המנחה אמר "תכניסי את המגזר לרגרסיה": איך מכניסים משתנה קטגוריאלי למודל

בנית רגרסיה יפה. ותק ועומס מנבאים שחיקה, הכל מובהק, המנחה מרוצה. ואז הוא אומר: "יופי. עכשיו תוסיפי גם את המגזר. אני רוצה לראות אם השחיקה שונה בין ממלכתי, ממלכתי-דתי וחרדי."
ועצרת. כי כל מה שהכנסת עד עכשיו לרגרסיה היה מספר אמיתי: שנים, נקודות בסולם, גיל. מגזר הוא לא מספר. הוא קטגוריה, ויש לו שלוש רמות בלי שום סדר טבעי ביניהן. אז מה כותבים בעמודה?
הסיטואציה: שלושה מגזרים, ציון שחיקה אחד
נניח 90 מורות בתכנית M.Ed, 30 מכל מגזר: ממלכתי, ממלכתי-דתי, חרדי. כולן מילאו את אותו שאלון שחיקה (ציון 0 עד 100). השאלה של המנחה במילים פשוטות: האם ציון השחיקה הממוצע נבדל בין שלושת המגזרים.
הממוצעים שיצאו לך:
| מגזר | n | ממוצע שחיקה |
|---|---|---|
| ממלכתי | 30 | 52.0 |
| ממלכתי-דתי | 30 | 58.0 |
| חרדי | 30 | 47.0 |
סטיית התקן בתוך כל קבוצה דומה, בערך 11 נקודות. שימי לב לתבנית: הדתי הוא הגבוה ביותר, החרדי הנמוך ביותר, והממלכתי באמצע. זאת לא עלייה מסודרת מקטגוריה לקטגוריה. נחזור לזה, כי שם נמצאת הטעות הכי נפוצה.
הקודים 1, 2, 3 הם תוויות, לא כמויות
ב-SPSS המגזר כנראה מקודד אצלך כמספר: 1 = ממלכתי, 2 = ממלכתי-דתי, 3 = חרדי. זה נוח לאחסון, אבל המספרים האלה הם רק תוויות. הם לא אומרים שחרדי "שווה פי שלושה" ממלכתי, ולא שהמרחק בין 1 ל-2 זהה למרחק בין 2 ל-3.
אם תכניסי את העמודה הזאת לרגרסיה כמו שהיא, המודל יתייחס אליה כאל מספר רציף ויחפש שיפוע אחד: "כל עלייה של יחידה בקוד המגזר קשורה לשינוי של כך וכך בשחיקה." זאת שאלה חסרת פשר, כי קוד המגזר אינו כמות. עוד מעט נראה בדיוק כמה נזק זה עושה למספרים.
הדרך הנכונה להכניס משתנה קטגוריאלי לרגרסיה היא לתרגם אותו לאוסף של משתני דמה (dummy variables), כל אחד מהם בינארי, 0 או 1.
משתני דמה: איך מתרגמים קטגוריה למספרים
הרעיון: במקום עמודה אחת עם שלושה קודים, בונים עמודות חדשות שכל אחת עונה על שאלת כן/לא אחת. בוחרים קטגוריה אחת שתשמש קטגוריית ייחוס (reference), ולכל קטגוריה אחרת מייצרים משתנה דמה משלה.
נבחר בממלכתי כקטגוריית הייחוס. אז:
| מגזר | D₁ (דתי) | D₂ (חרדי) |
|---|---|---|
| ממלכתי (ייחוס) | 0 | 0 |
| ממלכתי-דתי | 1 | 0 |
| חרדי | 0 | 1 |
שני דברים שכדאי לשים לב אליהם. ראשית, מורה ממלכתית מקבלת 0 בשני המשתנים. קטגוריית הייחוס היא ה"ברירת מחדל", זו שלא צריך דגל מיוחד כדי לזהות. שנית, יש שלוש קטגוריות אבל רק שני משתני דמה. זה לא קיצור דרך, זה הכרח.
למספר קטגוריות k מייצרים תמיד k − 1 משתני דמה. הקטגוריה ה-k-ית מיוצגת על ידי 0 בכל המשתנים.
למה לא דמה שלישי לממלכתי? כי הוא יהיה מיותר לחלוטין: אם את כבר יודעת שמורה אינה דתית (D₁ = 0) ואינה חרדית (D₂ = 0), נובע בוודאות שהיא ממלכתית. עמודה שלישית לא תוסיף שום מידע, והיא תהיה תלויה לינארית באחרות. זה מצב שנקרא "מלכודת הדמה" (dummy trap), והוא יוצר מולטיקולינאריות מושלמת שמונעת מהמודל בכלל להיפתר. SPSS או R פשוט ישמיטו את העמודה העודפת בשבילך.
