מודל משוואות מבניות (SEM): לקשר בין גורמים חבויים, ולמה רגרסיה על הממוצעים מחמיצה חלק מהקשר

המנחה הסתכל על הניתוח שלך ואמר משהו בסגנון: "אל תריצי רגרסיה על ממוצעי תת-הסולמות. תריצי את זה כ-SEM." הלכת הביתה עם מילה בת שלוש אותיות ובלי להבין במה זה שונה ממה שכבר עשית.
אז קודם כל, אין כאן שום דבר מביך. SEM הוא באמת שלב מתקדם, והוא לא נלמד בקורס המבוא. אם הגעת לפה כי יש לך מבנה של גורמים חבויים ומישהו ביקש לקשר ביניהם, את בדיוק במקום הנכון. בואי נלך דרך זה לאט.
מאיפה הגענו לכאן
בניתוח גורמים מאשש בנינו מודל מדידה. אמרנו לתוכנה אילו פריטים מודדים איזה גורם חבוי, ובדקנו אם הנתונים מתיישבים עם המבנה הזה. אבל שם עצרנו. נתנו לגורמים להיות מתואמים זה עם זה, בקו מעוקל עם שני ראשים, ולא יותר מזה. לא שאלנו מי משפיע על מי.
עכשיו את רוצה לשאול בדיוק את זה. לא רק "האם שחיקה רגשית והישג מקצועי הם שני ממדים נפרדים", אלא "האם שחיקה רגשית מנבאת את תחושת ההישג". ברגע שאת מחליפה את הקו הדו-ראשי בחץ מכוון, מודל המדידה הופך למשהו גדול יותר. קוראים לו מודל משוואות מבניות, structural equation modeling, או בקיצור SEM.
SEM זה שני מודלים בבת אחת
הרעיון כולו מתכווץ למשפט אחד. SEM הוא מודל מדידה ועוד מודל מבני, שנאמדים יחד.
מודל המדידה הוא החלק שאת כבר מכירה. אילו פריטים טוענים על איזה גורם חבוי. זה ה-CFA שעשינו. המודל המבני זה החדש: החצים המכוונים בין הגורמים עצמם, מי מנבא את מי. שני החלקים נאמדים בו-זמנית, בהרצה אחת, על אותם נתונים.
ניקח דוגמה מאותו עולם של רווחת המורה. נוסיף גורם חבוי שלישי, עומס בעבודה, שנמדד בשלושה פריטים משלו. עכשיו יש לנו שלושה גורמים חבויים, כל אחד עם שלושה פריטים, ושאלה תאורטית שמחברת ביניהם: לפי ההשערה, עומס מזין שחיקה, ושחיקה שוחקת את תחושת ההישג.
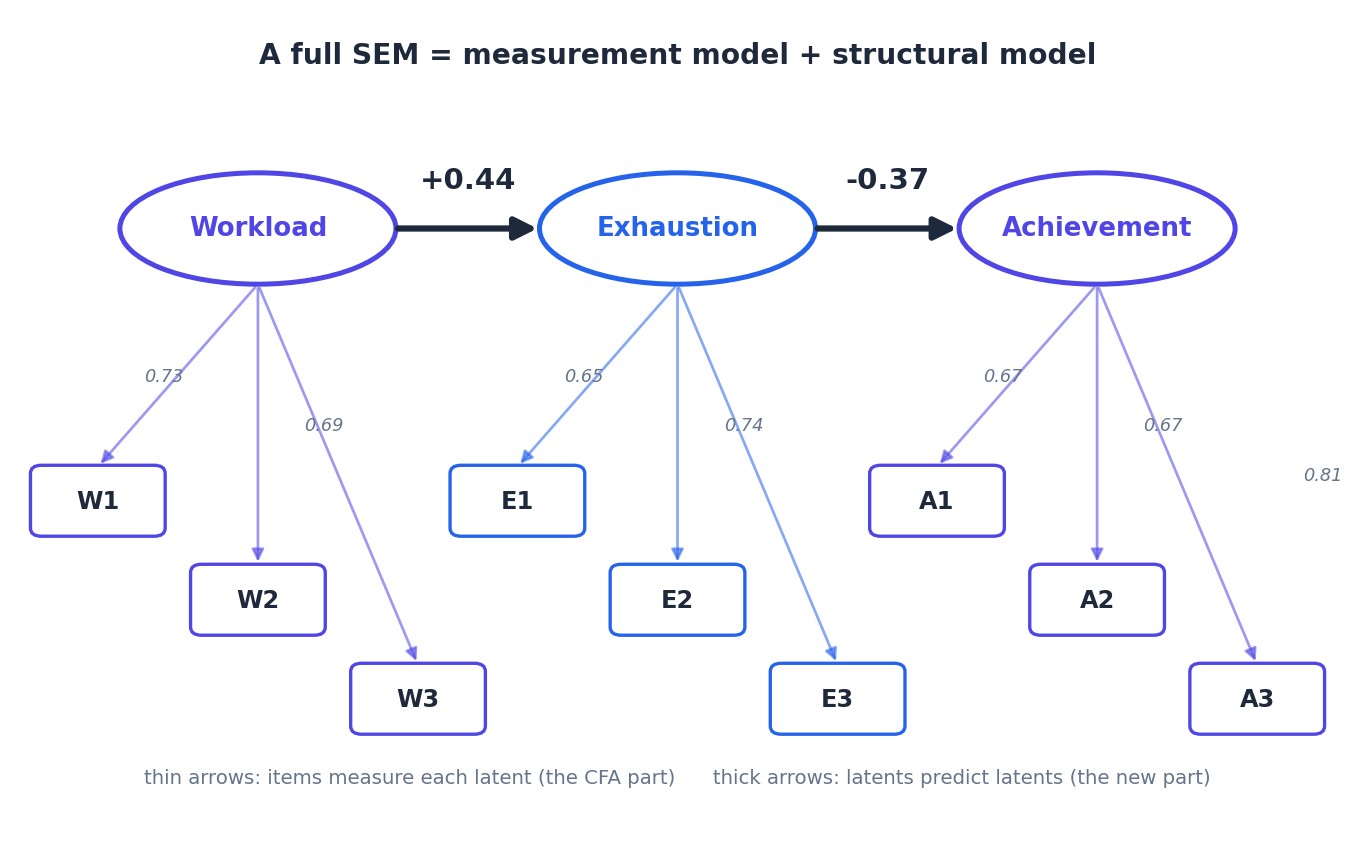
