ניתוח גורמים מאשש (CFA): איך בודקים אם המבנה שכבר יש לך בראש מתאים לנתונים

בפוסטים האחרונים הרצנו ניתוח גורמים חוקר, ונתנו לנתונים להגיד לנו כמה ממדים יש בשאלון ואיזה פריט שייך לאן. עכשיו את מגיעה למצב הפוך. כבר יש לך מבנה בראש.
לקחת שאלון מתוך מאמר שכבר טוען, שחור על גבי לבן, שיש בו שני תת-סולמות: שחיקה רגשית מצד אחד, תחושת הישג מקצועי מצד שני. את לא צריכה לגלות את המבנה הזה, הוא כבר ידוע. את צריכה לבדוק דבר אחר: האם הנתונים שלך, מהמדגם שלך, מתיישבים עם המבנה שהמאמר תיאר.
זאת שאלה אחרת לגמרי, והיא מצריכה כלי אחר. קוראים לו ניתוח גורמים מאשש, confirmatory factor analysis, או בקיצור CFA.
חוקר מול מאשש, ההבדל שמשנה הכל
בניתוח החוקר לא אמרת לתוכנה כלום מראש. נתת לה שש עמודות של נתונים והיא הציעה לך מבנה. כל פריט קיבל טעינות על כל גורם, והמבנה צמח מהמתאמים.
ב-CFA את עושה את ההפך. את מציירת את המודל לפני שאת מסתכלת על תוצאה אחת. את אומרת לתוכנה: שלושת פריטי השחיקה טוענים על גורם אחד בלבד, שלושת פריטי ההישג על גורם שני בלבד, ושמותר לשני הגורמים להיות מתואמים. זהו. זה המודל.
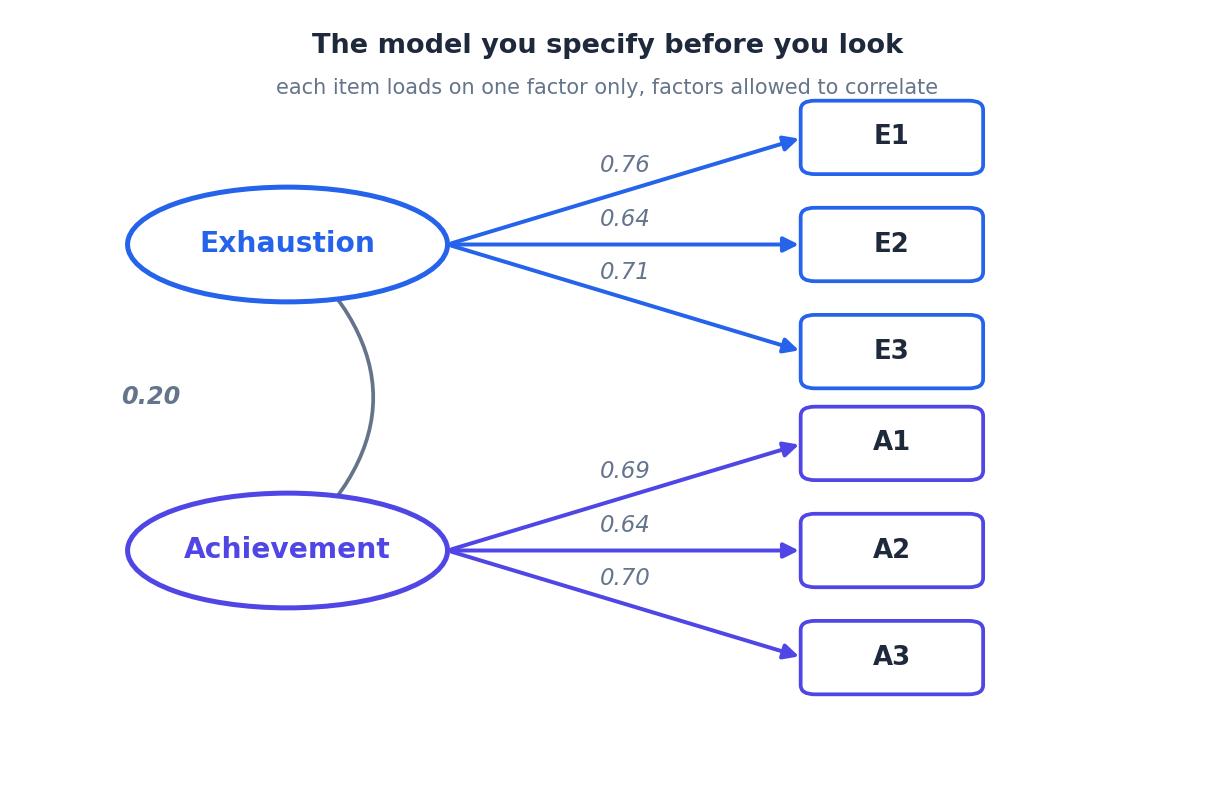
שימי לב למה שאין בתרשים הזה. אין אף חץ שמחבר את Exhaustion לפריט A, ואין אף חץ שמחבר את Achievement לפריט E. בניתוח החוקר כל פריט קיבל טעינות קטנה על הגורם השני. כאן את אוסרת על זה. את קובעת מראש שהטעינויות הצולבות הן אפס.