מאיפה כל מקדם מגיע
המשוואה עכשיו נראית כך:
burnout = a + β₁ · D₁ + β₂ · D₂
בואי נציב כל מגזר ונראה מה המודל חוזה:
- ממלכתי (D₁ = 0, D₂ = 0): החיזוי הוא פשוט
a. - ממלכתי-דתי (D₁ = 1, D₂ = 0): החיזוי הוא
a + β₁. - חרדי (D₁ = 0, D₂ = 1): החיזוי הוא
a + β₂.
וברגרסיה עם מנבאים קטגוריאליים בלבד, החיזוי לכל קבוצה הוא בדיוק ממוצע הקבוצה. מכאן נופלים כל המקדמים למקומם:
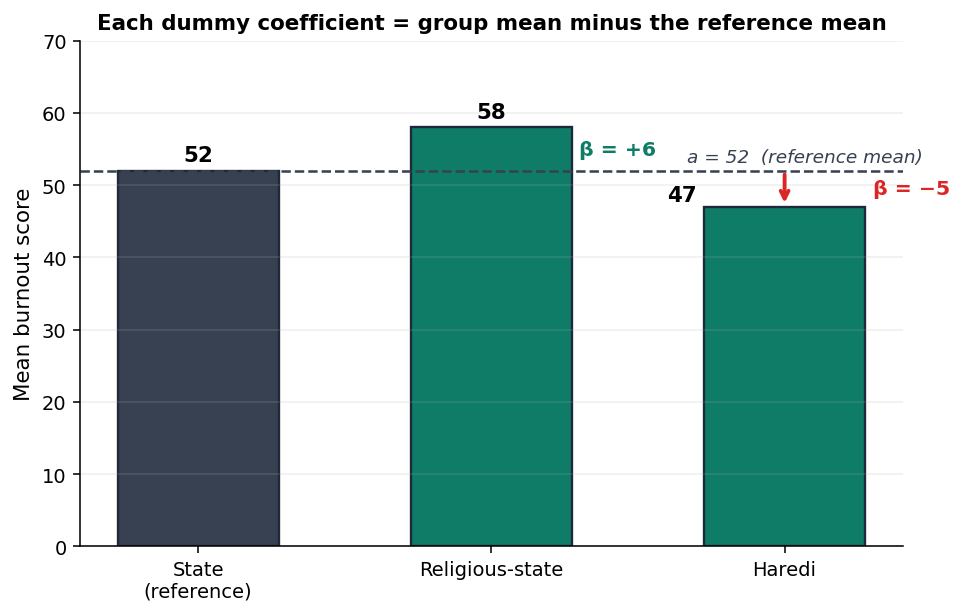
a= ממוצע קטגוריית הייחוס = ממוצע הממלכתי = 52.0.β₁= ממוצע הדתי פחות ממוצע הייחוס = 58.0 − 52.0 = +6.0.β₂= ממוצע החרדי פחות ממוצע הייחוס = 47.0 − 52.0 = −5.0.
זאת התובנה המרכזית של כל הפוסט. החיתוך הוא הממוצע של קטגוריית הייחוס, וכל מקדם דמה הוא ההפרש בין הקבוצה שלו לקטגוריית הייחוס. לא ההפרש מהממוצע הכללי, ולא הממוצע של הקבוצה עצמה. ההפרש מהייחוס. אם תזכרי רק משפט אחד מפה, שיהיה זה.
הפלט, שורה אחר שורה
הרצת את הרגרסיה עם שני משתני הדמה וקיבלת:
| מקדם | ערך | SE | t(87) | p | 95% CI |
|---|---|---|---|---|---|
| חיתוך (a) | 52.00 | 2.01 | 25.90 | < .001 | [48.0, 56.0] |
| β₁ (דתי מול ממלכתי) | 6.00 | 2.84 | 2.11 | .038 | [0.4, 11.6] |
| β₂ (חרדי מול ממלכתי) | -5.00 | 2.84 | -1.76 | .082 | [-10.6, 0.6] |
ומדדי המודל הכולל: F(2, 87) = 7.52, p < .001, R² = η² = 0.147.