תסתכלי על שני סוגי החצים בתרשים. החצים הדקים והבהירים, מהאליפסות אל התיבות, הם מודל המדידה. כל גורם חבוי "נמדד" דרך שלושת הפריטים שלו, בדיוק כמו ב-CFA. החצים העבים והכהים, בין האליפסות, הם המודל המבני. הם התאוריה שלך על מי משפיע על מי. הכיוון שלהם מגיע מהתאוריה ומהתכנון המחקרי, לא מהנתונים. זה החלק שלא היה לך קודם.
שתי שאלות, תשובה אחת
כשמריצים SEM מקבלים תשובה לשתי שאלות שונות בבת אחת, וכדאי לא לבלבל ביניהן.
השאלה הראשונה היא שאלת ההתאמה. האם המבנה הזה, על המדידה ועל החצים שלו, מתיישב עם הנתונים. כאן קוראים בדיוק את אותם מדדים שהכרנו ב-CFA, ובאותם כללי אצבע. הרצנו את המודל על מדגם הדגמה של 400 משיבות, והנה מה שיצא: χ²(25) = 30.40, p = .21, CFI = .994, TLI = .991, RMSEA = .023 עם רווח סמך [.000, .048], ו-SRMR = .031. כל המדדים בתחום הטוב. המבנה יושב על הנתונים יפה.
השאלה השנייה היא החדשה, וזה מה שבאמת רצית. כמה חזקים החצים המבניים. את התשובה קוראים מתוך המקדמים הסטנדרטיים של המודל, והם עובדים כמו מקדמי רגרסיה: עומס לשחיקה יצא 0.44, ושחיקה להישג יצא 0.37- (שלילי, כי יותר שחיקה פירושה פחות תחושת הישג). הנתיב המרכזי, מהשחיקה אל ההישג, מובהק בבירור (האומדן הלא-מתוקנן 0.385-, z = 5.13-, p < .001). כלומר לא רק שהמבנה מתאים, אלא שיש קשר שלילי ממשי בין שני הגורמים, וזה מה שביקשת לבדוק.
אגב, המבנה הזה, עומס שמשפיע על הישג דרך שחיקה, הוא בעצם מודל תיווך. ההבדל מהפוסט על תיווך הוא שכאן המשתנים אינם נמדדים ישירות אלא חבויים, מאחורי הפריטים. וזה בדיוק ההבדל ששווה את הטרחה.
אז למה לא פשוט לחשב ממוצע ולהריץ רגרסיה
זאת השאלה שהמנחה ענה עליה בלי להסביר. ואפשר באמת לתהות. למה כל הטרחה. למה לא לחשב ממוצע של שלושת פריטי השחיקה, ממוצע של שלושת פריטי ההישג, ולהריץ רגרסיה פשוטה בין שני הממוצעים. זה מה שרובן עושות, וזה לא טיפשי.
