגוי. כדי להבין למה, צריך את הבדיקות.
בדיקה 1: מולטיקולינאריות
נתחיל דווקא מהבדיקה שפותרת את התעלומה של הטבלה למעלה. מולטיקולינאריות קורית כשמנבא אחד ניתן לחיזוי כמעט מלא מתוך מנבאים אחרים. במקרה כזה המודל לא יודע למי לזקוף את האפקט, וה-b של כל אחד מהם נעשה לא יציב, עם שגיאת תקן מנופחת.
וכאן זה בדיוק מה שקורה. גיל וותק כמעט אותו דבר במדגם הזה: מורה עם 20 שנות ותק היא בדרך כלל בשנות ה-40 או 50 לחייה. המתאם ביניהם הוא 0.99.
איך בודקים: מדד שנקרא VIF (Variance Inflation Factor), אחד לכל מנבא. כלל אצבע: VIF מעל 5 מחייב תשומת לב, מעל 10 הוא בעיה ממשית.
| מנבא | VIF במודל המלא |
|---|---|
| ותק | 37.2 |
| גיל | 37.3 |
| שעות שבועיות | 1.1 |
ותק וגיל מעל 37. הרבה מעבר לסף. שעות, שאינן מתואמות עם השניים, יושבות על 1.1, תקין לחלוטין.
מה עושים: כששני מנבאים מודדים כמעט את אותו דבר, צריך להחליט תיאורטית. אפשר להשאיר אחד מהם, לאחד את שניהם למדד אחד, או פשוט לדווח שאי אפשר להפריד ביניהם היטב. ההחלטה מהותית, לא רק סטטיסטית, ולא "נוריד את מי שלא יצא מובהק". כאן הגיל והוותק מספקים כמעט את אותו המידע, וכפי שאמרנו הוותק מעניין אותנו תיאורטית יותר, אז נשאיר אותו ונוריד את הגיל.
הנה המודל בלי גיל:
| מנבא | b | SE | t | p |
|---|---|---|---|---|
| ותק (שנים) | −0.51 | 0.14 | −3.74 | .0004 |
| שעות שבועיות | 0.42 | 0.16 | 2.67 | .010 |
תראי מה קרה לוותק. במודל המלא: b = −0.34, שגיאת תקן 0.84, p = .68. בלי הגיל: b = −0.51, שגיאת תקן 0.14, p = .0004. אותו משתנה, אותם נתונים. ההבדל היחיד הוא שהורדנו את הגיל המתואם. שגיאת התקן התכווצה פי שישה, וה-p עבר מ"חסר משמעות" ל"מובהק מאוד".
שימי לב למספר אחד שכמעט לא זז: ה-R². במודל המלא הוא 0.274, ובלי הגיל 0.273. מולטיקולינאריות פוגעת בדיוק של המקדמים, לא בכושר הניבוי הכולל של המודל. שני המודלים מנבאים שביעות רצון באותה מידה, אבל רק אחד מהם מאפשר לך לקרוא נכון את התרומה של הוותק.
זה הלקח המרכזי של מולטיקולינאריות. הגיל והוותק נושאים כמעט אותו מידע, ולכן המודל לא יכול להפריד את התרומה הייחודית של כל אחד מהם. הכללת שניהם ניפחה את שגיאת התקן והסתירה את האפקט. חשוב לדייק: VIF לא "מוכיח" איזה מנבא אמיתי, הוא רק מסמן ששניים מהם כמעט זהים. את מי להשאיר זו החלטה תיאורטית, ואצלנו הוותק הוא הקונסטרוקט המהותי לשאלת המחקר, בעוד הגיל הוא בעיקר מדד עקיף שלו.
מכאן נמשיך עם המודל הזה, ותק ושעות, ונבדוק עליו את שאר ההנחות.
בדיקה 2: לינאריות
הרגרסיה הלינארית מניחה שבהינתן שאר המנבאים, התרומה הממוצעת של כל מנבא ל-Y היא קו ישר. אם הקשר בפועל עקום (פרבולה, רוויה, מדרגה), קו ישר יחמיץ אותו.
איך בודקים: גרף שאריות מול ערכים מותאמים (residuals vs fitted), ומחפשים תבנית. פיזור חסר צורה מסביב לאפס הוא מה שרוצים. קימור, U או גל מסמנים בעיה. הגרף הזה הוא בדיקת סינון ראשונית; כדי לבחון מנבא בודד לעומק מסתכלים גם על שאריות מול אותו X לבדו. שימי לב: אותו גרף עונה על שתי שאלות נפרדות, האם יש קימור סביב האפס (לינאריות), והאם רוחב הפיזור קבוע (הבדיקה הבאה).
בגרף שלנו לא נראית תבנית של U או גל, אז כבדיקת סינון הלינאריות נראית סבירה.