עכשיו נקרא כל שורה כמו שצריך לכתוב בפרק הממצאים:
β₁ = 6.0. "מורות במגזר הממלכתי-דתי דיווחו בממוצע על 6.0 נקודות שחיקה יותר מאשר מורות במגזר הממלכתי" (קטגוריית הייחוס). המקדם מובהק, t(87) = 2.11, p = .038, ורווח הסמך הוא [0.4, 11.6]. שימי לב שהרווח רחב מאוד וקצהו התחתון כמעט נוגע באפס. ההפרש מובהק, אבל לא מדויק: הנתונים עקביים גם עם הבדל קטנטן של פחות מנקודה וגם עם הבדל של כמעט 12 נקודות.
β₂ = −5.0. "מורות במגזר החרדי דיווחו בממוצע על 5.0 נקודות שחיקה פחות מאשר מורות במגזר הממלכתי." כאן t(87) = −1.76, p = .082, ורווח הסמך [−10.6, 0.6] חוצה את האפס. ההפרש מהייחוס אינו מובהק. הנתונים לא מאפשרים לך לשלול שאין בכלל הבדל בין חרדי לממלכתי.
החיתוך a = 52.0 הוא ממוצע השחיקה של הממלכתי. כאן, בניגוד לרגרסיה רגילה עם מנבא רציף, החיתוך כן בעל פרשנות מהותית: זה לא "החיזוי כשהכל אפס בצורה לא מציאותית", אלא ממש הממוצע של קבוצת הייחוס.
ולגבי גודל האפקט הכולל: η² = 0.147 אומר שכ-15% מהשונות בציוני השחיקה מוסברת על ידי השתייכות מגזרית. לפי אמות המידה המקובלות של כהן זה אפקט גדול יחסית (η² בסביבות .14 ומעלה), אבל אמות המידה האלה הן כלליות ולא חזות הכל. בתחומים מסוימים בחינוך 15% הוא הרבה, ובאחרים פחות. ההקשר התיאורטי קובע אם זה מרשים.
הערה אחת על תכן המחקר: זה מחקר תצפיתי, לא ניסוי. מורות לא הוקצו אקראית למגזר. לכן נכון לומר שהשחיקה נבדלת בין המגזרים או קשורה למגזר, אבל לא שהמגזר גורם לשחיקה. ייתכנו עשרות גורמים מתערבים (גודל כיתה, ותק ממוצע שונה, תרבות ארגונית) שנעים יחד עם המגזר.
רגע, זה בעצם ה-ANOVA שלך
אם המספר F(2, 87) = 7.52 נראה לך מוכר, יש לזה סיבה טובה. אם תריצי על אותם נתונים ANOVA חד-כיוונית עם מגזר כגורם, תקבלי בדיוק את אותו F, את אותן דרגות חופש, ואת אותו p. וה-η² של ה-ANOVA יהיה זהה ל-R² של הרגרסיה, שניהם 0.147.
זה לא צירוף מקרים. ANOVA ורגרסיה עם משתני דמה הם אותו מודל מתמטי בדיוק, בשני אריזות מילוליות. ה-ANOVA שואל "כמה מהשונות בשחיקה נמצאת בין הקבוצות לעומת בתוכן", והרגרסיה שואלת "כמה כל קבוצה נבדלת מהייחוס". המבחן הכולל זהה. ההבדל הוא שהרגרסיה נותנת לך גם את ההפרשים הספציפיים מול הייחוס כמקדמים מפורשים עם רווחי סמך, בעוד שב-ANOVA צריך פוסט-הוק נפרד כדי לקבל אותם.
וזה מתחבר גם אחורה. אם היו לך רק שתי קטגוריות (נניח מגדר, או טיפול מול ביקורת), היה לך משתנה דמה אחד בלבד, והרגרסיה איתו שקולה בדיוק למבחן t לשתי קבוצות בלתי תלויות. המקדם של הדמה יהיה ההפרש בין הממוצעים, וה-t יהיה זהה. למעשה t² = F. אותה משפחה אחת של מודלים, שמתרחבת מקבוצה אחת ועד כמה שצריך.
הטעות שעולה ביוקר: להכניס את הקוד 1/2/3 כמספר
עכשיו נחזור לקיצור הדרך המפתה, ונראה כמה הוא הורס. נניח שדילגת על הדמה והכנסת את עמודת הקוד (1, 2, 3) ישירות לרגרסיה כמנבא רציף יחיד. המודל מחפש שיפוע אחד, וה-OLS מתאים לשלוש הנקודות (1, 52), (2, 58), (3, 47) קו ישר יחיד. השיפוע שיוצא הוא β = −2.5.