הבעיה היא שכל ממוצע כזה הוא מדידה רועשת. הפריטים שלך לא מודדים את הגורם החבוי במדויק. מהימנות תת-הסולם אצלנו היא בסביבות 0.74, וזה אומר שבערך רבע מהשונות בציון הממוצע הוא רעש מדידה, לא הגורם האמיתי. כשאת מכניסה לרגרסיה משתנה מורעש, הקשר שהיא מודדת מוטה כלפי מטה, לכיוון האפס. התופעה הזאת נקראת היחלשות, attenuation, וכשרעש המדידה אקראי ובלתי תלוי, ההיחלשות שיטתית, ותמיד באותו כיוון: היא מקטינה את הקשר.
SEM נועד בדיוק בשביל זה. כשהגורם מיוצג כמשתנה חבוי שמאחורי שלושה פריטים, התוכנה מפרידה את החלק המשותף לשלושת הפריטים (הגורם) מהרעש הייחודי לכל פריט. החץ המבני נמדד על החלק המשותף הזה, לא על הממוצע המורעש. התנאי לכך הוא שמודל המדידה עצמו סביר, שהפריטים באמת מודדים את הגורם והמבנה מתאים לנתונים. כשזה מתקיים, האומדן בדרך כלל פחות מוחלש לכיוון האפס.
תראי מה קורה כשמריצים את אותו נתיב, שחיקה להישג, בשתי הדרכים על אותם נתונים.
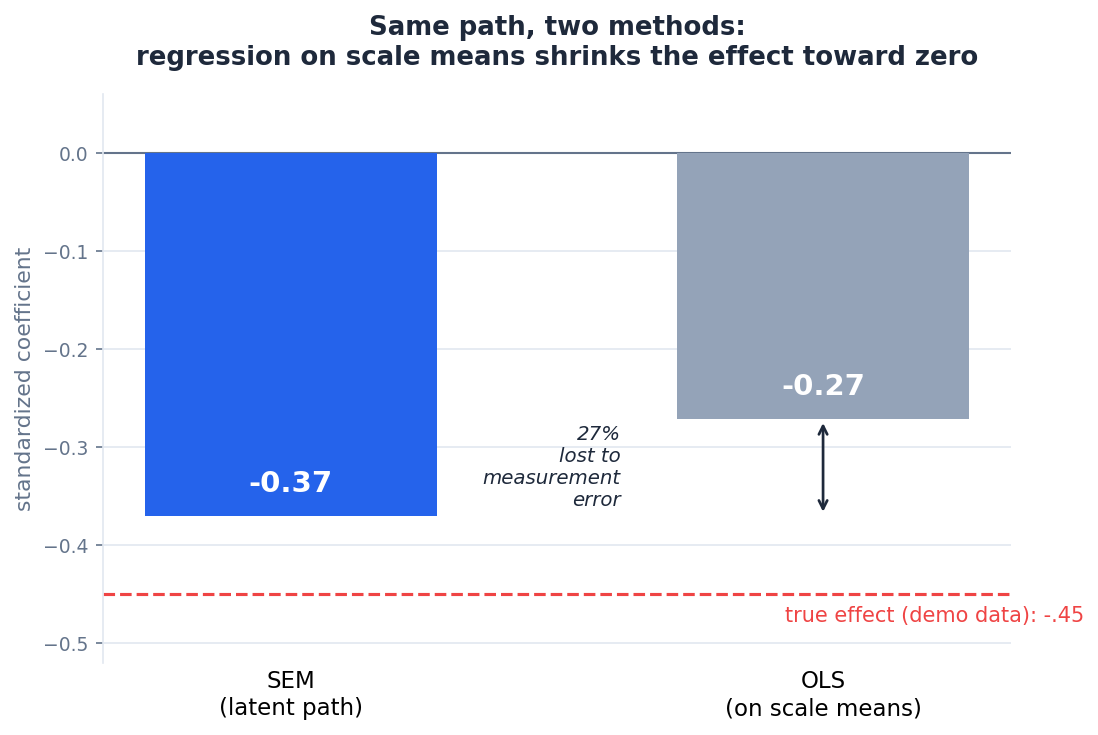
הרגרסיה על הממוצעים הניבה 0.27-. ה-SEM הניב 0.37-. כלומר האומדן של הרגרסיה נמוך בכ-27 אחוז מזה של ה-SEM, וזה לא במקרה. יש קירוב קלאסי שאומר שהקשר הנמדד שווה בערך לקשר האמיתי כפול שורש מכפלת שתי המהימנויות. מהימנות השחיקה אצלנו היא 0.73 ומהימנות ההישג 0.76, ושורש מכפלתן הוא 0.74. ובאמת, 0.37 כפול 0.74 נותן בערך 0.27. ההיחלשות לא רק נראית בגרף, היא קרובה מאוד למה שהקירוב חזה. זה הקירוב למקרה הפשוט של קשר בין שני סולמות. במודלים מורכבים יותר, עם כמה מנבאים או שגיאות מתואמות, גודל ההיחלשות תלוי גם במבנה הקשרים בין המשתנים.