וזאת בדיוק הנקודה. האיסור הזה הוא מה שהופך את המודל לבדיק. כשאת מכריחה את הטעינויות הצולבות להיות אפס, את מתחייבת לתבנית מתאמים מסוימת מאוד. אם הנתונים האמיתיים לא נראים ככה, יישאר פער, והפער הזה הוא מה שנמדוד.
למה המודל יכול להיכשל, וזה כל העניין
מודל המדידה שציירת הוא בעצם תחזית, אבל לא תחזית שאת ממלאת ביד. קודם התוכנה אומדת, תחת ההגבלות שקבעת (אילו טעינויות מותרות ואילו מאופסות), את ערכי הטעינויות, את שונות השגיאה של כל פריט, ואת המתאם בין הגורמים. שלושת אלה יחד מייצרים מטריצת מתאמים שלמה: מה המתאם שהמודל מנבא בין E1 ל-A1, בין E2 ל-E3, וכן הלאה לכל זוג פריטים. זאת התחזית.
מצד שני יש את המטריצה האמיתית, זאת שיצאה מהנתונים שלך. CFA מעמיד את השתיים זו מול זו. כמה רחוקה המטריצה שהמודל מנבא מהמטריצה שבאמת מדדת. ההפרשים האלה בין נצפה לחזוי, על פני כל זוגות הפריטים, הם לב אי-ההתאמה. מדדי ההתאמה שתכף נראה מסכמים אותו מזוויות שונות, חלקם ישירות וחלקם ביחס למודל בסיס.
וזה מה שלא היה לך קודם. אלפא של קרונבך מקבלת את הקבוצה כנתון ולא יכולה לפסול אותה. הניתוח החוקר תמיד יציע לך איזשהו מבנה. ל-CFA, לעומתם, יש את היכולת להגיד לך לא. אם המבנה שהנחת רחוק מהנתונים, המדדים ייפלו, ותדעי שמשהו במבנה לא יושב.
ארבעה מספרים שמודדים את ההתאמה
הרצנו CFA על מודל שני הגורמים, על מדגם הדגמה של 300 משיבות. הנה מה שיצא, מדד אחר מדד.
מבחן חי בריבוע. זה המדד הוותיק. הוא בודק את ההשערה הקשוחה ביותר: שהמודל מתאים לנתונים בדיוק מושלם, שאפס פער. אצלנו יצא χ²(8) = 4.97, p = .76. ערך p גבוה כאן הוא דווקא בשורה טובה. הוא אומר שהמבחן לא מצא עדות לפער בין המודל לנתונים, שהפער קטן מספיק כדי להיות רעש דגימה.
אבל יש ל-χ² חולשה מפורסמת, והיא הפוכה ממה שאת רגילה אליו. ככל שהמדגם גדול יותר, המבחן רגיש יותר, וכמעט תמיד יוצא מובהק. במדגם של 800 משיבות גם פער זעיר וחסר חשיבות מעשית ייתן p קטן ויפסול מודל טוב לחלוטין. בגלל זה אף אחד לא מסתמך על χ² לבדו. מסתכלים עליו, ועוברים הלאה למדדים שפחות תלויים בגודל המדגם, ופחות נשענים על בדיקת ההתאמה המושלמת.
RMSEA. המדד הזה שואל כמה אי-התאמה יש לכל דרגת חופש, כלומר הוא מעניש מודל על כל פער, אבל נותן הנחה למודלים חסכוניים. הוא נמדד כך שנמוך זה טוב. כלל אצבע מקובל: עד 0.06 התאמה טובה, עד 0.08 עדיין סבירה, מעליה מתחילות בעיות. אצלנו RMSEA = 0.000, עם רווח סמך של 90 אחוז שנע בין 0.000 ל-0.047. כלומר גם הקצה הפסימי של הרווח עדיין בתוך התחום הטוב.