מה עושים כשהבדיקה נכשלת: מוסיפים איבר ריבועי, מבצעים טרנספורמציה (log על Y או על המנבא), או עוברים למודל לא-לינארי. הבחירה תלויה בצורה שראית.
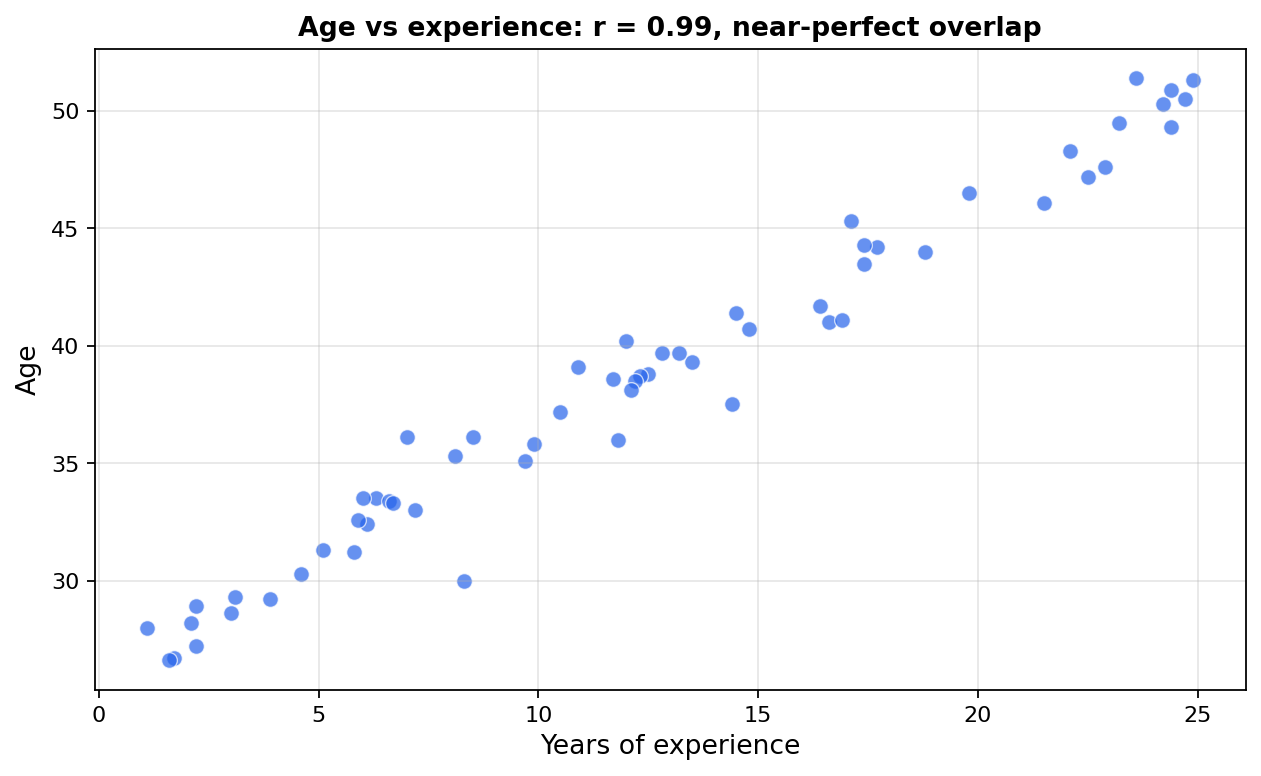
בדיקה 3: נורמליות של השאריות
ההנחה היא שהשגיאות של המודל מתפלגות בקירוב נורמלי. השאריות הן הקירוב האמפירי שלהן. שימי לב לדיוק: לא ה-Y צריך להיות נורמלי, ולא המנבאים. רק השאריות, מה שנשאר אחרי שהמודל הסביר את הקשרים.
עוד נקודה: אמידת ה-b עצמה לא דורשת נורמליות. ההנחה הזאת נוגעת למבחני t/F ולרווחי הסמך, כלומר ל-p-values ולהסקה.
איך בודקים: מבחן Shapiro-Wilk על השאריות, יחד עם Q-Q plot.
במקרה שלנו: W = 0.976, p = .28. אין סטייה חזקה מהנורמליות. הנקודות ב-Q-Q plot עוקבות אחרי הקו באופן סביר, עם סטייה קלה בקצה העליון. כבדיקה זה עובר, וכדאי להתרגל לתאר את הקצוות במדויק במקום לכתוב "צמוד לחלוטין".
מה עושים כשהבדיקה נכשלת: במדגם גדול יחסית הפרה קלה לרוב פחות מזיקה, אבל אין סף קסם אחד. אפשר טרנספורמציה של Y, או חישוב שגיאות תקן ב-bootstrap.