הפרשנות הנכפית: "כל עלייה של יחידה בקוד המגזר קשורה לירידה של 2.5 נקודות שחיקה." בואי נראה מה הקו הזה חוזה לכל מגזר, מול הממוצע האמיתי:
| מגזר (קוד) | ממוצע אמיתי | חיזוי לפי הקוד המספרי |
|---|---|---|
| ממלכתי (1) | 52.0 | 54.8 |
| ממלכתי-דתי (2) | 58.0 | 52.3 |
| חרדי (3) | 47.0 | 49.8 |
תסתכלי על שורת הדתי. הממוצע האמיתי הוא הגבוה ביותר מכל השלושה, 58, והמודל המספרי חוזה לו 52.3, באמצע. הקו הישר מוכרח להניח שמגזר 2 נופל בין מגזר 1 למגזר 3, כי כך עובד שיפוע לינארי. אבל בנתונים שלך הדתי לא באמצע, הוא בקצה העליון. המודל המספרי לא מסוגל לתפוס את זה. הוא מחמיץ את כל שלוש הקבוצות בו-זמנית.
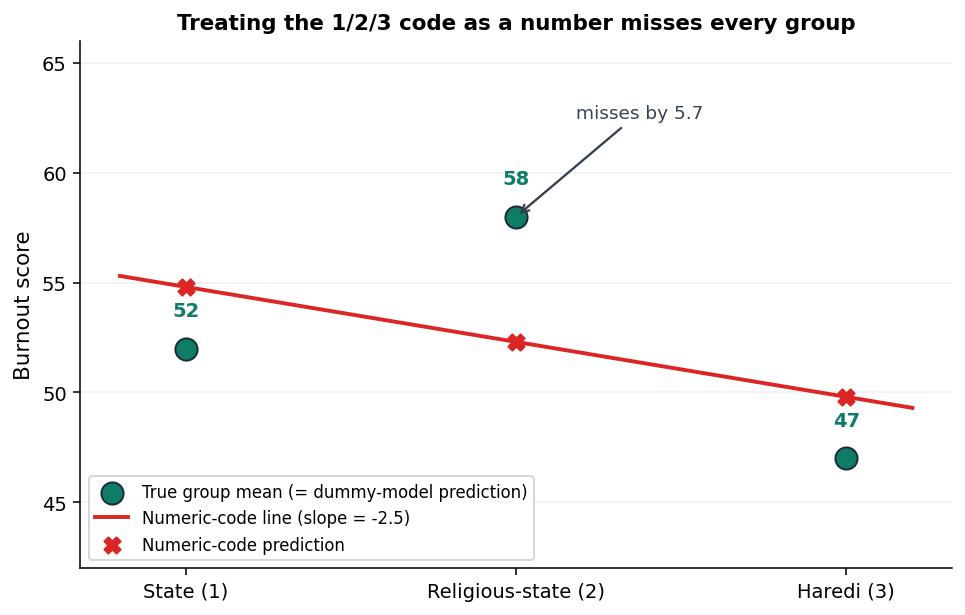
לעומתו, מודל הדמה חוזה לכל קבוצה את הממוצע האמיתי שלה במדויק: 52, 58, 47. בלי שארית ברמת הקבוצה.
ויש מכה שנייה, חמורה לא פחות: התוצאה של הקידוד המספרי תלויה בתוויות השרירותיות. אם מחר תחליפי את הקודים ל-1 = חרדי, 2 = ממלכתי, 3 = דתי, אותם נתונים בדיוק ייתנו שיפוע אחר לגמרי, כי הסדר על הציר השתנה. מספר שמשתנה כשאת מחליפה תוויות חסרות משמעות אינו ממצא, הוא ארטיפקט. זאת בדיוק הסיבה שהוועדה תעצור על קידוד מספרי של משתנה קטגוריאלי נומינלי, והניתוח יחזור אליך לתיקון.
(חריג אחד שכדאי להכיר: אם המשתנה הקטגוריאלי שלך אורדינלי ובעל מרווחים שווים בקירוב, למשל "נמוך / בינוני / גבוה", יש מי שיטפל בו כמספר רציף בכוונה כדי לבדוק מגמה לינארית. זאת בחירה מודעת שצריך להצדיק, לא ברירת מחדל. למשתנה נומינלי כמו מגזר, שאין בו סדר, זה פשוט שגוי.)
בחירת קטגוריית הייחוס, ומה המקדמים לא אומרים לך
בחרנו בממלכתי כייחוס, אז שני המקדמים השוו דתי-מול-ממלכתי וחרדי-מול-ממלכתי. אבל מה עם דתי מול חרדי? ההפרש הזה (58 − 47 = 11 נקודות, הגדול מכולם) לא מופיע כמקדם בטבלה. משתני הדמה נותנים לך רק את ההשוואות מול הייחוס, לא את כל הזוגות.