CFI ו-TLI. שני אלה עובדים בשיטה אחרת. הם משווים את המודל שלך למודל בסיס, מודל עצמאות שמניח שאף פריט לא קשור לאף פריט. לרוב הם נעים בטווח שבין 0 ל-1, וגבוה יותר זה טוב יותר. הם בעצם עונים על השאלה: כמה מהדרך מהמודל הריק ועד התאמה מושלמת המודל שלך עבר. כלל אצבע מקובל: 0.95 ומעלה נחשב התאמה טובה. אצלנו שניהם יצאו מעט מעל 1 (בערך 1.01), דבר שקורה לפעמים כשההתאמה כמעט מושלמת, ונהוג לעגל או לקטום אותו ל-1.00.
SRMR. זה האינטואיטיבי מכולם. הוא לוקח את כל הפערים שנשארו בין המתאמים שנצפו למתאמים שהמודל ניבא, מעלה כל פער בריבוע, ממצע, ומחזיר שורש. בקירוב, כמה מתאם המודל פספס בכל זוג פריטים. גם כאן נמוך זה טוב, והרף המקובל הוא עד 0.08. אצלנו SRMR = 0.022, פספוס זעיר. קרוב מאוד.
ארבעת המדדים מסכימים פה אחד. מודל שני הגורמים מתאים לנתונים יפה. אבל הסכמה כשהכל ורוד היא החלק הקל. הערך של CFA מתגלה כשנותנים לו מודל לא נכון.
אותם נתונים, מבנה שגוי
נעשה את הניסוי שמראה מה CFA באמת שווה. ניקח בדיוק את אותם נתונים, ונכפה עליהם מודל של גורם אחד. כלומר נטען שכל ששת הפריטים, גם השחיקה וגם ההישג, מודדים דבר אחד גדול. בדיוק המבנה שהמנחה חשד בו בפוסט החוקר.
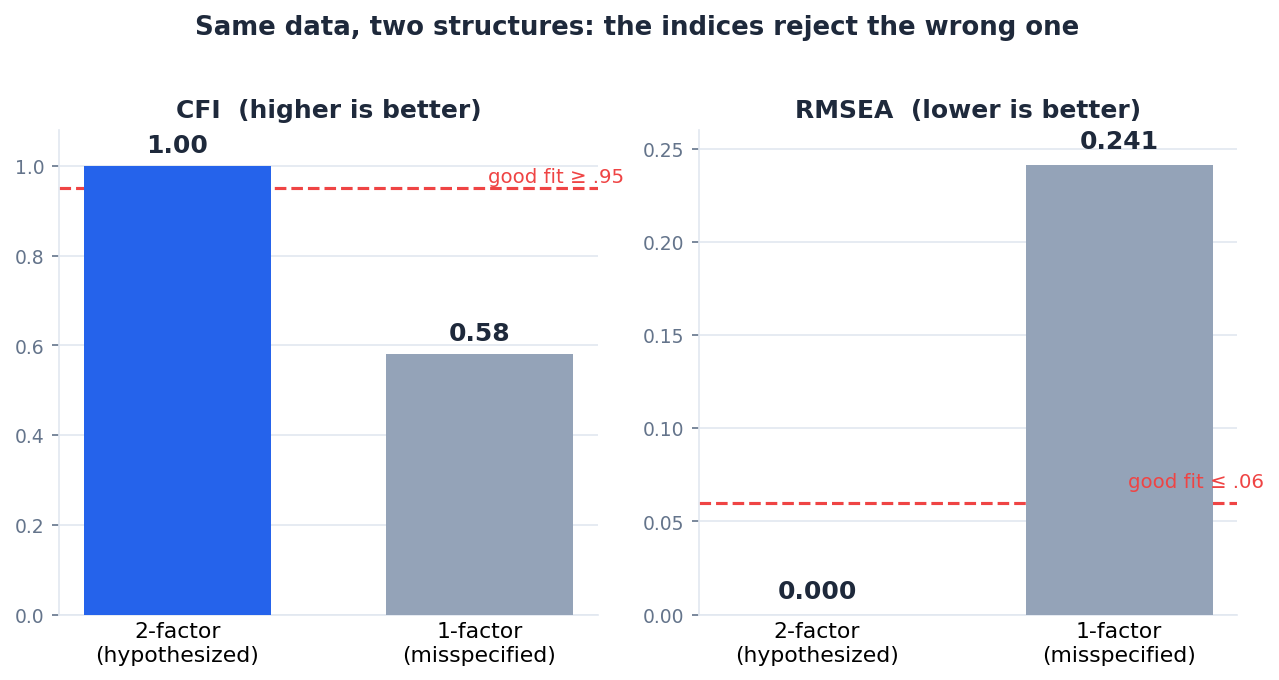
תראי מה קרה למספרים. χ² קפץ ל-165.77 על 9 דרגות חופש, p קטן מ-.001. CFI צנח מ-1.00 ל-0.58. RMSEA זינק מאפס ל-0.241, יותר מפי ארבעה מעל הרף. SRMR טיפס ל-0.163. כל מדד, בלי יוצא מן הכלל, מצביע על אותו דבר: המבנה הזה לא מתאים לנתונים.