בדיקה 4: הומוסקדסטיות
שם מאיים, רעיון פשוט: שונות השאריות צריכה להיות קבועה לאורך כל טווח הערכים החזויים. אם הפיזור של השאריות גדל ככל שמתקדמים על הציר, ההנחה הופרה.
איך בודקים: שוב גרף השאריות מול הערכים המותאמים, והפעם מחפשים צורת משפך. מבחן Breusch-Pagan נותן גם p-value.
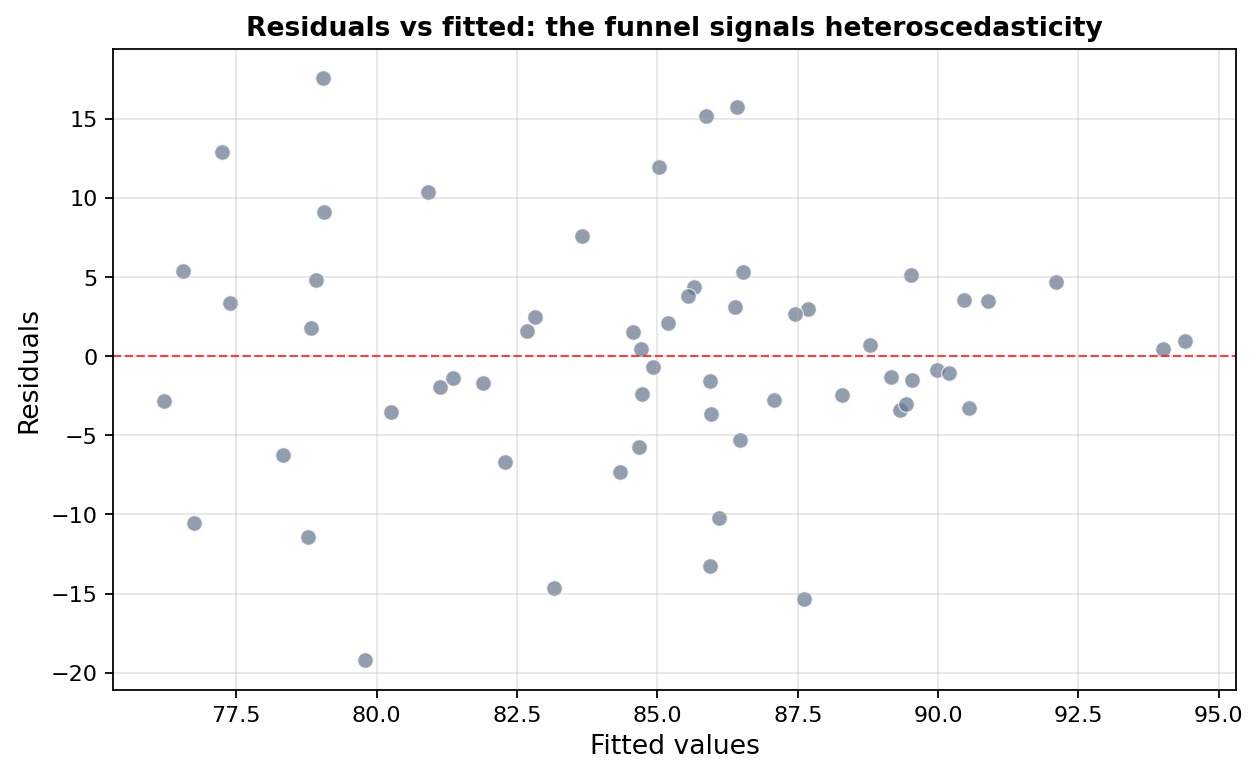
במקרה שלנו: Breusch-Pagan p = .025. יש עדות להטרוסקדסטיות. בגרף נראית צורת משפך, אבל מכיוון שהערכים המותאמים משלבים ותק ושעות, המשפך לא תמיד מושלם לעין. המספרים ברורים יותר: אם נחתוך את השאריות לפי רבעוני ותק, סטיית התקן ברבעון הוותיק היא 9.05, לעומת 3.33 ברבעון הצעיר. פי 2.72 (השונות גדולה פי 7.4).
אפשר לפרש את זה מהותית, למשל שאצל מורות ותיקות יש שונות גדולה יותר בשביעות הרצון, חלקן שחוקות וחלקן מרוצות מאוד, בעוד שבתחילת הדרך כולן דומות יותר. בדוגמה הסימולטיבית שלנו זה הוכנס בכוונה, דרך רעש שגדל עם הוותק.
מה זה אומר בפועל: ה-b-ים עצמם עדיין חסרי הטיה, אבל שגיאות התקן הקלאסיות לא מהימנות. הן יכולות לצאת קטנות מדי (ואז ה-p נראה קטן מדי, מובהקות חזקה מהאמת) או גדולות מדי (ואז מפספסים אפקט אמיתי). זה תקף גם למבחני המקדמים וגם ל-F הכולל. ה-R² לא מושפע, ההסקה כן.