זה ההבדל המעשי. שתי השיטות מסכימות שהקשר שלילי ומובהק, אבל הרגרסיה על הממוצעים מציגה אותו חלש ממה שהוא. אם בעבודה שלך גודל הקשר חשוב, ולא רק הסימן שלו, ההפרש הזה משנה את התמונה.
שלושה דברים שצריך לדעת לפני שמריצים
כמו תמיד, ההתלהבות מצריכה סייגים. שלושה הפעם, וכולם חשובים.
הראשון, SEM רעב לנתונים. הוא אומד הרבה פרמטרים בבת אחת, והאומדנים יציבים רק במדגם סביר. אין כאן כלל קסם אחד, כי זה תלוי במספר הפרמטרים, בגודל הטעינויות ובמורכבות המודל. בפועל מודלים בסיסיים כאלה מתחילים להיות יציבים סביב כמה מאות נבדקים, ופחות אמינים הרבה מתחת לזה. אם המדגם שלך הוא 60 איש, זה לא הכלי, ואין בושה לחזור לרגרסיה על הממוצעים ולציין את מגבלת המהימנות במשפט.
השני, והכי קל להיסחף בו. החצים בתרשים הם התאוריה שלך, לא תגלית של התוכנה. SEM בודק אם הכיוון שהנחת מתיישב עם הנתונים, אבל הוא לא מוכיח אותו. אפשר לעיתים להפוך את החץ, או להחליף בין סיבה לתוצאה, ולקבל התאמה דומה לחלוטין. כמו ב-CFA, התאמה טובה אומרת שהמודל לא נסתר, לא שהוא האמת היחידה. הסיבתיות מגיעה מהתכנון של המחקר ומהתאוריה, לא מהמספרים.
השלישי, הערה על הדוגמה. הנתונים פה הם הדגמה, ונולדו ממבנה ידוע שבו הקשר האמיתי הוא 0.45-. שימי לב שגם ה-SEM לא קלע אליו במדויק, הוא הניב 0.37-. גם הוא נתון לרעש דגימה. הוא לא קסם שמחזיר את האמת, הוא פשוט מנקה הטיה שיטתית אחת, את זאת של רעש המדידה, ולכן יוצא קרוב יותר. בנתוני אמת הכל פחות נקי, וצריך שיקול דעת, לא רק טבלת מקדמים.
איך כותבים את זה בפרק השיטות
כמו תמיד, כל המסע מתכווץ לכמה שורות. קודם המודל, אחר כך ההתאמה, ובסוף הנתיבים.
נבחן מודל משוואות מבניות (SEM) שבו עומס בעבודה מנבא שחיקה רגשית, ושחיקה רגשית מנבאת תחושת הישג מקצועי, כאשר שלושת המשתנים מיוצגים כגורמים חבויים. המודל הראה התאמה טובה לנתונים: χ²(25) = 30.40, p = .21, CFI = .99, TLI = .99, RMSEA = .02, 90% CI [.00, .05], SRMR = .03. הנתיב המבני משחיקה רגשית לתחושת הישג היה שלילי ומובהק (β = .37-, p < .001), וכן הנתיב מעומס לשחיקה (β = .44, p < .001).
יש שם את המודל, את מדדי ההתאמה שהבודק רוצה לראות, ואת המקדמים המבניים המתוקננים. אין הסבר מה זה RMSEA, ואין התנצלות.
וכאן אנחנו קושרים את החוט שהתחלנו למתוח לפני כמה פוסטים. בניתוח הגורמים החוקר שאלנו כמה ממדים יש בשאלון. ב-CFA בדקנו אם מבנה שהנחנו מתאים לנתונים. ועכשיו, ב-SEM, חיברנו בין הגורמים בחיצים מכוונים ושאלנו על הקשר ביניהם, בלי לתת לרעש המדידה לבלוע אותו. זאת הקומה העליונה של מדידת המשתנים החבויים, ועכשיו את כבר מכירה אותה.