זה מה ש-CFA נותן לך שאף כלי קודם לא נתן. הוא לא רק מתאר את הנתונים, הוא שופט מבנה מוצע ויכול לדחות אותו. כשהמודל של גורם אחד נכשל ככה, ושל שני גורמים עובר בגדול, יש לך עכשיו עדות אמיתית, לא רק ציטוט מהמאמר, שהנתונים שלך מתיישבים עם שני ממדים נפרדים הרבה יותר טוב מאשר עם ממד אחד.
הערה אחת על הדוגמה. הנתונים פה הם הדגמה, ואנחנו יודעים שהם נולדו ממבנה דו-גורמי, ולכן ההבחנה יצאה כל כך חדה. בנתוני אמת היא כמעט תמיד פחות נקייה. זה לא מקלקל את הלקח, רק מזכיר שבשטח צריך שיקול דעת, לא רק טבלת מדדים.
שלושה דברים שצריך לדעת לפני שסוגרים
ההתלהבות מהתאמה טובה מצריכה שלושה סייגים, וכולם חשובים.
הראשון, ואולי הכי קל לפספס. CFA אמור לרוץ על מדגם אחר מזה שעליו עשית את הניתוח החוקר. אם נתת לנתונים להציע מבנה ואז בדקת על אותם נתונים אם הם מתאימים למבנה שהם בעצמם הציעו, הסתובבת במעגל. בעולם אידיאלי מפצלים את המדגם, או מאששים על איסוף חדש. אצלנו, לכן, הדגמנו על מדגם טרי של 300, ולא על המדגם מהפוסט החוקר.
השני. התאמה טובה לא אומרת "המודל נכון". היא אומרת "המודל לא נסתר". יכולים להיות עוד מבנים שמתאימים לאותם נתונים באותה מידה. CFA פוסל מבנים גרועים בביטחון, אבל הוא לא מכתיר מבנה אחד כאמת היחידה. הוא תומך במה שהתאוריה שלך הציעה, לא מוכיח אותו.
השלישי. כשמודל לא מתאים, התוכנה מציעה לפעמים "תיקונים", מדדי שינוי שאומרים איזה חץ להוסיף כדי לשפר את ההתאמה. קל להתפתות ולרדוף אחרי ההתאמה ככה, חץ אחרי חץ, עד שהמדדים יפים. אבל מודל שכל קשר בו נבחר רק כי הוא ייפה את המספרים כבר לא בודק תאוריה, הוא מצייר מחדש את הנתונים. תיקון לגיטימי רק אם יש לו הצדקה תאורטית, לא רק סטטיסטית.
איך כותבים את זה בפרק השיטות
כמו תמיד, כל מה שעברנו עליו מתכווץ לכמה שורות. קודם איזה מודל בדקת, אחר כך המדדים, ובסוף הממצא.
נערך ניתוח גורמים מאשש (CFA) לבחינת מבנה שני הגורמים של השאלון (שחיקה רגשית, תחושת הישג), באמצעות חבילת semopy. מודל שני הגורמים הראה התאמה טובה לנתונים: χ²(8) = 4.97, p = .76, CFI = 1.00, TLI = 1.00, RMSEA = .000, 90% CI [.000, .047], SRMR = .022. כל הפריטים נטענו על הגורם התאורטי שלהם בטעינויות סטנדרטיות שבין .64 ל-.76, והמתאם בין שני הגורמים היה .20. מודל חלופי של גורם יחיד הראה התאמה ירודה (CFI = .58, RMSEA = .241), ונדחה לטובת מבנה שני הגורמים.
יש שם את המודל, את המדדים שבודק רוצה לראות, ואת ההשוואה למודל החלופי שמחזקת את הטיעון. אין שם הסבר מה זה RMSEA, ואין התנצלות.
נשאר חוט אחד פתוח, והוא גם הסוף של הסדרה הזאת. עד עכשיו רק מדדנו גורמים, ושאלנו אם הפריטים מתחברים אליהם נכון. זה נקרא מודל המדידה. אבל מה אם את רוצה לשאול שאלה על הקשר בין הגורמים עצמם, למשל האם שחיקה רגשית מנבאת את תחושת ההישג. כשמחברים בין גורמים חבויים בחיצים מכוונים, מודל המדידה גדל למודל משוואות מבניות מלא, SEM. וזאת התחנה הבאה.