מה עושים: קודם מוודאים ששום דבר אחר לא יוצר את המשפך, אינטראקציה חסרה או איבר עקום שלא הוכנס. אם המודל הממוצע נכון והמטרה היא הסקה על המקדמים, עוברים לשגיאות תקן עמידות להטרוסקדסטיות (HC3, או robust SE). זו לחיצה אחת ב-SPSS ופתרון מקובל לחלוטין בפרק התוצאות. שימי לב למה שהן עושות: הן מתקנות את ההסקה, לא את עצם העובדה שהפיזור משתנה.
| מנבא | SE קלאסי | SE עם HC3 | p קלאסי | p עם HC3 |
|---|---|---|---|---|
| ותק | 0.136 | 0.131 | .0004 | .0001 |
| שעות שבועיות | 0.158 | 0.156 | .010 | .007 |
כאן ה-HC3 מזיז את ההסקה רק מעט, ושני המנבאים נשארים מובהקים. זה לא תמיד המצב. בדוגמה גבולית, שבה p קלאסי יושב על 0.04, תיקון כזה יכול להפוך את התוצאה ללא מובהקת. הסיבה להשתמש ב-HC3 היא לא שהוא תמיד מחליש או תמיד מחזק, אלא שהוא נותן הסקה שאפשר לסמוך עליה כשההנחה הופרה.
בדיקה 5: עצמאות של השגיאות
השאריות צריכות להיות בלתי תלויות זו בזו. ההפרה הקלאסית: נתונים עם סדר טבעי שבו תצפית קרובה לקודמת, כמו מדידות חוזרות לאורך זמן, או תצפיות מקובצות (תלמידים מאותה כיתה, מורות מאותו בית ספר).
איך בודקים: סטטיסטיקת Durbin-Watson, בתנאי שלשורות בקובץ יש סדר משמעותי (זמן, רצף, מיקום). ערך סביב 2 תקין. מתחת ל-1.5 או מעל 2.5 מחייב עיון. אם לתצפיות אין סדר טבעי, DW פחות אומר משהו.
במקרה שלנו DW = 2.08, אבל יותר חשוב מהמספר: בנינו את הדוגמה כך שכל מורה היא מבית ספר אחר, כלומר העצמאות מובטחת מעצם תכנון המחקר. זאת בדיוק הנקודה. עצמאות נקבעת קודם כל באיך אספת את הנתונים, לא במבחן שמריצים בסוף.
מה עושים אם הבעיה אמיתית: אם יש קינון (כמה מורות מאותו בית ספר, או אותה מורה שנמדדה כמה פעמים), זו לא בעיה שמתקנים עם תוספת קטנה. צריך מודל אחר: שגיאות תקן מקובצות (clustered SE), מודל רב-רמתי, או ANOVA חוזרת כשהמדידות הן על אותם נבדקים.
הצ'ק-ליסט שאת לוקחת לפגישה
חמש בדיקות. בטבלה למטה גם סדר העדיפות, שהוא לא בהכרח הסדר שבו הצגתי אותן כאן.
| בדיקה | איך | סף / סימן |
|---|---|---|
| עצמאות | איך נאספו הנתונים, ו-Durbin-Watson אם יש סדר | DW סביב 2; אין קינון |
| מולטיקולינאריות | VIF לכל מנבא | VIF מתחת ל-5 |
| לינאריות | שאריות מול fitted (וגם מול כל X) | אין תבנית |
| הומוסקדסטיות | אותו גרף + Breusch-Pagan | אין משפך; BP לא מובהק |
| נורמליות השאריות | Shapiro-Wilk + Q-Q plot | נקודות על הקו |
סדר העדיפות מתחיל בעצמאות (שאלה של מבנה הדגימה), אחריה מולטיקולינאריות והשפעת תצפיות חריגות, ורק אז לינאריות, הומוסקדסטיות, ולבסוף נורמליות של השאריות, שעם N סביר היא בדרך כלל הפחות קריטית. לבדיקה השישית, השפעת תצפיות בודדות, הוקדש פוסט נפרד.
בדוגמה שלנו בשתי בדיקות נדלקה נורה אדומה. המולטיקולינאריות הסתירה אפקט אמיתי של ותק, עד שהורדנו את הגיל המתואם וההסקה התבהרה. ההומוסקדסטיות נכשלה, ולא ביטלנו אותה, אלא דיווחנו עם שגיאות תקן עמידות. בשני המקרים, המספר בטבלה המקורית לא היה מה שנדמה. זה כל ההבדל בין "הרצתי רגרסיה" לבין "בדקתי הנחות".
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.