מבחן Kruskal-Wallis: להשוות שלוש קבוצות או יותר לפי דירוגים, ואז לגלות איפה ההבדל

למדת לא מזמן את מבחן Mann-Whitney, והוא עבד יפה. שתי קבוצות, דירגת את כולן יחד, ובדקת איזו קבוצה נוטה לקבל דירוגים גבוהים יותר. אבל עכשיו אין לך שתי קבוצות. יש שלוש: כיתה שקיבלה משוב בכתב, כיתה שקיבלה משוב בעל-פה, וכיתה שקיבלה את שניהם. את רוצה לדעת אם באחת הקבוצות תחושת המסוגלות של התלמידים גבוהה יותר, על סולם של 1 עד 7.
המחשבה הראשונה היא להריץ את Mann-Whitney שלוש פעמים. כתב מול על-פה, כתב מול משולב, על-פה מול משולב. זה נשמע הגיוני. אבל יש שם מלכוד, ובדיוק כדי לעקוף אותו קיים מבחן Kruskal-Wallis.
למה לא להריץ Mann-Whitney שלוש פעמים
לכל מבחן יש סיכון קטן לטעות, להכריז על הבדל שהוא בעצם רעש. כשמריצים מבחן אחד, הסיכון הזה מבוקר. כשמריצים שלושה על אותם נתונים, הסיכונים הקטנים מצטברים, והסיכוי שלפחות אחד מהם יצביע בטעות על הבדל עולה.
זה בדיוק אותו שיקול שבגללו לא מריצים הרבה מבחני t אלא ANOVA חד-כיוונית: קודם שאלה אחת כוללת על כל הקבוצות יחד, ורק אם היא מובהקת ממשיכים לבדוק זוגות. Kruskal-Wallis הוא בדיוק זה, בגרסת הדירוגים. הוא ה-ANOVA החד-כיוונית של העולם הלא פרמטרי.
מה Kruskal-Wallis עושה: שוב, דירוג
המהלך מוכר לך מ-Mann-Whitney. תשכחי מהציונים הגולמיים לרגע. קחי את כל 24 התלמידים משלוש הקבוצות יחד, וסדרי אותם בשורה אחת מתחושת המסוגלות הנמוכה ביותר לגבוהה ביותר. תני לכל אחד דירוג, מ-1 עד 24. כשכמה תלמידים מקבלים בדיוק אותו ציון, הם מתחלקים בדירוג הממוצע של המקומות שתפסו.
עכשיו השאלה: האם קבוצה אחת נוטה להתמקם גבוה בשורה, ואחרת נמוך?
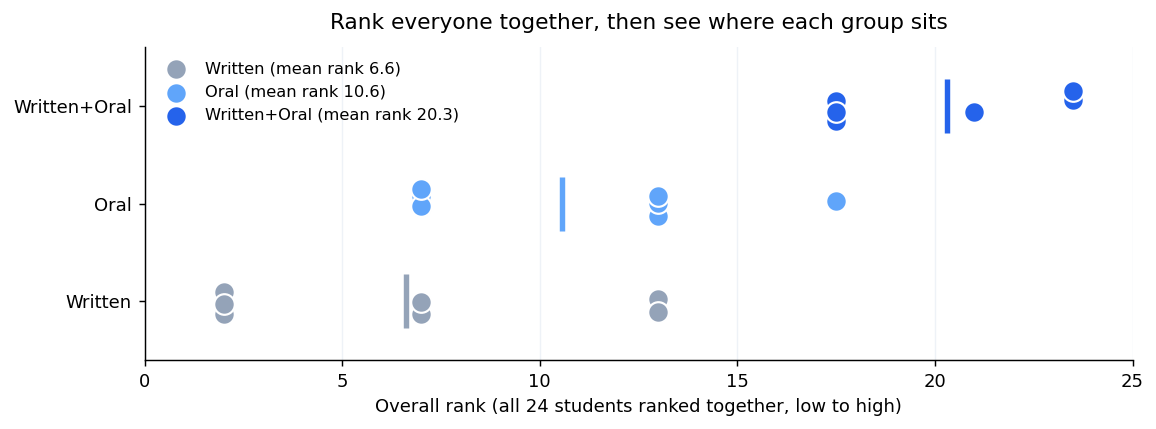
הדרך לכמת את זה היא הדירוג הממוצע של כל קבוצה. אצל המשוב בכתב הוא 6.6, אצל המשוב בעל-פה 10.6, ואצל המשוב המשולב 20.3. שלושת המספרים האלה הם לב המבחן. אם השיטות לא היו נבדלות זו מזו, היינו מצפים ששלושת הדירוגים הממוצעים יהיו קרובים זה לזה. בפועל, רחוקים מאוד.