אם דתי-מול-חרדי הוא ההשוואה המעניינת אותך תיאורטית, יש שתי דרכים: להגדיר מחדש את קטגוריית הייחוס (למשל לבחור בחרדי כייחוס ולהריץ שוב, ואז יופיע מקדם דתי-מול-חרדי), או להוסיף מבחני פוסט-הוק עם תיקון לריבוי השוואות. הבחירה איזו קטגוריה תהיה הייחוס לא משנה את ה-F הכולל, את ה-R², ואת החיזוי לכל קבוצה. היא משנה רק אילו הפרשים מקבלים שורה מפורשת בטבלה.
איך בוחרים? בדרך כלל לפי אחת מהאלה: קבוצת הביקורת או ה"ברירת מחדל" הטבעית (כמו הממלכתי כאן), הקבוצה הגדולה ביותר, או הקבוצה שהמנחה שלך רוצה שהכל יושווה אליה. אין בחירה "נכונה" אחת, יש בחירה שמשרתת את השאלה שלך.
איך לכתוב בפרק הממצאים
נערכה רגרסיה לבדיקת ההבדל בשחיקה בין שלושה מגזרים (N = 90, 30 בכל מגזר), כאשר המגזר קודד בשני משתני דמה והמגזר הממלכתי שימש קטגוריית ייחוס. המודל הכולל נמצא מובהק,
F(2, 87) = 7.52, p < .001, והסביר 14.7% מהשונות בשחיקה (R² = η² = .15). מורות במגזר הממלכתי-דתי דיווחו על שחיקה גבוהה יותר מהמגזר הממלכתי (β = 6.00, SE = 2.84, t(87) = 2.11, p = .038, 95% CI [0.4, 11.6]), ואילו ההפרש בין המגזר החרדי לממלכתי לא הגיע למובהקות (β = −5.00, SE = 2.84, t(87) = −1.76, p = .082, 95% CI [−10.6, 0.6]).
הצהרת המודל הכולל עם גודל אפקט, ואז כל מקדם דמה עם רווח סמך וציון מפורש מול מה הוא מושווה. אם המנחה רוצה גם את ההשוואה דתי-מול-חרדי, הוסיפי שורה על פוסט-הוק או על הרצה חוזרת עם ייחוס אחר.
מה לקחת מפה לעבודה שלך
- משתנה קטגוריאלי לא נכנס לרגרסיה כקוד מספרי. אם המגזר מקודד 1/2/3, אל תכניסי את העמודה הזאת כמנבא. תרגמי אותה למשתני דמה.
- מספר הדמה הוא תמיד מספר הקטגוריות פחות אחת. שלוש קטגוריות, שני דמה. הקטגוריה החסרה היא הייחוס, ומקבלת 0 בכל המשתנים.
- קראי כל מקדם נכון: החיתוך הוא ממוצע קטגוריית הייחוס, וכל מקדם דמה הוא ההפרש בין הקבוצה שלו לייחוס. לא הממוצע שלה, ולא ההפרש מהממוצע הכללי.
- דווחי גודל אפקט ורווח סמך, לא רק p. ל-
η²הכולל וגם CI לכל מקדם דמה. רווח רחב שכמעט נוגע באפס אומר שההפרש מובהק אבל לא מדויק, וזה מידע אמיתי על הביטחון שלך בו. - זכרי שזה אותו מודל כמו ה-ANOVA (ולשתי קבוצות, כמו מבחן t). אם בחרת רגרסיה, זה בדרך כלל כי את רוצה את משתני הדמה כדי לשלב את המגזר יחד עם מנבאים רציפים אחרים (ותק, עומס) באותו מודל. שם הכוח האמיתי: לשאול מה הקשר של המגזר עם שחיקה כשמחזיקים את הוותק קבוע, וזה כבר רגרסיה מרובה במלוא מובן המילה.
- בחרי קטגוריית ייחוס שמשרתת את השאלה, ואם ההשוואה שמעניינת אותך היא בין שתי קטגוריות שאף אחת מהן אינה הייחוס, החליפי ייחוס או הוסיפי פוסט-הוק. היא לא תופיע לבד.
ואם נשאר חלק שעדיין מעורפל, זה לא סימן שמשהו אצלך לא בסדר. זה פשוט החלק הבא בדרך.
העבודה הזאת שלך. הסטטיסטיקה כאן כדי לשרת אותה.
וכשבא לך שמישהו יריץ את הניתוח כמו שצריך, מדויק, בדוק, מוכן לוועדה, אני כאן.
דוח ממצאים מלא: ₪1,500. עם מסגרת דיון מונחית: ₪2,000.