מה המבחן מחזיר
מבחן Kruskal-Wallis מסכם את הפיזור של הדירוגים הממוצעים במספר אחד, H. ככל שהקבוצות רחוקות יותר זו מזו בדירוגים, H גדול יותר.
H(2) = 16.57, p < .001
ה-2 בסוגריים הוא דרגות החופש, מספר הקבוצות פחות אחת. ה-p אומר את הדבר הבא: אם התפלגות תחושת המסוגלות הייתה זהה בשלוש הקבוצות, פיזור כזה גדול של דירוגים ממוצעים היה קורה רק לעיתים נדירות מאוד, פחות מפעם באלף. לכן דוחים את ההנחה הזאת. יש הבדל כלשהו בין הקבוצות.
כמה גדול ההבדל
כמו תמיד, מובהק זה לא אותו דבר כמו גדול. ה-p הראה שהנתונים לא מסתדרים עם ההנחה שאין הבדל. גודל האפקט אומר כמה ההבדל מהותי.
המדד שמתאים כאן נקרא אפסילון בריבוע, והוא יוצא 0.72. אפשר לפרש אותו בקירוב כחלק מהשונות בדירוגים שקשור לשיוך הקבוצתי, וכאן החלק הזה גדול. לפי כללי האצבע זה אפקט גדול. במדגם הזה ההבדל בין השיטות הוא לא רק קיים, הוא מהותי.
המבחן אמר שמשהו שונה, לא מי
וכאן הנקודה שהכי קל לפספס. H מובהק אומר שלפחות אחת מהקבוצות נבדלת מהאחרות. הוא לא אומר אילו, וגם לא באיזה כיוון. בדיוק כמו ב-ANOVA, זאת שאלה כוללת, לא זוגית. אי אפשר להסיק מ-H לבדו שהמשוב המשולב עדיף על המשוב בכתב, או שכל שלוש השיטות נבדלות זו מזו. את יודעת רק שאי-שם בין השלוש יש הבדל.
כדי לגלות איפה בדיוק, ממשיכים לבדיקות המשך. הכלי המקובל אחרי Kruskal-Wallis נקרא מבחן Dunn, בן הדוד הלא פרמטרי של בדיקות ההמשך שעשית אחרי ANOVA. הוא משווה כל זוג קבוצות, ומתקן את ערכי ה-p כדי לפצות על כך שעכשיו עושים כמה השוואות. הנה מה שהוא מצא:
| השוואה | p מתוקן | מסקנה |
|---|---|---|
| משולב מול כתב | < .001 | נבדלים |
| משולב מול על-פה | .01 | נבדלים |
| כתב מול על-פה | .26 | לא נמצא הבדל מובהק |
עכשיו הסיפור מתחדד. הדירוגים הממוצעים והחציונים מראים שכיוון ההבדל הוא לטובת המשוב המשולב, ובדיקות Dunn מאשרות שההבדל מובהק מול שתי השיטות האחרות. לעומת זאת, בין המשוב בכתב למשוב בעל-פה לא נמצא הבדל מובהק. שימי לב לניסוח: לא "השתיים זהות", אלא "אין לנו עדות מספקת להבדל ביניהן". זה לא אותו דבר. אם היית עוצרת אחרי H המובהק וכותבת ש"שלוש השיטות נבדלו", היית אומרת יותר ממה שהנתונים מראים. רק בדיקות ההמשך גילו היכן ההבדל באמת נמצא.
זו גם הסיבה שלא הרצנו שלושה Mann-Whitney בלי תיקון. לא בגלל שאסור להשוות זוגות, אלא בגלל הצורך לפצות על ריבוי ההשוואות. הסדר המקובל הוא קודם השאלה הכוללת, ואז השוואות זוגיות מתוקנות. את זה בדיוק Kruskal-Wallis ובדיקות Dunn עושים יחד, ארוז כמו שצריך.
מה מותר לך להגיד
בדיוק כמו ב-Mann-Whitney, Kruskal-Wallis לא מדבר בשפת הממוצעים. הוא מדבר בשפת הנטייה: איזו קבוצה נוטה לקבל דירוגים גבוהים יותר. לכן בפרק התוצאות את מתארת את החציונים (כתב 3, על-פה 3.5, משולב 6) כתיאור, ואת המסקנה מנסחת כנטייה: התלמידים שקיבלו משוב משולב נטו לדווח על תחושת מסוגלות גבוהה יותר.
ויש כאן עוד דקות אחת ששווה להכיר, כי קל מאוד ליפול בה. בדיוק כמו Mann-Whitney, Kruskal-Wallis הוא לא בדיוק "מבחן לחציונים". הוא רגיש לכל הבדל בהתפלגות, לא רק בגובה שלה. כשקוראים את התוצאה כ"קבוצה אחת גבוהה יותר", ההנחה הסמויה היא שצורת ההתפלגות דומה בין הקבוצות. כאן הדירוגים הממוצעים והחציונים מצביעים לאותו כיוון, אז הקריאה הזאת מבוססת. עדיין, שווה להציץ בהתפלגויות עצמן לפני שמכריזים על כיוון.
איך מדווחים
תחושת המסוגלות נבדלה בין שלוש שיטות המשוב, מבחן Kruskal-Wallis, H(2) = 16.57, p < .001, ε² = .72. בדיקות המשך (Dunn, תיקון Holm) הראו שקבוצת המשוב המשולב (חציון 6) דירגה גבוה מהמשוב בכתב (חציון 3, p < .001) ומהמשוב בעל-פה (חציון 3.5, p = .01), בעוד שבין המשוב בכתב למשוב בעל-פה לא נמצא הבדל מובהק (p = .26).
שורה אחת שאומרת את הכול: שיש הבדל, כמה הוא חזק, ואיפה בדיוק הוא נמצא.
מתי זה המבחן הנכון
Kruskal-Wallis הוא המבחן לשלוש קבוצות או יותר בלתי תלויות, כשהמדד סדיר (כמו ליקרט) או כשהמדגם קטן וההתפלגות לא נורמלית. זאת המקבילה הלא פרמטרית של ANOVA חד-כיוונית.
אם המבנה שלך שונה, אותם נבדקים שנמדדו שלוש פעמים או יותר, זה כבר תכנון מזווג, והכלי הלא פרמטרי שלו הוא מבחן Friedman. אבל זה כבר לפוסט אחר. ואם יש לך רק שתי קבוצות בלתי תלויות, חזרי לMann-Whitney, שאת כבר מכירה.
הרעיון מאחורי הכול פשוט. כשהממוצע לא מתאים, הדירוגים שואלים את השאלה הנכונה. וכששואלים על שלוש קבוצות בבת אחת, שואלים אותה בשני שלבים: קודם האם יש הבדל אי-שם, ואז איפה. הסדר הזה הוא לא בירוקרטיה. הוא מה ששומר על אמינות המסקנה שלך.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.